翻译模型
腾讯混元发布1.5版开源翻译模型:端侧部署性能跃升,效果比肩超大型闭源模型
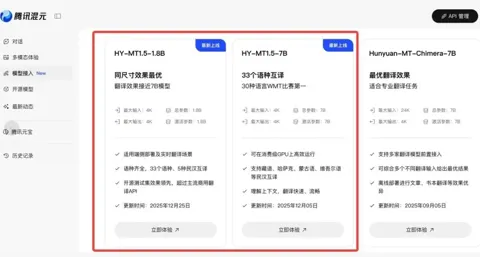
腾讯混元今日宣布正式开源其翻译模型1.5版本。 本次更新共包含两个不同尺寸的模型:Tencent-HY-MT1.5-1.8B 和 Tencent-HY-MT1.5-7B,旨在通过极致的效率与领先的翻译质量,重新定义端云协同的翻译体验。 核心亮点:端侧部署与卓越性能本次发布的 1.8B 模型 表现尤为亮眼。

腾讯混元开源翻译模型 1.5:手机 1GB 内存即可运行,效果超越商用 API
AI在线 12 月 30 日消息,腾讯混元今日宣布开源翻译模型 1.5 版本,共包含两个模型:Tencent-HY-MT1.5-1.8B 和 Tencent-HY-MT1.5-7B,支持 33 个语种互译以及 5 种民汉 / 方言,除了中文、英语、日语等常见语种,也包含捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种。 目前两个模型均已在腾讯混元官网上线,在 Github 和 Huggingface 等开源社区也可直接下载使用。 HY-MT1.5-1.8B 主要面向手机等消费级设备场景,经过量化,支持端侧直接部署和离线实时翻译,仅需 1GB 内存即可流畅运行,并且宣称在参数量极小的前提下,效果超过了大部分商用翻译 API。

NLLB 与 ChatGPT 双向优化:探索翻译模型与语言模型在小语种应用的融合策略
本文探讨了 NLLB 翻译模型与 ChatGPT 在小语种应用中的双向优化策略。 首先介绍了 NLLB-200 的背景、数据、分词器和模型,以及其与 LLM(Large Language Model)的异同和协同关系。 接着列举了实战与应用的案例,包括使用 ChatGPT 生成的样本微调 NLLB-200 和使用 NLLB-200 的翻译结果作为 LLM 的 prompt 等。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉