COAT

FP8训练新范式:减少40%显存占用,训练速度提高1.4倍
近期DeepSeek V3 引爆国内外的社交媒体,他们在训练中成功应用了 FP8 精度,显著降低了 GPU 内存使用和计算开销。 这表明,FP8 量化技术在优化大型模型训练方面正发挥着越来越重要的作用。 近期,来自伯克利,英伟达,MIT 和清华的研究者们提出了显存高效的 FP8 训练方法:COAT(Compressing Optimizer states and Activation for Memory-Efficient FP8 Training),致力于通过 FP8 量化来压缩优化器状态和激活值,从而提高内存利用率和训练速度。

CoAT: 基于蒙特卡洛树搜索和关联记忆的大模型推理能力优化框架
研究者提出了一种新的关联思维链(Chain-of-Associated-Thoughts, CoAT)方法,该方法通过整合蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)和关联记忆机制来提升大语言模型(LLMs)的推理能力。 区别于传统的单步推理方法,CoAT致力于增强LLM的结构化推理能力和自适应优化能力,实现动态知识整合。
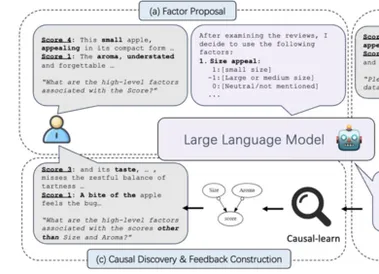
NeurIPS 2024 | 用LLM探寻隐秘的因果世界
因果发现的现实挑战:稀缺的高级变量寻找并分析因果关系是科学研究中的重要一环,而现有的因果发现算法依赖由专家预先定义的高级变量。 现实场景中的原始数据往往是图片、文本等高维非结构化数据, 结构化的高级变量是十分稀缺的,导致现有的因果发现和学习算法难以用于至更广泛的数据。 因此,香港浸会大学与MBZUAI、卡内基梅隆大学、香港中文大学、悉尼大学以及墨尔本大学合作发表论文《Discovery of the Hidden World with Large Language Models》,提出了一个名为 COAT 的新型框架,旨在利用大型语言模型和因果发现方法的优势,突破传统因果发现方法的局限性,更有效地在现实世界中定义高级变量、理解因果关系。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉