CLIP

模态编码器 | FLIP:通过图像掩码加速CLIP训练
来聊聊Meta AI团队(何恺明组)提出的一个高效的CLIP加速训练方法——FLIP。 看完MAE,很自然的一个想法就是将MAE用到CLIP里的图像编码器上,FLIP实现了这个想法,通过在训练过程中对图像进行随机掩码(masking),显著提升了训练效率。 动机也很简单,CLIP训练成本高,耗费大量时间和资源,高效省时的训练方法则成为研究重点。

模态编码器|CLIP技术改进之EVA-CLIP
上一篇看了EVA,趁热打铁,今天来看EVA-CLIP,同样是智源曹越团队的工作,主要研究主题是结合EVA改进CLIP。 研究动机:训练CLIP模型面临计算成本高和训练不稳定等挑战,尤其是在扩大模型规模时。 因此,这项工作的研究动机是提供一种高效且有效的解决方案,以促进更大规模CLIP模型的训练和发展。

模态编码器|CLIP详细解读
下面来详细了解一下多模态大模型模态编码器部分。 今天首先来看下CLIP,OpenAI发表在2021年ICML上的一篇工作。 项目地址::在自然语言处理(NLP)领域,通过大规模的文本数据预训练模型(如GPT-3)已经取得了显著的成果,但在计算机视觉领域,预训练模型仍然依赖于人工标注的图像数据集,严重影响了其在未见类别上的泛化性和可用性(需要用额外的有标注数据)。

LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
在人工智能迅速发展的今天,多模态系统正成为推动视觉语言任务前沿发展的关键。 CLIP(对比语言-图像预训练)作为其中的典范,通过将文本和视觉表示对齐到共享的特征空间,为图像-文本检索、分类和分割等任务带来了革命性突破。 然而其文本编码器的局限性使其在处理复杂长文本和多语言任务时显得力不从心。

CVPR 2024|FairCLIP:首个多模态医疗视觉语言大模型公平性研究
作者 | 哈佛大学、纽约大学团队编辑 | ScienceAI公平性在深度学习中是一个关键问题,尤其是在医疗领域,这些模型影响着诊断和治疗决策。尽管在仅限视觉领域已对公平性进行了研究,但由于缺乏用于研究公平性的医疗视觉-语言(VL)数据集,医疗VL模型的公平性仍未被探索。为了弥补这一研究空白,我们介绍了第一个公平的视觉-语言医疗数据集(FairVLMed),它提供了详细的人口统计属性、真实标签和临床笔记,以便深入检查VL基础模型中的公平性。使用FairVLMed,我们对两个广泛使用的VL模型(CLIP和BLIP2)进

后Sora时代,CV从业者如何选择模型?卷积还是ViT,监督学习还是CLIP范式
如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型?MBZUAI和Meta的研究者给出了答案。一直以来,ImageNet 准确率是评估模型性能的主要指标,也是它最初点燃了深度学习革命的火种。但对于今天的计算视觉领域来说,这一指标正变得越来越不「够用」。因为计算机视觉模型已变得越来越复杂,从早期的 ConvNets 到 Vision Transformers,可用模型的种类已大幅增加。同样,训练范式也从 ImageNet 上的监督训练发展到自监督学习和像 CLIP 这样的图像 - 文本对训练。ImageNet 并
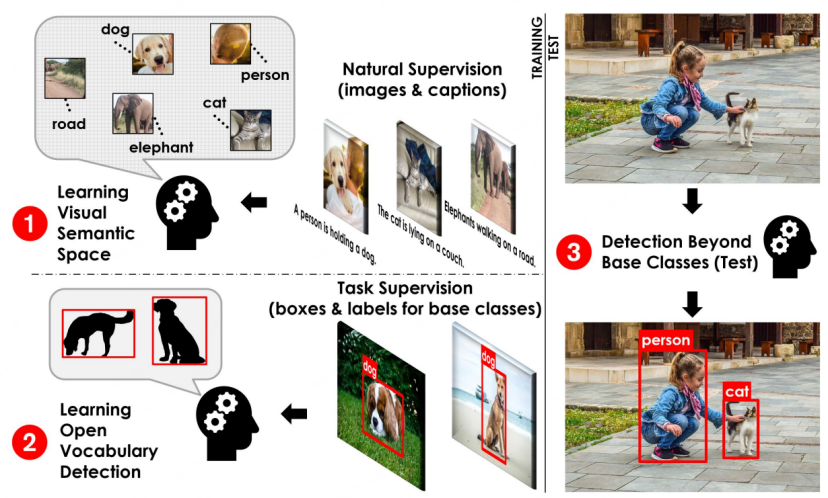
无需标注海量数据,目标检测新范式OVD让多模态AGI又前进一步
当下 OVD 领域的相关研究蓬勃发展,OVD 技术对未来通用 AI 大模型能够带来的改变值得期待。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉