72B

Kimi-Dev-72B: The AI Wonder Breaking the Boundaries of Code Repair
Recently, the much-anticipated open-source large language model Kimi-Dev-72B has officially launched, becoming a favorite among developers. This model was developed by the "Dark Side of the Moon" team and is specifically designed to solve coding problems, aiming to enhance programming efficiency.In the recent SWE-bench Verified test, Kimi-Dev-72B demonstrated extraordinary capabilities, particularly excelling in fixing code defects within Docker environments. This advantage makes Kimi-Dev-72B not only a valuable assistant for developers but also an important tool for optimizing development workflows.The core advantage of this model lies in its reinforcement learning-based optimization mechanism.
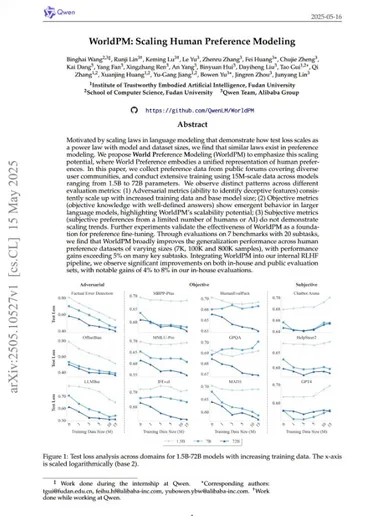
Qwen发布全新偏好建模模型系列WorldPM模型
阿里巴巴旗下Qwen团队宣布推出全新偏好建模模型系列——WorldPM,包括WorldPM-72B及其衍生版本WorldPM-72B-HelpSteer2、WorldPM-72B-RLHFLow和WorldPM-72B-UltraFeedback。 这一发布引发了全球AI开发者社区的广泛关注,被认为是偏好建模领域的重要突破。 WorldPM:偏好建模的规模化新探索WorldPM(World Preference Modeling)是Qwen团队在偏好建模领域的最新力作。

阿里通义千问开源 Qwen2.5 大模型,号称性能超越 Llama
感谢在今天的 2024 云栖大会上,阿里云 CTO 周靖人发布通义千问新一代开源模型 Qwen2.5,其中,旗舰模型 Qwen2.5-72B 号称性能超越 Llama 405B。Qwen2.5 涵盖多个尺寸的大语言模型、多模态模型、数学模型和代码模型,每个尺寸都有基础版本、指令跟随版本、量化版本,总计上架 100 多个模型。Qwen2.5 语言模型:0.5B、1.5B、3B、7B、14B、32B 以及 72B;Qwen2.5-Coder 编程模型:1.5B、7B 以及即将推出的 32B;Qwen2.5-Math 数

开源 AI 大模型“洗牌”:阿里通义千问 Qwen2-72B 成“王者”,傲视 Meta Llama-3、微软 Phi-3 等群雄
感谢Hugging Face 联合创始人兼首席执行 Clem Delangue 于 6 月 26 日在 X 平台发布推文,表示阿里云开源的通义千问(Qwen)指令微调模型 Qwen2-72B 在开源模型排行榜上荣登榜首。Hugging Face 公布了全新的开源大语言模型排行榜,通过 300 片英伟达 H100 GPU,重新运行 MMLU-pro 等标准评估目前主流的大语言模型,并在其要点介绍中称 Qwen2-72B 为“王者”,并表示中国的诸多开源模型在榜单上有一席之位。他表示,为了提供全新的开源大模型排行榜,使

斯坦福大模型评测榜 Claude 3 排名第一,阿里 Qwen2、零一万物 Yi Large 国产模型进入前十
斯坦福大学基础模型研究中心(CRFM)6 月 11 日发布了大规模多任务语言理解能力评估(Massive Multitask Language Understanding on HELM)排行榜,其中综合排名前十的大语言模型中有两款来自中国厂商,分别是阿里巴巴的 Qwen2 Instruct(72B)和零一万物的 Yi Large(Preview)。据悉大规模多任务语言理解能力评估(MMLU on HELM)采用了 Dan Hendrycks 等人提出的一种测试方法,用于衡量文本模型在多任务学习中的准确性。这个测试

阿里云通义千问系列 AI 开源模型升至 Qwen2:5 个尺寸、上下文长度最高支持 128K tokens
感谢通义千问(Qwen)今天宣布经过数月的努力,Qwen 系列模型从 Qwen1.5 到 Qwen2 的重大升级,并已在 Hugging Face 和 ModelScope 上同步开源。IT之家附上 Qwen 2.0 主要内容如下:5 个尺寸的预训练和指令微调模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 以及 Qwen2-72B在中文英语的基础上,训练数据中增加了 27 种语言相关的高质量数据;多个评测基准上的领先表现;代码和数学能力显著提升;增大了上下文长
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉