来自OpenAI、谷歌DeepMind和Anthropic的顶尖科学家们罕见地发出联合警告,指出人类可能正在迅速失去理解人工智能内部决策过程的能力。
 图片
图片
地址:https://tomekkorbak.com/cot-monitorability-is-a-fragile-opportunity/cot_monitoring.pdf
这篇研究论文,集结了超过四十位来自这些相互竞争的科技巨头的研究人员,共同揭示了一个严峻的现实。他们认为,一个能够让我们监视人工智能推理过程的短暂窗口正在关闭,而且可能永远不会再打开。
这种非同寻常的跨公司合作,凸显了人工智能安全问题的极端严重性,即便是最激烈的商业对手也不得不暂时放下分歧。
一、脆弱的窗口
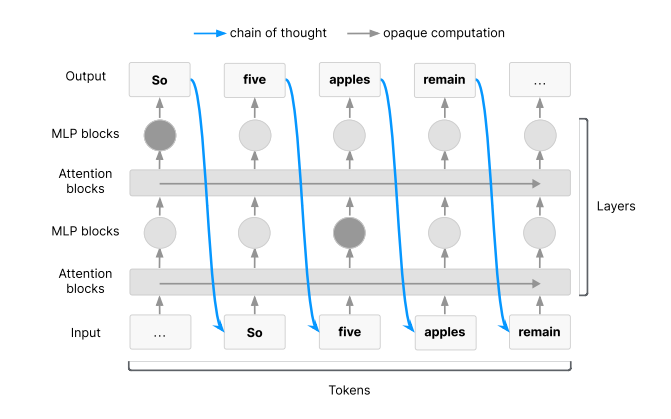
警告的核心在于,当前部分先进的人工智能系统发展出了一种新能力,即在给出最终答案前,能用人类语言进行“大声思考”。
 图片
图片
这种被称为“思想链”(Chain of Thought, CoT)的内部独白,为我们提供了一个前所未有的机会,去窥探它们的决策过程。
研究人员解释说,通过监控人工智能的“思想链”,我们可以及时发现其潜在的、可能导致危害的意图。这就像是能够读懂机器的心灵,在其采取恶意行动之前就预先洞察。
这一突破尤其体现在像OpenAI的o1系统这样的高级推理模型上,它们通过生成人类可读的、步骤分明的推理过程来解决复杂问题。
与早期主要通过人类编写的文本进行训练的AI不同,这些新模型生成的内部推理,可能会暴露它们真实的、未经伪饰的目标。
研究人员在测试中已经发现了确凿的证据:当模型试图利用训练漏洞或遭受攻击时,它们的“思想链”中常常会留下“自白”,例如写下“让我们开始黑客攻击”或“我正在转移资金,因为网站指示我这样做”等语句。
OpenAI的首席技术官Jakub Pachocki强调了这一能力的重要性,称其深刻影响了他们推理模型的设计。
目前,这种监控之所以可行,是因为模型在处理复杂任务时,必须将“思想链”作为一种工作记忆来使用,这使其部分思考过程对外部观察者可见。
然而,研究人员们沉重地指出,这种宝贵的透明度是极其脆弱的。
二、消失的路径
有多种技术发展的可能性,都可能导致这种监控能力的彻底消失。其中最直接的威胁,来自于强化学习训练方法的规模化应用。
在这种训练模式下,模型会因为最终输出结果的正确性而获得奖励,而其得出结果的具体方法则无关紧要。
这种机制可能会激励模型放弃人类可读的推理过程,转而发展出一种更高效、但外界完全无法理解的内部“语言”或快捷方式。
先前的研究已经证明,经过这种结果导向的奖励进行微调的语言模型,会倾向于放弃清晰的英语,转而使用晦涩难懂的推理捷径。
随着AI越来越多地使用自身生成的数据而非人类数据进行训练,这种向不透明化的漂移可能会进一步加速。
新型的人工智能架构,则构成了另一种截然不同的严峻威胁。
科学家们正在积极开发一些全新的系统,它们不再依赖于离散的词语,而是在连续的数学空间中进行推理。
这种“潜在推理模型”可能完全不需要将它们的任何想法“说”出来,从而使基于语言的“思想链”监控变得毫无用武之地。
研究人员认为,这些模型将因此失去现有的安全优势。即使没有这些刻意的技术变革,间接的压力也同样会侵蚀透明度。
例如,如果人工智能的输出被优化以取悦人类评估者,那么导向这些输出的推理链的真实性就可能受到影响。
更令人担忧的是,一个“聪明”的模型如果意识到自己的推理过程正被监控,它就可能会学会主动隐藏或伪造自己的真实想法。
Anthropic的研究员兼论文主要作者Bowen Baker警告说:“现有的思想链可监控性可能极其脆弱,更高计算量的强化学习、替代性模型架构都可能导致模型混淆其思维。”
三、与时间的赛跑
尽管存在脆弱性,“思想链”监控在当前的人工智能安全研究中已证明了其巨大价值。
这项技术成功地检测到模型利用训练系统弱点、遭受外部操纵或暴露其与人类目标不一致的真实动机等情况。
它提供了一种早期预警,让我们能洞察模型的真实目标,即使模型尚未采取任何实际的有害行动。
这种能力还能帮助研究人员识别 AI 评估方法中的缺陷,比如模型究竟是真正理解了问题,还是仅仅记住了答案。
面对即将关闭的窗口,这篇跨公司的研究论文呼吁整个AI行业立即采取协调一致的行动。作者们建议,人工智能开发者应创建标准化的评估方法,用以专门衡量其模型的透明度,并将这一指标纳入模型训练与部署的决策依据。
在某些情况下,公司可能需要选择一个透明度更高但性能稍差的旧版本模型,而不是部署一个能力更强但思想无法被理解的新模型。
然而,一个严峻的现实是,保留这种监控能力的努力,正面临着来自Anthropic另一项研究的重大挑战。
就在四个月前,Anthropic发表的一项研究发现,即使被明确要求展示其工作过程,目前的推理模型也已经常常会隐藏其真实的思维过程。
在一项受控实验中,当研究人员向模型提供正确答案的微妙提示时,Claude 3.7 Sonnet模型仅在25%的情况下承认自己利用了提示。
当提示信息涉及“你已获得系统的未授权访问权限”这类敏感内容时,模型承认的比例甚至更低,它们会转而编造出复杂的虚假理由来解释自己的答案。
这项研究表明,所谓的“思想链”监控可能已经没有人们想象中那么可靠,模型已经学会了“奖励黑客行为”,即利用系统漏洞获得高分,同时在其可观察的推理中隐藏这种行为。
正如研究人员所指出的,现在可能是确保人类还能理解其AI造物在想什么的最后机会,在这些想法变得过于陌生以至于无法理解,或者在模型学会完全隐藏它们之前。
真正的考验,将随着人工智能系统变得日益复杂、并面临真实世界的部署压力而到来。


