FishAudio

Fish Audio 推出 S1 语音克隆模型升级:10 秒即可复刻真人语音
【AIbase 报道】语音生成公司 Fish Audio 正式发布升级版 S1语音克隆模型,在情感表现力与拟真度方面实现重大突破。 新版模型能够生成富有情绪、节奏感与语气变化的真人级声音,几乎可以完美再现人类说话时的细微差别。 据介绍,用户只需提供约 10秒的语音样本,S1即可克隆任意人声,并完整保留原声的口音、语调与节奏,还原个人的说话习惯与情感特征,生成效果几乎与真人无异。
10/21/2025 11:56:54 AM
AI在线
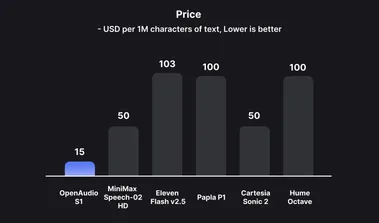
OpenAudio 发布开源 TTS 模型 S1-Mini:0.5B 参数打造超自然 AI 语音
AI 语音技术领域迎来重要进展,Fish Audio 宣布开源其全新文本转语音(TTS)模型 OpenAudio S1-Mini。 作为广受好评的 S1模型的精简版,S1-Mini 以其轻量化设计、高表现力和多语言支持引发行业热议。 技术亮点:轻量化与高性能兼得OpenAudio S1-Mini 是从4B 参数的 S1模型蒸馏而来的轻量化版本,仅包含0.5B 参数,大幅降低计算需求,适合在资源受限的环境中部署,如边缘设备或本地化应用。
6/6/2025 3:01:06 PM
AI在线

Fish Audio发布OpenAudio S1:媲美专业配音演员的AI语音新标杆
Fish Audio正式推出其最新一代语音生成模型——OpenAudio S1,以其高度自然的声音、丰富的语气控制和强大的指令跟随能力,号称达到专业配音演员的表现力和自然度。 这一模型在TTS-Arena排行榜中荣登第一,成为文本转语音(TTS)领域的新标杆。 AIbase为您深入解析OpenAudio S1的突破性功能及其潜在影响。
6/4/2025 10:01:25 AM
AI在线
- 1
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
DeepSeek
谷歌
AI绘画
机器人
大模型
数据
Midjourney
开源
Meta
智能
微软
用户
AI新词
GPT
学习
技术
智能体
马斯克
Gemini
图像
Anthropic
英伟达
AI创作
训练
LLM
论文
代码
算法
Agent
AI for Science
芯片
苹果
腾讯
Stable Diffusion
Claude
蛋白质
开发者
生成式
神经网络
xAI
机器学习
3D
RAG
人形机器人
研究
AI视频
生成
大语言模型
具身智能
Sora
工具
GPU
百度
华为
计算
字节跳动
AI设计
AGI
大型语言模型
搜索
视频生成
场景
深度学习
DeepMind
架构
生成式AI
编程
视觉
Transformer
预测
AI模型
伟达
亚马逊
MCP