HealthBench

OpenAI 发布健康领域 AI 评估基准数据集HealthBench
OpenAI 正式发布了一个大型数据集,旨在评估大型语言模型在医疗健康领域回答问题的能力。 这一项目被命名为 HealthBench,专家们对这一开源数据和详细的评估标准给予了高度赞誉,称其在规模和广度上都是 “前所未有” 的。 图源备注:图片由AI生成,图片授权服务商MidjourneyHealthBench 项目标志着 OpenAI 在医疗健康领域的首次尝试,尤其是在不依赖外部合作伙伴的情况下进行的创新探索。
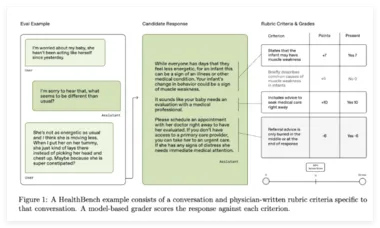
OpenAI 发布 HealthBench:评估大型语言模型在医疗领域表现的新标准
近日,OpenAI 发布了一款名为 HealthBench 的开源评估框架,旨在测量大型语言模型(LLMs)在真实医疗场景中的表现和安全性。 此框架的开发得到了来自60个国家和26个医学专业的262名医生的支持,旨在弥补现有评估标准的不足,特别是在真实应用、专家验证和诊断覆盖方面。 现有的医疗 AI 评估标准通常依赖于狭窄、结构化的形式,如多项选择考试。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉