华中科技大学

MiniMax联合华中科大开源VTP技术!仅优化视觉分词器,DiT生成性能飙升65.8%
AI视觉生成领域迎来范式级突破。 MiniMax与华中科技大学近日联合开源其核心技术——VTP(Visual Tokenizer Pretraining,视觉分词器预训练),在不修改标准DiT(Diffusion Transformer)架构的前提下,仅通过优化视觉分词器(Visual Tokenizer),即实现65.8%的端到端图像生成性能提升。 这一成果颠覆了“唯有堆大模型才能提性能”的行业惯性,首次将视觉分词器推向前所未有的技术高度。

华中科大盛建中团队研发 AI 图像生成系统,协助警方令 19 名失踪儿童回家团圆
5月10日央视财经报道,华中科技大学盛建中团队研发视觉新生智能图像生成系统,利用AI预测失踪儿童面貌。该系统已协助警方寻回19名失踪儿童,还修复千张照片。##AI寻亲##
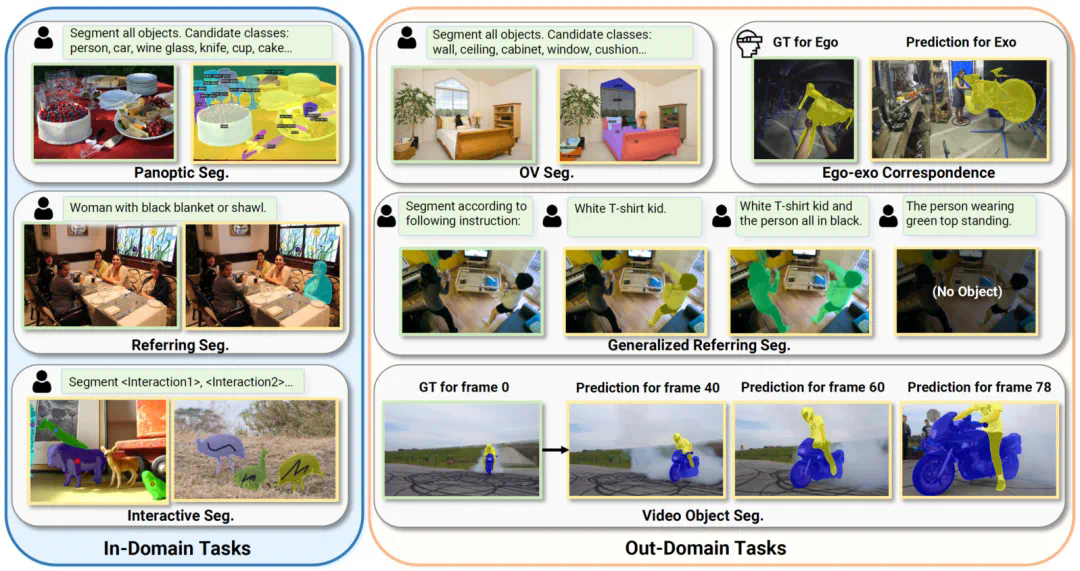
多模态大模型有了统一分割框架,华科PSALM多任务登顶,模型代码全开源
最近,多模态大模型(LMM)取得了一系列引人注目的成就,特别是在视觉 - 语言任务上的表现令人瞩目。它们的成功不仅展现了多模态大模型在各个领域的实用性和灵活性,也为更多视觉场景下的应用探索了新的道路。尽管如此,在将 LMM 应用到计算机视觉任务上时,我们仍面临一个关键挑战:大多数 LMM 目前只限于文本输出,这限制了它们在处理更细粒度的视觉任务,如图像分割方面的能力。此外,图像分割领域内部的需求多样化,任务各异 —— 实例分割需为每个对象分配唯一 ID 并计算类别信赖度,指代分割(RES)则需要基于描述性语句来识别

通用文档理解新SOTA,多模态大模型TextMonkey来了
最近,华中科技大学和金山的研究人员在多模态大模型 Monkey [1](Li et al., CVPR2024)工作的基础上提出 TextMonkey。在多个场景文本和文档的测试基准中,TextMonkey 处于国际领先地位,有潜力带来办公自动化、智慧教育、智慧金融等行业应用领域的技术变革。论文链接:: 是一个专注于文本相关任务(包括文档问答和场景文本问答)的多模态大模型(LMM)。相比于 Monkey,TextMonkey 在多个方面进行改进:通过采用零初始化的 Shifted Window Attention,
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉