llama3

全网首曝!用 C# 调用本地大模型:Llama3 中文对话实战
在人工智能蓬勃发展的当下,大模型技术已成为众多领域的核心驱动力。 Llama3作为Meta开发并公开发布的最新大型语言模型(LLMs),凭借其卓越的性能和丰富的功能,备受开发者关注。 以往,调用大模型往往依赖云端服务,面临着网络延迟、数据隐私等诸多问题。

加速 AI 布局!Meta 寻求收购AI芯片公司 FuriosaAI
据《福布斯》报道,Meta(前称 Facebook)正在积极洽谈收购一家名为 FuriosaAI 的韩国芯片初创公司。 此举旨在增强 Meta 的人工智能硬件基础设施,以应对日益增长的 AI 需求。 FuriosaAI 由多位前三星和 AMD 员工创办,专注于开发能够加速人工智能模型运行的芯片,适用于 Meta 的文本生成模型,如 Llama2和 Llama3等。

浪潮信息发布源 2.0-M32 大模型 4bit / 8bit 量化版:运行显存仅需 23GB,号称性能媲美 LLaMA3
浪潮信息今日发布源 2.0-M32 大模型 4bit 和 8bit 量化版,性能号称“比肩 700 亿参数的 LLaMA3 开源大模型”。4bit 量化版推理运行显存仅需 23.27GB,处理每 token 所需算力约为 1.9 GFLOPs,算力消耗仅为同等当量大模型 LLaMA3-70B 的 1/80。而 LLaMA3-70B 运行显存为 160GB,所需算力为 140GFLOPs。据浪潮信息介绍,源 2.0-M32 量化版是“源”大模型团队为进一步提高模算效率,降低大模型部署运行的计算资源要求而推出的版本,将

斯坦福团队为抄袭清华系面壁智能 AI 模型道歉:Llama3-V 模型将悉数撤下
近日斯坦福大学的 AI 研究团队的 Llama3-V 开源模型被指控抄袭了清华系明星创业公司面壁智能开发的开源模型“小钢炮”MiniCPM-Llama3-V 2.5,在网上引起热议。图源 Pexels5 月 29 日一个斯坦福 AI 团队在网上宣称只需 500 美元就可训练出一个超越 GPT-4V 的 SOTA 多模态大模型,但很快网友就发现该项目使用的模型结构和代码与“小钢炮”高度相似,仅有部分变量名被更改。面壁智能团队在 6 月 2 日深夜确认,斯坦福的模型不仅能识别出“清华简”中的战国古文字,而且连错误的识别

斯坦福团队被曝抄袭清华系大模型,已删库跑路,创始人回应:也算国际认可
斯坦福 AI 团队,竟然曝出了抄袭事件,而且抄袭的还是中国国产的大模型成果 —— 模型结构和代码,几乎一模一样!跟任何抄袭事故一样……AI 圈内都惊呆了。斯坦福的这项研究叫做 Llama3-V,是于 5 月 29 日新鲜发布,宣称只需要 500 美元就能训出一个 SOTA 多模态大模型,比 GPT-4V、Gemini Ultra、Claude Opus 都强。Llama3-V 的 3 位作者或许是拥有名校头衔加持,又有特斯拉、SpaceX 的大厂相关背景,这个项目短短几天就受到了不小的关注。甚至一度冲上了 Hugg

面壁智能推出 MiniCPM-Llama3-V 2.5 开源端侧多模态模型:8B 参数、高效部署手机
感谢面壁智能昨晚推出并开源 MiniCPM 系列最新的端侧多模态模型 MiniCPM-Llama3-V 2.5,支持 30 种语言,宣称可实现:最强端侧多模态综合性能:超越 Gemini Pro 、GPT-4VOCR 能力 SOTA(IT之家注:State-of-the-Art):9 倍像素更清晰,难图长图长文本精准识别图像编码快 150 倍:首次端侧系统级多模态加速▲ OpenCompass 模型量级对比MiniCPM-Llama3-V 2.5 总参数量为 8B,多模态综合性能超越 GPT-4V-1106、Ge
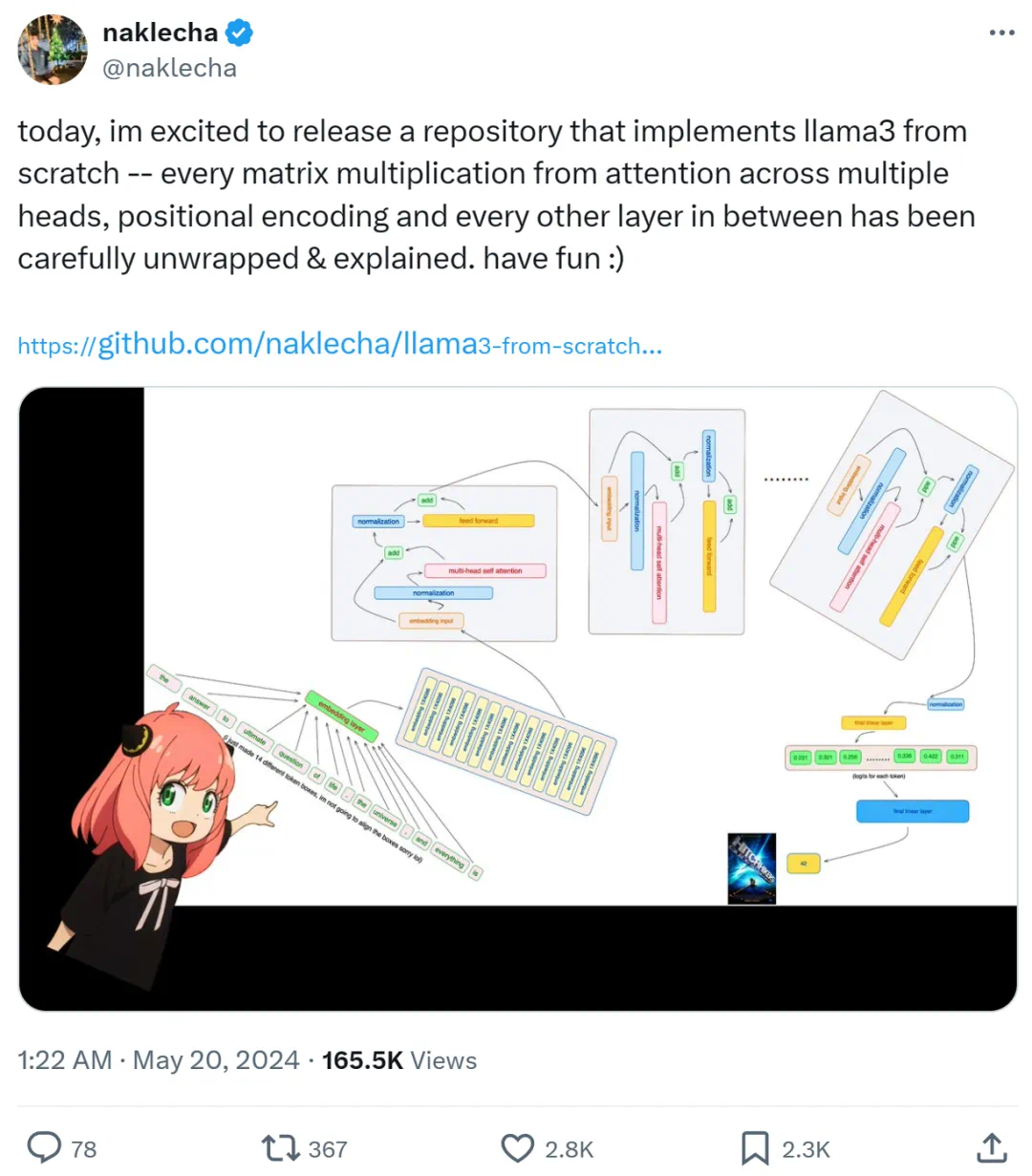
Karpathy称赞,从零实现LLaMa3项目爆火,半天1.5k star
项目中代码很多很全,值得细读。一个月前,Meta 发布了开源大模型 llama3 系列,在多个关键基准测试中优于业界 SOTA 模型,并在代码生成任务上全面领先。此后,开发者们便开始了本地部署和实现,比如 llama3 的中文实现、llama3 的纯 NumPy 实现等。十几个小时前,有位名为「Nishant Aklecha」的开发者发布了一个从零开始实现 llama3 的存储库,包括跨多个头的注意力矩阵乘法、位置编码和每个层在内都有非常详细的解释。该项目得到了大神 Karpathy 的称赞,他表示项目看起来不错,
70B 模型秒出 1000token,代码重写超越 GPT-4o,来自 OpenAI 投资的代码神器 Cursor 团队
70B 模型,秒出 1000token,换算成字符接近 4000!研究人员将 Llama3 进行了微调并引入加速算法,和原生版本相比,速度足足快出了快了 13 倍!不仅是快,在代码重写任务上的表现甚至超越了 GPT-4o。这项成果,来自爆火的 AI 编程神器 Cursor 背后团队 anysphere,OpenAI 也参与过投资。要知道在以快著称的推理加速框架 Groq 上,70B Llama3 的推理速度也不过每秒 300 多 token。Cursor 这样的速度,可以说是实现了近乎即时的完整代码文件编辑。有人直
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉