Diffusion

自回归模型杀回图像生成!实现像素级精准控制,比Diffusion更高效可控
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。 在精确视觉控制、平衡多模态输入以及高昂的训练成本方面仍面临挑战。 有没有一种更高效、控制更精准的范式?

Diffusion-SS3D:用扩散去噪革新半监督3D检测,伪标签更准,mAP提升6%!
一眼概览SemCity 是一种 基于三平面扩散(Triplane Diffusion) 的 3D 语义场景生成模型,能够在 真实户外环境 中进行 场景生成、语义补全、场景扩展(Outpainting)和修补(Inpainting),并在 SemanticKITTI 数据集 上显著提升生成质量。 核心问题背景问题:当前 3D 扩散模型大多专注于 单个物体 或 室内合成场景,对于 真实户外场景 仍然缺乏研究。 此外,户外数据由于传感器局限性(空白区域较多),导致模型难以学习 完整的三维语义分布。

开源文生图 AI 重磅选手上新:Stable Diffusion 3.5 最强全家桶登场、消费级硬件上“开箱即用”
Stability AI 公司昨日(10 月 22 日)发布博文,宣布推出 Stable Diffusion 3.5,这标志着开源 AI 文生图模型的重大进步。Stable Diffusion 3.5 共有 Medium(10 月 29 日发布)、Large 和 Large Turbo 三种规模版本,旨在满足科学研究人员、爱好者、初创公司和企业的不同需求,AI在线附上相关介绍如下:Stable Diffusion 3.5 Large:共有 80 亿个参数,具有卓越的质量和快速响应,是 Stable Diffusion 家族中最强大的模型,非常适合 100 万像素分辨率的专业应用场景。Stable Diffusion 3.5 Large Turbo:是 Large 的精简版,在出色地遵循提示词上,仅需 4 个步骤内生成高质量图像,且生成速度明显快于 Large。

新恐怖谷:全球 500 万网友被骗,爆火 TEDx 演讲者没一个是真人
最近,这几位 TED 演讲者,在外网形成了病毒式传播,然而,他们竟然全都不是真人?!答案揭晓后,五百万网友简直惊掉下巴。这 5 张图里,你能发现几个 bug?最近,这些「TED 演讲者」在外网火得一塌糊涂,堪称病毒式传播。仔细看看,你能发现什么问题吗?答案揭晓 —— 这五个人中,没有一个是真人!在线寻人的小哥要哭了如此逼真,几乎毫无破绽,这种级别的生图 AI 直接让网友们惊掉下巴。甚至连 AI 识别软件,都认不出来这是 AI 生成的图。「看起来真实,难道不是因为本来就是真实的照片?」「没有一张是真人吗?简直令人毛骨
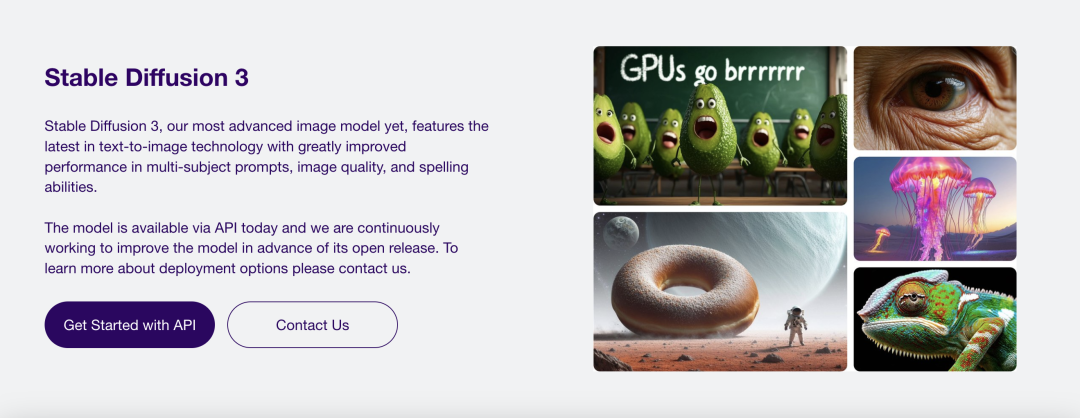
快速入门大模型技术与应用,推荐你从Stable Diffusion开始学起
自 2023 年 AI 技术爆发以来,以 ChatGPT、Stable Diffusion 为代表的大模型已然成为了大众的焦点,其中 Stable Diffusion 作为知名的视觉开源模型,凭借直观易用与令人印象深刻的图像生成能力,赢得了创作者的广泛青睐。随着人工智能技术的不断进步和创新,Stable Diffusion 已经在艺术创作、设计领域乃至科学研究中展现出了独特的魅力和巨大的潜力。它不仅能够在短时间内生成高分辨率、细节丰富的图像,还能够通过简单的文本描述实现复杂视觉内容的创造,这使得 Stable Di

值得你花时间看的扩散模型教程,来自普渡大学
Diffusion 不仅可以更好地模仿,而且可以进行「创作」。扩散模型(Diffusion Model)是图像生成模型的一种。有别于此前 AI 领域大名鼎鼎的 GAN、VAE 等算法,扩散模型另辟蹊径,其主要思想是一种先对图像增加噪声,再逐步去噪的过程,其中如何去噪还原图像是算法的核心部分。而它的最终算法能够从一张随机的噪声图像中生成图像。近年来,生成式 AI 的惊人增长为文本到图像生成、视频生成领域等许多令人兴奋的应用提供了支持。这些生成工具背后的基本原理是扩散的概念,这是一种特殊的采样机制,克服了以前的方法中被

麻省理工学院携手 Adobe 演示 DMD AI 技术:每秒可生成 20 幅图像
主流文生图模型固然已经能生成非常逼真的图片,但通常渲染时间非常缓慢。麻省理工学院携手 Adobe 公司近日研发了 DMD 方法,在尽量不影响图像质量的情况下,加快图像生成速度。DMD 技术的全称是 Distribution Matching Distillation,将多步扩散模型简化为一步图像生成解决方案。团队表示:“我们的核心理念是训练两个扩散(diffusion)模型,不仅能预估目标真实分布(real distribution)的得分函数,还能估计假分布(fake distribution)的得分函数。”研究

谷歌推出多模态 VLOGGER AI:让静态肖像图动起来“说话”
谷歌近日在 GitHub 页面发布博文,介绍了 VLOGGER AI 模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”,富有面部表情地朗读音频内容。VLOGGER AI 是一种适用于虚拟肖像的多模态 Diffusion 模型,使用 MENTOR 数据库进行训练,该数据库中包含超过 80 万名人物肖像,以及累计超过 2200 小时的影片,从而让 VLOGGER 生成不同种族、不同年龄、不同穿着、不同姿势的肖像影片。研究人员表示:“和此前的多模态相比,VLOGGER 的优势在于不需要对每个

谷歌下场优化扩散模型,三星手机运行Stable Diffusion,12秒内出图
Speed Is All You Need:谷歌提出针对 Stable Diffusion 一些优化建议,生成图片速度快速提升。Stable Diffusion 在图像生成领域的知名度不亚于对话大模型中的 ChatGPT。其能够在几十秒内为任何给定的输入文本创建逼真图像。由于 Stable Diffusion 的参数量超过 10 亿,并且由于设备上的计算和内存资源有限,因而这种模型主要运行在云端。在没有精心设计和实施的情况下,在设备上运行这些模型可能会导致延迟增加,这是由于迭代降噪过程和内存消耗过多造成的。如何在设

平息画师怒火:Stable Diffusion学会在绘画中直接「擦除」侵权概念
Stable Diffusion 学会了「偷天换日」的本领。
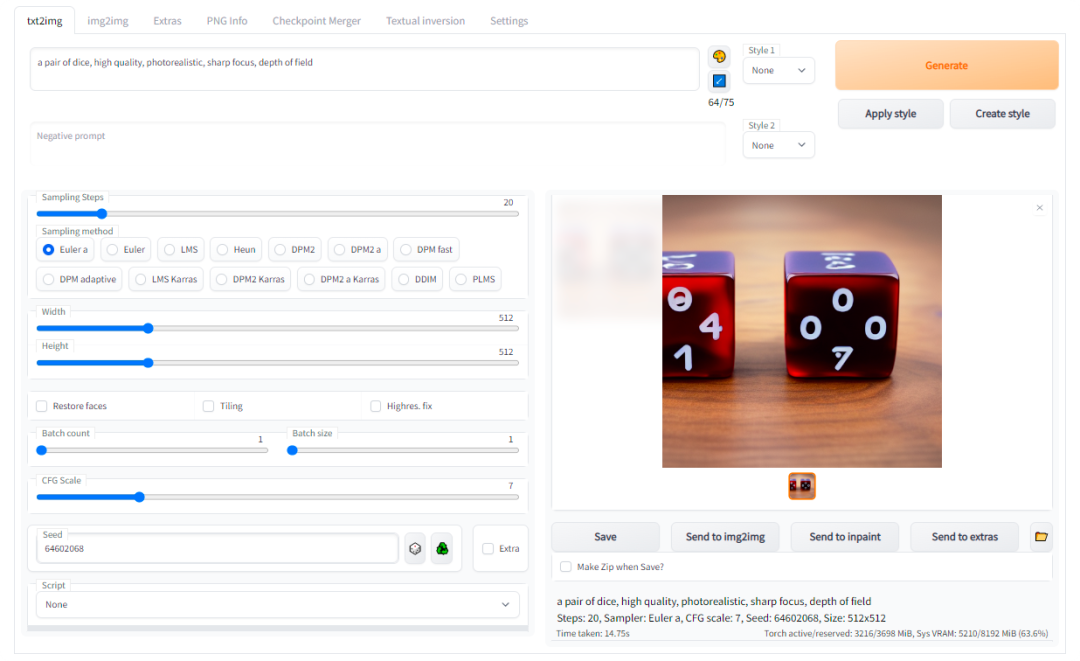
PS上的开源Stable Diffusion插件来了:一键AI脑补,即装即用
网友:「它能颠覆整个行业。」

Stable Diffusion的魅力:苹果亲自下场优化,iPad、Mac上快速出图
输入一句话就能生成图像的 Stable Diffusion 已经火爆数月。它是一个开源模型,而且在消费级 GPU 上就能运行,是一项普通人就能接触到的「黑科技」。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉