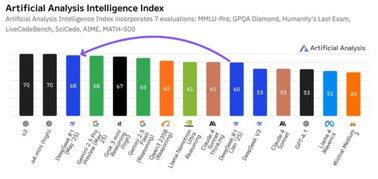
近日,斯坦福大学发布了一项有关临床医疗 AI 模型的全面评测,DeepSeek R1以66% 的胜率和0.75的宏观平均分,在九个前沿大模型中脱颖而出,成为冠军。这一评测的亮点在于,它不仅关注传统医疗执照考试题,更深入到临床医生的日常工作场景,给出了更切实的评估。
评测团队构建了一个名为 MedHELM 的综合评估框架,包含35个基准测试,覆盖22个医疗任务子类别。这个框架的设计经过了29名来自14个医学专科的执业医生验证,确保了其合理性与实用性。最终,评测结果揭示了 DeepSeek R1的优越性能,紧随其后的是 o3-mini 和 Claude3.7Sonnet。
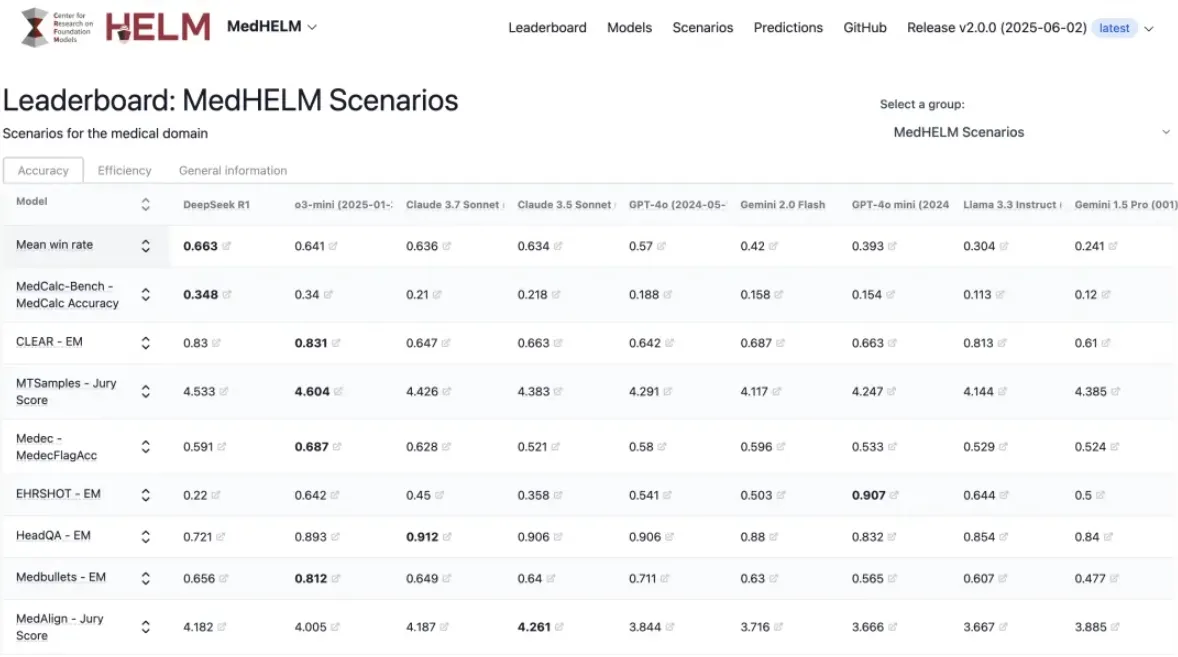
具体而言,DeepSeek R1在各项基准测试中表现稳健,胜率标准差仅为0.10,表明其在不同测试中的稳定性。而 o3-mini 则在临床决策支持类别的基准测试中表现突出,以64% 的胜率和0.77的最高宏观平均分位居第二。其他模型如 Claude3.5和3.7Sonnet 分别以63% 和64% 的胜率紧随其后。
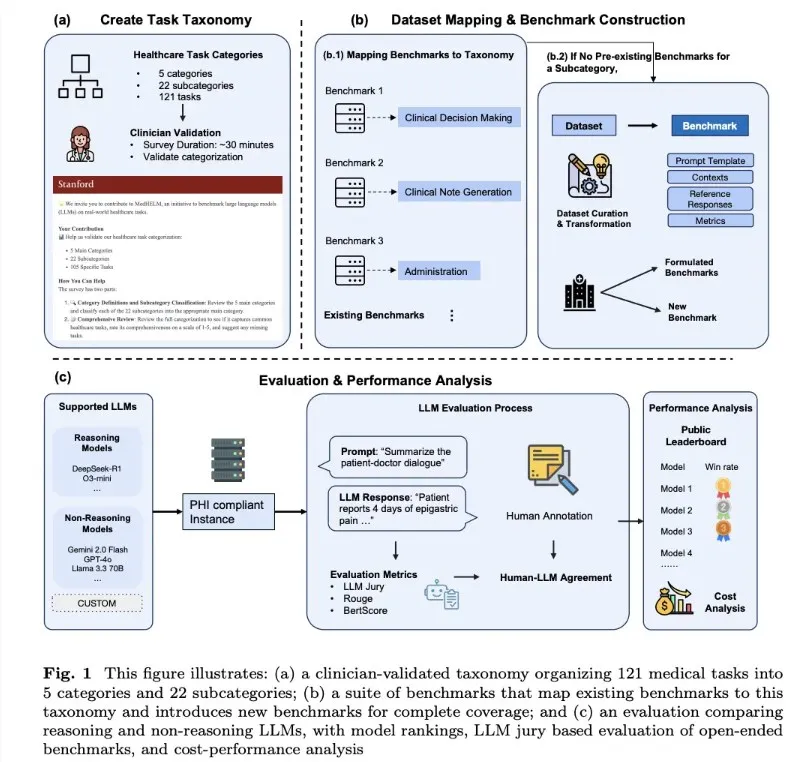
值得一提的是,此次评测还创新性地采用了大语言模型评审团(LLM-jury)方法进行结果评估,结果显示该方法与临床医生的评分高度一致,证明了其有效性。此外,研究团队还进行了成本效益分析,发现推理模型的使用成本相对较高,而非推理模型成本较低,适合不同需求的用户。
此次评测不仅为医疗 AI 的发展提供了宝贵的数据支持,也为未来的临床实践提供了更多的可能性和灵活性。