定位
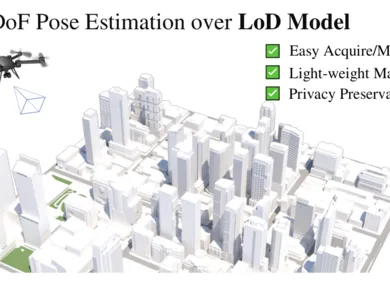
LoD-Loc:利用城市白模进行无人机六自由度定位!
论文信息论⽂全称:LoD-Loc: Aerial Visual Localization using LoD 3D Map with Neural Wireframe Alignment录⽤会议:NeurIPS 2024论⽂地址::: 基于三维城市⽩模地图(LoD 3D Map) 的⼀种使⽤神经线框对⻬进⾏空中视觉定位的新⽅法论⽂概要:LoD-Loc 基于城市⽩模模型Level of Detail 3D Map (LoD 3D Map)提出⼀种城市⽆⼈机空中定位新范式。 区别于基于SfM / SLAM / Mesh等复杂三维地图的传统定位⽅法 ,LoD 三维地图具有储存容量低 ,能提供隐私保护等优点。然⽽ , 由于 LoD 地图缺乏纹理,使⽤之前传统定位基线进⾏ LoD 地图空中定位并不简单。

港大字节提出多模态大模型新范式,模拟人类先感知后认知,精确定位图中物体
当前,多模态大模型 (MLLM)在多项视觉任务上展现出了强大的认知理解能力。然而大部分多模态大模型局限于单向的图像理解,难以将理解的内容映射回图像上。比如,模型能轻易说出图中有哪些物体,但无法将物体在图中准确标识出来。定位能力的缺失直接限制了多模态大模型在图像编辑,自动驾驶,机器人控制等下游领域的应用。针对这一问题,港大和字节跳动商业化团队的研究人员提出了一种新范式 Groma——通过区域性图像编码来提升多模态大模型的感知定位能力。在融入定位后,Groma 可以将文本内容和图像区域直接关联起来,从而显著提升对话的交

美图携手ACM Multimedia 2022举办第四届PIC竞赛 聚焦美妆场景
2022年7月1日,美图影像研究院(MT Lab)联合北京航天航空大学、中国人民大学在ACM国际多媒体会议(ACM International Conference on Multimedia, ACM MM)上主办的第四届Person in Context(PIC)竞赛圆满收官。 此次PIC竞赛因其前沿性和实用性吸引了来自清华大学、北京大学、上海交通大学、香港大学、中国科学技术大学等知名高校,以及腾讯、京东、小米、bilibili等知名企业共58支队伍报名参赛,参赛人数再创新高。竞赛共分设三个赛道,涵盖视频内容时

CVPR2022 | 利用域自适应思想,北大、字节跳动提出新型弱监督物体定位框架
将弱监督物体定位看作图像与像素特征域间的域自适应任务,北大、字节跳动提出新框架显著增强基于图像级标签的弱监督图像定位性能
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉