学会“适当暂停与总结”,大模型终于实现无限推理。
想象一下,让你一口气不歇地推演一个超复杂数学证明,大脑也会“内存溢出”吧?
如今的大模型在长上下文推理中也面临同样的困境,随着推理长度增加而指数级增长的计算成本,以及由于长度受限而被迫中断推理过程。
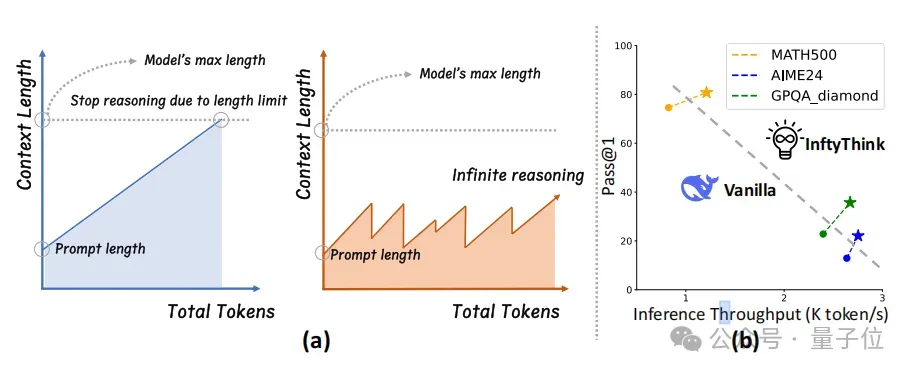
为了解决上述问题,浙江大学联合北京大学的研究团队从人类“分段思考+归纳总结”的智慧中汲取灵感,创新性地提出了大模型的推理新范式——InftyThink。
InftyThink将传统单一连续推理拆分为多个短片段,并在片段之间引入用于衔接的推理内容总结,从而突破了推理长度的限制,实现了理论上无限制的推理深度,并同时维持了较高的生成吞吐。

下面是InftyThink的更多详细细节。
推理范式设计
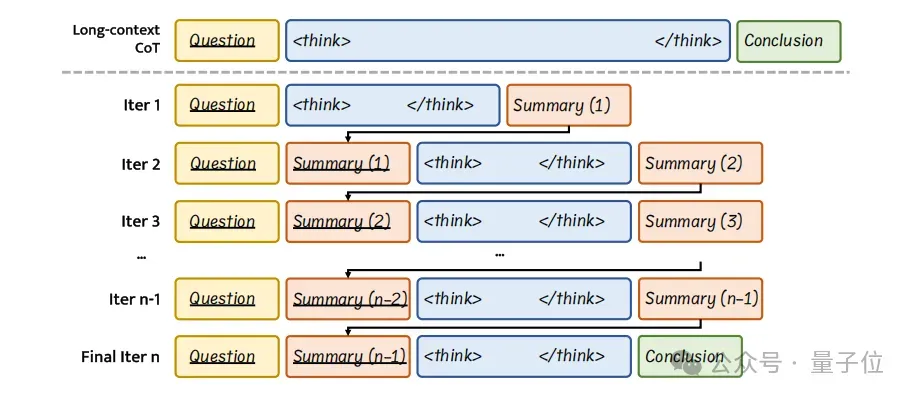
InftyThink的主要特征包含:
- 迭代式推理与阶段性总结
InftyThink将传统一次性完成的长推理拆分为多次短推理,每次短推理生成有限长度的推理内容,并配套生成一段精炼总结,作为下一阶段推理的上下文信息输入。
这种方式模拟了人类逐步归纳总结的认知过程,使模型能在保持上下文连贯的同时进行无限深度的推理,解决了传统长推理在上下文长度和计算复杂度上的限制。
- 固定的计算开销与上下文窗口
InftyThink实现了一种“锯齿式”内存使用模式,在每轮短推理后清空前轮上下文,仅保留总结,显著降低了推理时的计算复杂度。
相对传统的推理范式长度越长,计算复杂度越高的表现,InftyThink在推理深度与计算效率之间达成了更优的平衡。
- 与原始架构解耦、训练范式兼容性强
InftyThink不依赖于模型结构上的调整,而是通过重构训练数据为多轮推理格式来实现其范式,使其能与现有的预训练模型、微调、强化学习流程无缝结合,具备良好的工程可落地性。
一句话概括就是,InftyThink像是给大模型装上了一个“思维管理器”,使其高效地进行无限制深度推理,大幅降低计算成本,更加高效智能。
数据重构方法
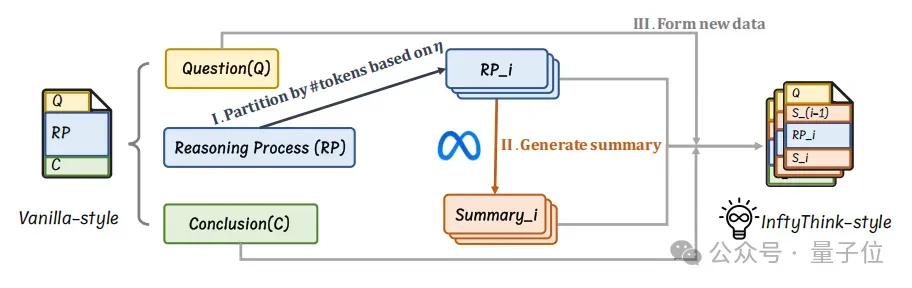
研究团队提供了一种可以将传统推理范式的数据重构为InftyThink范式的方法,帮助研究者们直接将已有的推理数据无缝迁移到InftyThink范式,主要包括如下几个步骤:
- 推理片段分区
由于InftyThink将模型的单次推理限制在一个较小的窗口,针对现有的长推理数据,首先需要使用分段算法将原始长推理过程按语义边界划分为若干子推理段。
文中使用句子/段落进行分界,并确保每段长度小于设定上下文窗口阈值(文中提到的默认值为4K Tokens),同时保持语义的连贯性。
- 中间总结生成
论文中使用强大的通用大模型为每段推理生成简洁、全面的总结(文中使用Llama3-70B-Instruct),作为下一轮次生成的上下文信息,保障多次短推理之间的衔接与信息的连续性。
文中所提出的方法在为一段推理片段生成总结时,会将当前推理片段及其之前的所有推理片段输入给通用大模型,使生成的总结能够包含历史推理的全部总结信息。
- 训练样本构建
论文将每条原始推理数据重构为多个训练样本,每条训练样本的输入为问题和上一次推理所生成的总结,输出为该轮次的推理内容和配套的简要总结。
对于第一次推理,输入不含总结信息,对于最后一次推理,模型无需输出总结,而是生成最终最问题的结论。
实验结果
研究团队在多个基座模型上进行了InftyThink范式数据的微调训练,并同时在多个标准推理评测基准上上进行了广泛的实验评估。
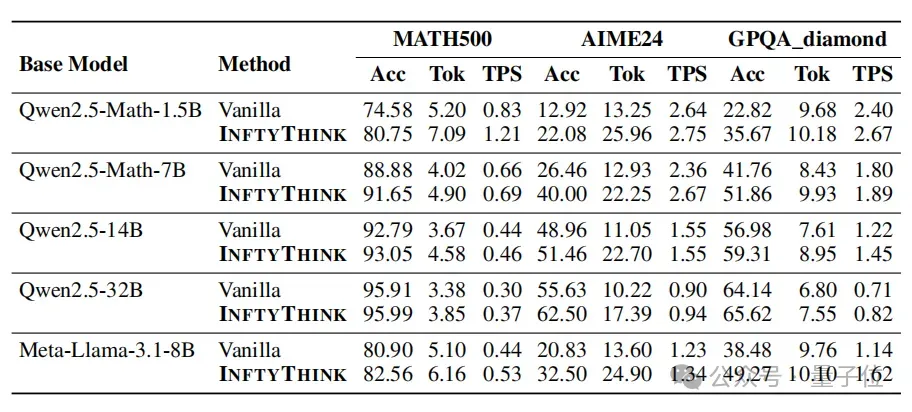
实验结果表明,InftyThink范式相对传统推理范式表现卓著:
- 拓展了模型的推理深度,在不增加额外算力需求的前提下,显著提高了模型性能,如Qwen2.5-Math-7B基座模型训练后,相对传统的推理范式在AIME24基准上的性能提升高达13%。
- 通过多次迭代式的短推理,显著降低了推理的计算复杂度,提高了模型生成的吞吐量,例如在Qwen2.5-Math-7B基座模型训练后,相对传统的推理范式,模型生成吞吐从2.36K Token/s提升到2.67K Token/s。
- 在不同架构和规模的基座模型上展现出一致稳定的提升,研究团队在Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B和Meta-Llama-3.1-8B上的实验结果呈现了高度一致的性能提升表现,证明了所提出方法的广泛适用性和鲁棒性。
具体来看,InftyThink通过有效总结和短片段推理,实现了更灵活、更深度的推理能力,这在小规模模型上的表现尤其显著,为未来小模型的高效能推理应用提供了全新的解决方案。
论文链接:https://arxiv.org/abs/2503.06692项目链接:https://zju-real.github.io/InftyThink代码链接:https://github.com/ZJU-REAL/InftyThink


