cpu

外国小哥徒手改装消费级5090,一举击败巨无霸RTX Pro 6000
一块经过 shunt mod 改装的华硕 ROG Astral LC RTX 5090 的性能,超越了售价 10,000 美元的 RTX Pro 6000。 「Shunt Mod」 是一种硬件级别的、具有高风险性的电路改装方法,主要用于绕过电子设备(特别是高性能显卡和主板)内置的功耗(功率)和电流限制。 这项惊人的成果来自硬件改装大师 Der8auer(本名 Roman Hartung)。

微软开源 1.58bit 推理框架:千亿参数模型量化后单 CPU 可跑,速度每秒 5-7 个 token
微软开源 1bit 大模型推理框架!现在 1000 亿参数大模型量化后单 CPU 可跑,速度可达每秒 5-7 个 token。比如在苹果 M2 新品上运行 BitNet b1.58 3B 模型,be like:就是今年爆火论文 The Era of 1-bit LLMs 的官方代码实现,开源不到一周 GitHub 已揽获 7.9k Star。

微软开源 bitnet.cpp 1-bit LLM 推理框架:不靠 GPU 可本地运行千亿参数 AI 模型,能耗最多降低 82.2%
科技媒体 marktechpost 昨日(10 月 18 日)发布博文,报道称微软公司开源了 bitnet.cpp,这是一个能够直接在 CPU 上运行、超高效的 1-bit 大语言模型(LLM)推理框架。用户通过 bitnet.cpp 框架,不需要借助 GPU,也能在本地设备上运行具有 1000 亿参数的大语言模型,实现 6.17 倍的速度提升,且能耗可以降低 82.2%。传统大语言模型通常需要庞大的 GPU 基础设施和大量电力,导致部署和维护成本高昂,而小型企业和个人用户因缺乏先进硬件而难以接触这些技术,而 bitnet.cpp 框架通过降低硬件要求,吸引更多用户以更低的成本使用 AI 技术。

手机跑大模型提速 4-5 倍:微软亚研院开源新技术 T-MAC,有 CPU 就行
有 CPU 就能跑大模型,性能甚至超过 NPU / GPU!没错,为了优化模型端侧部署,微软亚洲研究院提出了一种新技术 —— T-MAC。这项技术主打性价比,不仅能让端侧模型跑得更快,而且资源消耗量更少。咋做到的??在 CPU 上高效部署低比特大语言模型一般来说,要想在手机、PC、树莓派等端侧设备上使用大语言模型,我们需要解决存储和计算问题。常见的方法是模型量化,即将模型的参数量化到较低的比特数,比如 4 比特、3 比特甚至更低,这样模型所需的存储空间和计算资源就会减少。不过这也意味着,在执行推理时,需要进行混合精

英伟达黄仁勋解读“CEO 数学”:花小钱,办大事
英伟达首席执行官黄仁勋日前在 2024 台北电脑展前夕提出了一个有趣的概念 ——“CEO 数学”。“买得越多,省得越多,” 黄仁勋在演讲中表示,“这就是 CEO 数学,它并不完全准确,但却很有效。”乍一听让人困惑?黄仁勋随后解释了这个概念的含义。他建议企业同时投资图形处理器 (GPU) 和中央处理器 (CPU)。这两种处理器可以协同工作,将任务完成时间从“100 个单位缩短到 1 个单位”。因此,从长远来看,增加投资反而能节省成本。这种结合使用 CPU 和 GPU 的做法在个人电脑领域已经很普遍。“我们往一台 10
4090成A100平替?上交大推出推理引擎PowerInfer,token生成速率只比A100低18%
机器之心报道机器之心编辑部PowerInfer 使得在消费级硬件上运行 AI 更加高效。上海交大团队,刚刚推出超强 CPU/GPU LLM 高速推理引擎 PowerInfer。项目地址::?在运行 Falcon (ReLU)-40B-FP16 的单个 RTX 4090 (24G) 上,PowerInfer 对比 llama.cpp 实现了 11 倍加速!PowerInfer 和 llama.cpp 都在相同的硬件上运行,并充分利用了 RTX 4090 上的 VRAM。在单个 NVIDIA RTX 4090 GPU

AMD 的下一代 GPU 是 3D 集成的超级芯片:MI300 将 13 块硅片组合为一个芯片
编辑 | 白菜叶AMD 在近日的 AMD Advancing AI 活动中揭开了其下一代 AI 加速器芯片 Instinct MI300 的面纱,这是前所未有的 3D 集成壮举。MI300 将为 El Capitan 超级计算机提供动力,它是一个集计算、内存和通信于一体的夹层蛋糕,有三片硅片高,可以在这些硅平面之间垂直传输多达 17 TB 的数据。它可以使某些机器学习关键计算的速度提高 3.4 倍。该芯片与 Nvidia 的 Grace-Hopper 超级芯片和英特尔的超级计算机加速器 Ponte Vecchio

专访AMD芯片架构师Sam Naffziger:Chiplet将如何影响芯片制造
这五年来,处理器领域发生的变化是深刻的,从单片硅芯片变成了小型 chiplet 的组合 —— 这些小型 chiplet 组合起来能像单片大芯片一样运作。
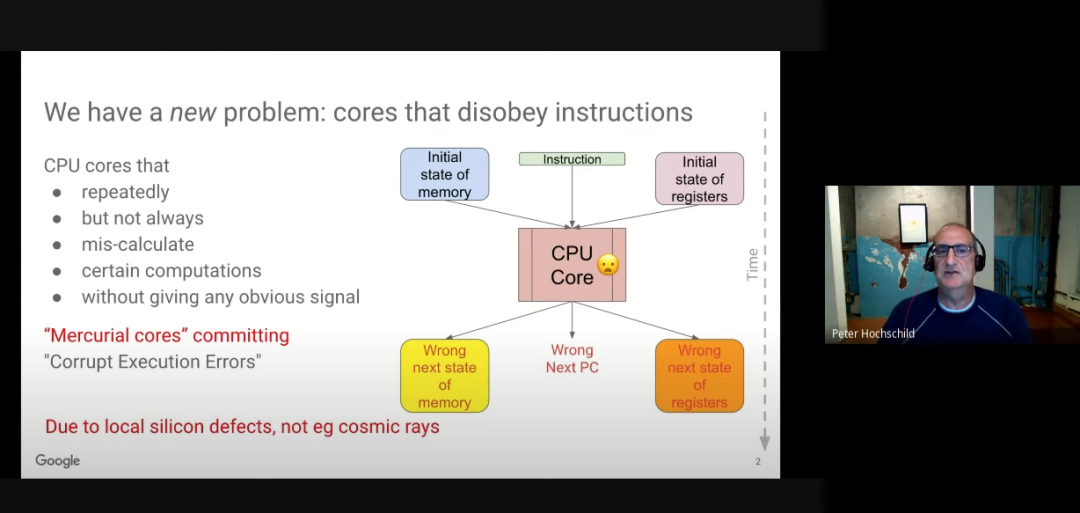
谷歌、Facebook频繁发现CPU内核不可靠,出现无法预测计算错误
最近谷歌和 Facebook 两大公司频繁检测到 CPU 在一些情况下会以无法预测的方式出现计算错误。
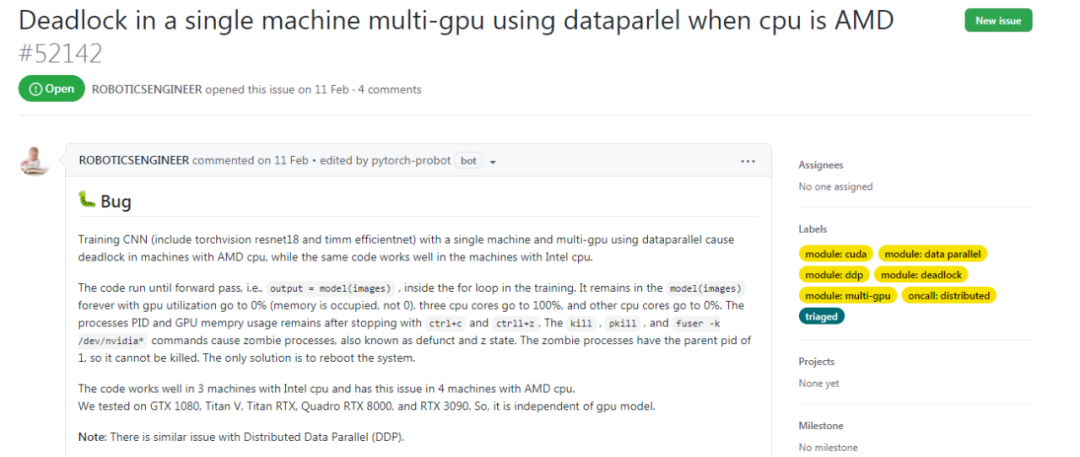
有bug!PyTorch在AMD CPU的计算机上卡死了
AMD,No?PyTorch在AMD CPU的机器上出现死锁了。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉