北京大学

北大发布 ManualVLA:首个长程「生成–理解–动作」一体化模型,实现从最终状态自主生成说明书并完成操纵
视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。 针对这一问题,北京大学、香港中文大学与至简动力团队提出了全新的「生成–理解–动作」一体化模型 ManualVLA。 论文题目:ManualVLA: A Unified VLA Model for Chain-of-Thought Manual Generation and Robotic Manipulation论文链接:: π0 等端到端模型在处理复杂长程任务时仍面临的推理与执行割裂问题,ManualVLA 摒弃了将「高层次规划」与「动作生成」拆分的传统分层级联方案,构建了全新通用基础模型 Mixture-of-Transformers (MoT) 架构,在同一模型中统一多专家模块,实现多模态生成与动作执行的紧密协同。

北京清华长庚医院与北电数智签署战略合作,赋能药学创新和睡眠医学研究
10月16日,北京清华长庚医院与北京电子数智科技有限责任公司(简称“北电数智”)达成战略合作。 依托北电数智“星火·医疗底座”,双方将在药学大模型、睡眠大模型、药学可信空间、具身智能等多个“AI 医疗”创新领域开展联合攻关,并在北京清华长庚医院率先落地应用,打通技术迭代与临床验证的闭环,提升医疗服务效率与智能化水平,推动医疗普惠进程,助力健康中国战略。 北京清华长庚医院院长董家鸿院士,北京清华长庚医院副院长张萍,北电数智董事长荆磊,北电数智首席科学家、复旦大学特聘教授窦德景,北电数智产业生态负责人吴岳,AI可信负责人邵兵等出席签约仪式。

北大南开数学家解决著名“十杯马天尼”问题:更统一、更优雅的证明
困扰数学和量子力学交叉领域长达半个世纪的难题,因为北大、南开数学家的参与,终于是有了较为完美的答案。 这个难题有个非常有趣的名字,叫做“十杯马天尼”(The Ten Martini Problem)。 之所以叫这个名字,是因为数学家马克·卡茨(Mark Kac)在1981年表示,谁能解决这个问题,就请对方喝十杯马天尼。

500万视频数据集+全新评测框架!北大开源主体一致性视频生成领域新基建OpenS2V-Nexus,生成视频 「像」 又 「自然」
想让 AI 能 「看着你的自拍就生成一致且自然的短视频」 吗? 这就是 Subject-to-Video(S2V)生成要解决的问题:让视频生成不仅对齐文本,还能准确保留指定人物或物体的特征,让生成的视频既 「像」 又 「自然」。 这一能力对于短视频生成、虚拟人、AI 剪辑等都有巨大意义。
通义实验室、北大发布新技术ZeroSearch 让LLM检索能力激活,成本降低88%
最近,通义实验室和北京大学的研究团队推出了一项名为 ZeroSearch 的创新框架,这一新技术可以在不需要真实搜索的情况下,激活大语言模型的检索能力,并且训练成本降低了惊人的88%。 这一突破为大语言模型的训练和应用提供了全新的思路。 传统的训练方法通常依赖于真实的搜索引擎来获取信息,这不仅造成了高昂的 API 调用成本,还可能因搜索结果的质量不稳定而影响模型的表现。

北大团队首次系统性评估大语言模型心理特征,推动AI评估新标准
在人工智能迅猛发展的今天,大语言模型(LLM)展现出了超凡的能力,但如何科学评估它们的 “心智” 特征,比如价值观、性格和社交智能,依旧是一个亟待解决的难题。 近期,北京大学的宋国杰教授团队发布了一篇全面的综述论文,系统梳理了大语言模型心理测量学的研究进展,为 AI 的评估提供了新视角。 这篇论文名为《大语言模型心理测量学:评估、验证与增强的系统综述》,长达63页,引用了500篇相关文献。

北大团队提出全新框架LIFT 将长上下文知识注入模型参数
北京大学张牧涵团队提出了一种全新的框架——Long Input Fine-Tuning (LIFT),通过将长输入文本训练进模型参数中,使任意短上下文窗口模型获得长文本处理能力。 这一方法颠覆了传统的长文本处理思路,不再专注于无限扩充上下文窗口,而是将长文本知识内化到模型参数中,类似于人类将工作记忆转化为长期记忆的过程。 目前大模型处理长文本面临两大主要挑战:传统注意力机制的平方复杂度导致处理长文本时计算和内存开销巨大 模型难以理解散落在长文本各处的长程依赖关系现有的解决方案如RAG和长上下文适配各有局限:RAG依赖准确的检索,容易引入噪声导致幻觉 长上下文适配的推理复杂度高,上下文窗口仍然有限LIFT的技术创新LIFT框架包含三个关键组件:动态高效的长输入训练通过分段的语言建模将长文本切分为有重叠的片段 避免因过长上下文造成的推理复杂度提升和长程依赖丢失 训练复杂度对长文本长度呈线性增长 平衡模型能力的门控记忆适配器设计专门的Gated Memory Adapter架构 动态平衡原始模型的In-Context Learning能力和对长输入的记忆理解 允许模型根据查询自动调节使用多少LIFT记忆的内容辅助任务训练通过预训练LLM基于长文本自动生成问答类辅助任务 补偿模型在切段训练中可能损失的能力 帮助模型学会应用长文本中的信息回答问题实验结果LIFT在多个长上下文基准测试上取得显著提升:LooGLE长依赖问答:Llama38B的正确率从15.44%提升至29.97% LooGLE短依赖问答:Gemma29B的正确率从37.37%提升至50.33% LongBench多项子任务:Llama3通过LIFT在5个子任务中的4个有明显提升消融实验表明,Gated Memory架构相比使用PiSSA微调的原模型,在LooGLE ShortQA数据集上的GPT-4score提升了5.48%。

北京大学联合华为发布全栈开源 DeepSeek 推理方案
据介绍,该方案基于北大自研 SCOW 算力平台系统、鹤思调度系统,并整合 DeepSeek、openEuler、MindSpore 与 vLLM / RAY 等社区开源组件,实现华为昇腾上的 DeepSeek 高效推理,并支持大规模算力集群训推一体化部署。所有开发者均可获取源码并根据需求二次开发,性能接近闭源方案。

字节跳动与北京大学成立豆包大模型联合实验室
联合实验室的科研将基于字节跳动豆包大模型展开。来自高校和企业的科研人员将在实验室内,重点围绕大模型的训练、推理等开展科研工作。
量化617,462种人类微蛋白必需性,北大LLM蛋白质综合预测与分析,登Nature子刊
编辑 | 萝卜皮人类必需蛋白(HEP)对于个体的生存和发育必不可少。 然而,鉴定 HEP 的实验方法通常成本高昂、耗时费力。 此外,现有的计算方法仅在细胞系水平上预测 HEP,但 HEP 在活体人类、细胞系和动物模型中有所不同。

字节&北大Nature子刊新成果:自旋本征态的高效精确求解
编辑 | ScienceAI近些年来 AI for Science 在众多领域取得重大成功。 其中,基于神经网络的量子变分蒙特卡洛方法 (NNVMC) 在量子化学领域展现出强大潜力,备受关注。 最近字节跳动研究部门 ByteDance Research 和北京大学团队在 NNVMC 框架中融入物理对称性,实现了量子激发态的高效精确求解。

Nature子刊,北大陈语谦团队提出多模态单细胞数据整合和插补的深度学习方法
编辑 | ScienceAI今天为大家介绍的是来自北京大学信息工程学院、化学生物学与生物技术学院省部共建肿瘤化学基因组学国家重点实验室、鹏城国家实验室合聘研究员和 AI4S 平台中心主任陈语谦教授团队发表在《Nature Communications》的论文。该团队开发了一种新型的多模态整合方法,能够实现多模态单细胞数据的整合与插补,这一成果可以促进多模态单细胞数据的分析。文章链接:。

我想给她完整的一生:“全球首个通用智能人”北大小女孩“通通”亮相
9 月 1 日,中央广播电视总台大型公益节目 2024 年《开学第一课》播出,北京大学智能学院、人工智能研究院院长、计算机视觉专家、人工智能专家朱松纯教授携全球首个通用智能人 —— 小女孩(Little Girl)“通通”亮相节目现场。据北京大学介绍,这位名叫“通通”的小女孩拥有三四岁的心智,是一个有“心”的人工智能。她所做的事情不受人为控制,而是由自己“心”里的价值所驱动。在随机的场景中,“通通”会自主地捡起地上的玩具放进收纳盒中,拿起抹布擦去地上的污渍,搬起板凳清洗抹布。通过一系列的行为可以发现,“干净”是她的

改变LoRA的初始化方式,北大新方法PiSSA显著提升微调效果
随着大模型的参数量日益增长,微调整个模型的开销逐渐变得难以接受。为此,北京大学的研究团队提出了一种名为 PiSSA 的参数高效微调方法,在主流数据集上都超过了目前广泛使用的 LoRA 的微调效果。论文: PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models论文链接: : 1 所示,PiSSA (图 1c) 在模型架构上和 LoRA [1] 完全一致 (图 1b),只是初始化 Adapter
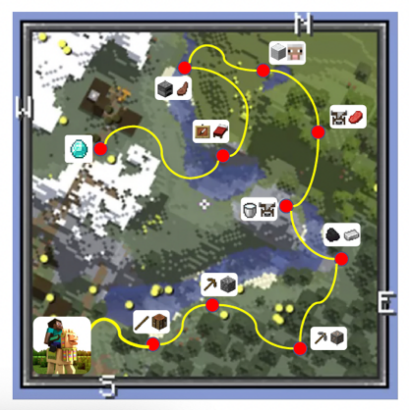
让大模型自主探索开放世界,北大&智源提出训练框架LLaMA-Rider
大语言模型因其强大而通用的语言生成、理解能力,展现出了成为通用智能体的潜力。与此同时,在开放式的环境中探索、学习则是通用智能体的重要能力之一。因此,大语言模型如何适配开放世界是一个重要的研究问题。北京大学和北京智源人工智能研究院的团队针对这个问题提出了 LLaMA-Rider,该方法赋予了大模型在开放世界中探索任务、收集数据、学习策略的能力,助力智能体在《我的世界》(Minecraft)中自主探索获取知识并学习解决各种任务,提升智能体自主能力和通用性。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉