扩散大语言模型

token危机解决?扩散模型数据潜力3倍于自回归,重训480次性能仍攀升
token 危机终于要不存在了吗? 近日,新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步。 在当前大语言模型(LLM)的持续发展中,面临的挑战之一是可用的高质量训练文本数据(tokens)即将枯竭,并成为限制模型性能持续提升的关键瓶颈。
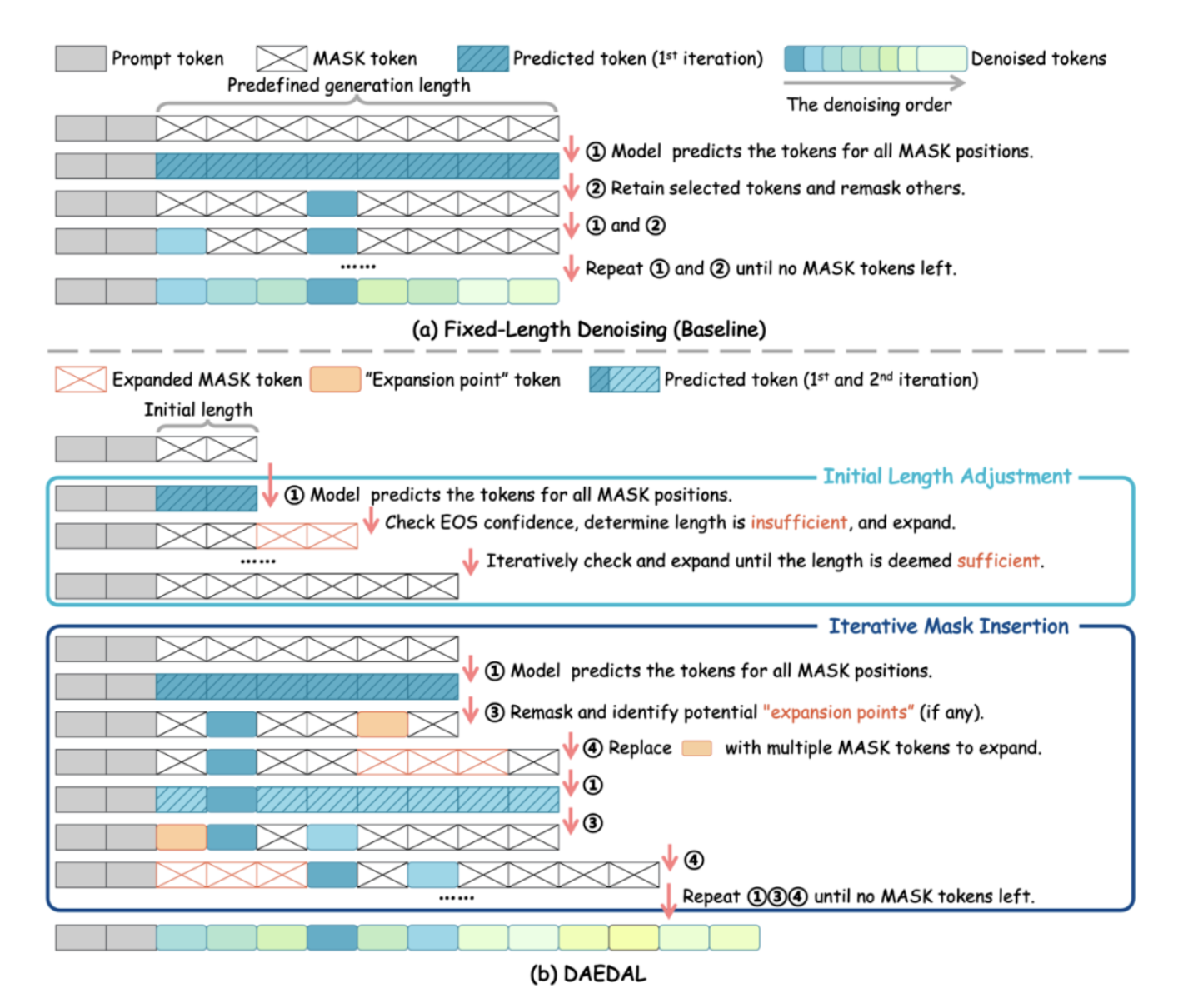
扩散LLM推理新范式:打破生成长度限制,实现动态自适应调节
随着 Gemini-Diffusion,Seed-Diffusion 等扩散大语言模型(DLLM)的发布,这一领域成为了工业界和学术界的热门方向。 但是,当前 DLLM 存在着在推理时必须采用预设固定长度的限制,对于不同任务都需要专门调整才能达到最优效果。 为了解决这一本质的问题,香港中文大学 MMLab,上海 AI 实验室等提出 DAEDAL,赋予 DLLM 可以根据问题的具体情况自主调整回答长度的能力,弥补了 DLLM 与自回归 LLM 的关键差距,为更灵活、高效、强大的扩散大语言模型打下了基石。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉