高考

五款大模型考「山东卷」,Gemini、豆包分别获文理第一名
果然,高考已经快被 AI 攻克了。 近日,5 款大模型参加了今年山东高考,按照传统的文理分科方式统计:豆包 Seed 1.6-Thinking 模型以 683 分的成绩拿下文科第一,Gemini 2.5 Pro 则凭借 655 分拔得理科头筹。 测评来自字节跳动 Seed 团队。

北京多部门联合开展 AI 填报高考志愿功能专项合规指导
据北京市网信办消息,为切实维护考生合法权益,提升高考志愿填报的科学性与精准度,北京市网信办联合市教委、市市场监管局等部门,针对提供 AI 填报高考志愿服务的大模型企业开展专项合规指导,全力保障高考志愿填报工作平稳有序推进。

中国电信揭秘高考 AI 智慧巡考平台:自动标记可疑动作,服务考生超百万
过去,传统人力监考不仅难辨证件真伪,还易因视线盲区漏掉细微作弊动作。如今,中国电信运用人脸识别与 AI 分析等技术,构建数字化入场安检数据与考生异常行为监测一体化平台,化身“六边形 AI 监考官”,有效防止考试作弊,维护考试公正性。

六大模型决战高考数学新一卷:豆包、元宝并列第一,OpenAI o3竟惨败垫底
又是一年高考时。 这届考生上午刚经历了抽象作文的洗礼,下午又被数学无情创飞。 考试一结束,「高考数学」、「新一卷数学大题 难」等词条就火速冲上微博热搜,考生们在评论区集体「哀嚎」:「大题写到怀疑人生」、「选择填空送分,大题送命」。
2025 高考临近“AI 大模型押题卷”火热,央视网提醒考生应独立思考避免过度依赖
2025高考临近,“AI大模型押题卷”火热,标价高昂。央视网盘点发现其“押中”标准宽泛。教师提醒考生别依赖押题卷,可利用AI辅助复习,但要避免过度依赖,独立思考。#高考AI押题卷#
QQ浏览器上线行业内首个高考Agent“AI高考通”
2025年5月23日,QQ浏览器正式上线了行业内首个高考Agent——“AI高考通”,为高考生提供了一个超级高考助手。 这一创新工具旨在通过AI技术全流程助力高考,为考生提供全面且权威的高考信息,并量身定制志愿填报方案。 “AI高考通”不仅能够帮助考生在考前通过“AI解题答疑”和“AI作文辅导”打开解题和写作思路,还能在考试期间快速查询高考日程,解答考生的各种疑惑,如“忘带准考证怎么办?”或“感觉没发挥好怎么办?”考后,它还能为考生提供个性化推荐志愿,帮助考生了解院校专业信息,选择合适的院校。

通义千问、GPT-4o 等七款 AI 大模型“高考成绩”公布 :前三名文科过一本,理科过二本
感谢上海人工智能实验室 17 日公布了针对 7 个 AI 大模型的高考全科目测试结果,据大模型开源开放评测体系“司南”相关负责人介绍,“当前大模型仍存在很大的局限性。组织 AI 大模型‘参加高考’,目的是评测当前大模型的真实水平,找准问题,持续推进技术进步。”测试结果显示,书生・浦语 2.0 系列文曲星大模型(浦语文曲星)、阿里通义千问大模型 Qwen2-72B 以及 GPT-4o 再次包揽文、理科前三甲;前三名 AI“考生”的文、理科成绩分别超过了“一本”“二本”线(以今年高考人数最多的河南省的分数线为参考)。从

上海人工智能实验室发布首个 AI 高考评测结果:语数英总分最高 303 分,数学全部不及格
感谢上海人工智能实验室 19 日公布了首个 AI 高考全卷评测结果。据介绍,2024 年全国高考甫一结束,该实验室旗下司南评测体系 OpenCompass 选取 6 个开源模型及 GPT-4o 进行高考“语数外”全卷能力测试。评测采用全国新课标 I 卷,参与评测的所有开源模型开源时间均早于高考,确保评测“闭卷”性。同时,成绩由具有高考评卷经验的教师人工评判,更加接近真实阅卷标准。该机构表示,Qwen2-72B、GPT-4o 及书生・浦语 2.0 文曲星(InternLM2-20B-WQX)成为本次大模型高考的前三甲
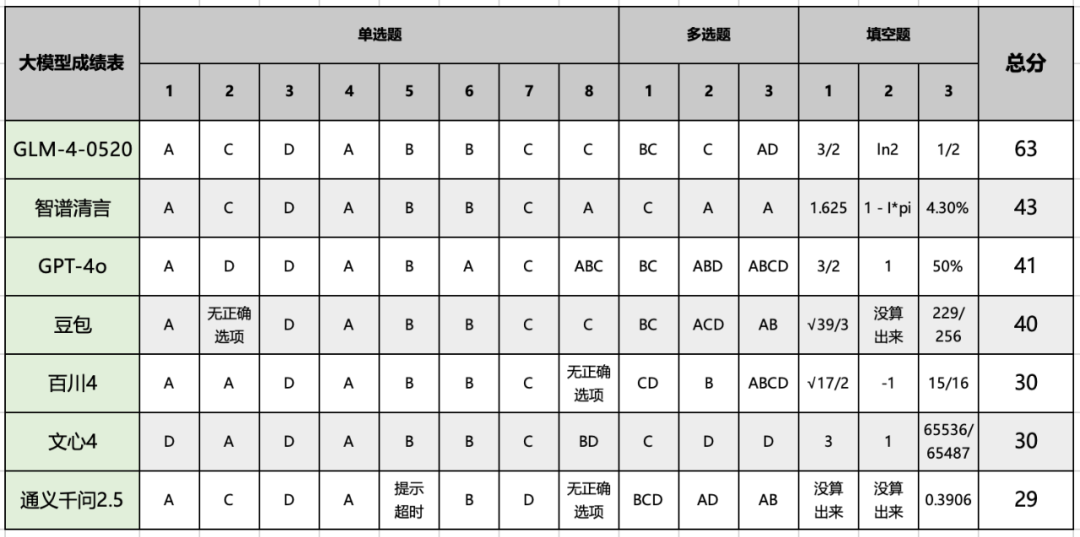
大模型的高考数学成绩单:及格已经非常好了
让考生头皮发麻的高考数学,可难倒了顶尖 AI 大模型。一年一度的高考即将落幕,衷心希望各位考生都超常发挥,考出满意的好成绩!!和往年一样,除了让 AI 大模型写写高考作文,我们也选取了六家国内头部大模型公司的产品与考生们一同参与一场客观且公平(让众多考生头皮发麻)的高考数学考试(新课标 Ⅰ 卷),其中包括 GPT-4o、GLM-4、文心一言 4.0、豆包、百小应(百川 4)以及通义千问 2.5。先来瞧一瞧这份「大模型成绩单」:令人惊讶的是,在这次模拟考试中,大模型(产品)的表现并未达到预期,甚至出现了几乎全部不及格
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉