在端侧设备上处理长文本常常面临计算和内存瓶颈。
vivo AI研究院推出的EdgeInfinite算法专为端侧设备设计,让设备处理超长文本时更加高效流畅,该方法能够在不到10GB GPU内存的设备上处理长达128K tokens的输入。
该研究成果已中稿ACL 2025。

以下是更多详细内容介绍。
EdgeInfinite:解决端侧设备长文本处理的高效算法
端侧LLM在实际应用中会遇到很多长文本输入的场景(例如通话摘要和个人文档总结),但由于端侧设备的资源限制,现有的LLM在部署到端侧后都无法处理很长的上下文。
这是由于现在LLM都是基于Transformer架构,其计算耗时和内存占用会随着输入长度增加而显著增长,尤其当需要将Transformer类模型部署到端侧设备上时,面临的挑战会愈发突出。
为了解决这类问题,vivo AI研究院提出了一种用于端侧设备的长文本算法——EdgeInfinite,该算法通过一个可训练的门控记忆模块将记忆压缩算法集成到了Transformer架构中。
本方法与原生的Transformer架构完全兼容,在训练时只需要微调一小部分参数,就可以在长文本任务上取得不错的效果,同时保持了相对高效的推理性能,非常适合在端侧设备上高效地处理长文本任务。
EdgeInfinite架构解析
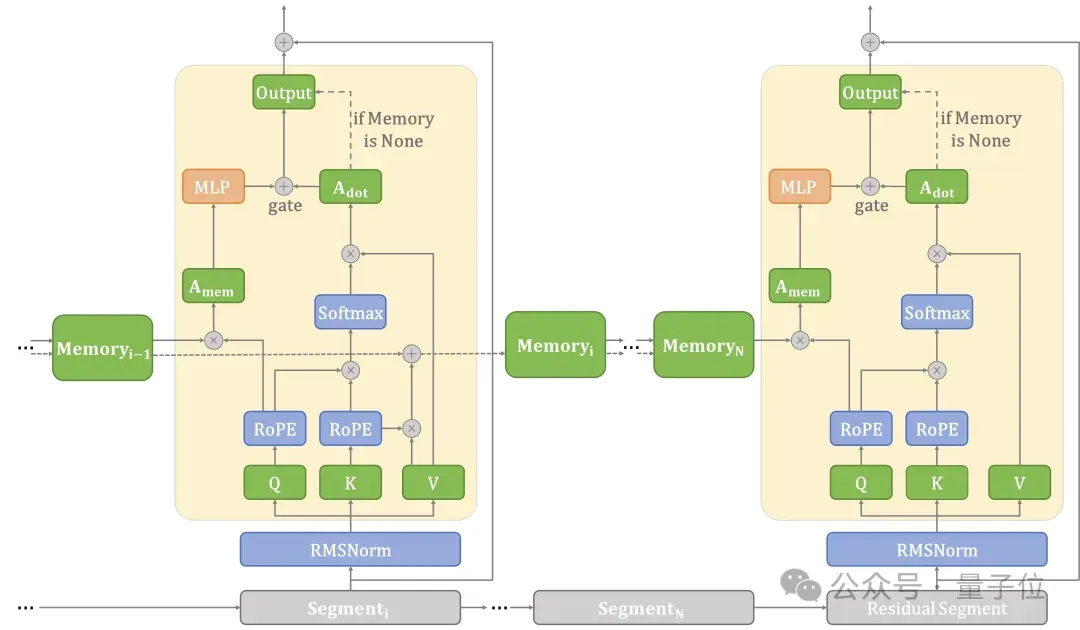
EdgeInfinite的架构如上图所示,主要包括三个核心部分:结合ROPE的分块注意力模块、记忆压缩与解压缩模块和自适应的门控记忆模块。
1. 结合ROPE的分块注意力
EdgeInfinite会把输入的文本序列,按照一定长度切成小的片段。对每个片段分别计算 Q、K、V 值。同时,对每个片段会加入位置编码ROPE,让模型更好地理解小段内每个token之间的相对位置关系,这样在计算注意力的时候就更准确。
2. 记忆压缩与解压缩
EdgeInfinite引入了记忆的压缩与解压缩模块,将过去KV状态分块并存储为固定长度的记忆块,并在计算attention时候解压缩出来进行计算。由于记忆中编码了之前片段的KV对的关联,解压缩使我们能够计算当前Q状态和过去的KV状态之间的注意力。这个过程使得块状计算能够近似原始长序列的注意力计算。
3. 自适应的门控记忆模块
EdgeInfinite通过自适应的门控记忆模块将基于记忆的注意力与基于局部片段的注意力相结合,从而增强模型处理长距离依赖关系的能力。在训练时,EdgeInfinite只需要对记忆门控模块进行微调。
推理策略
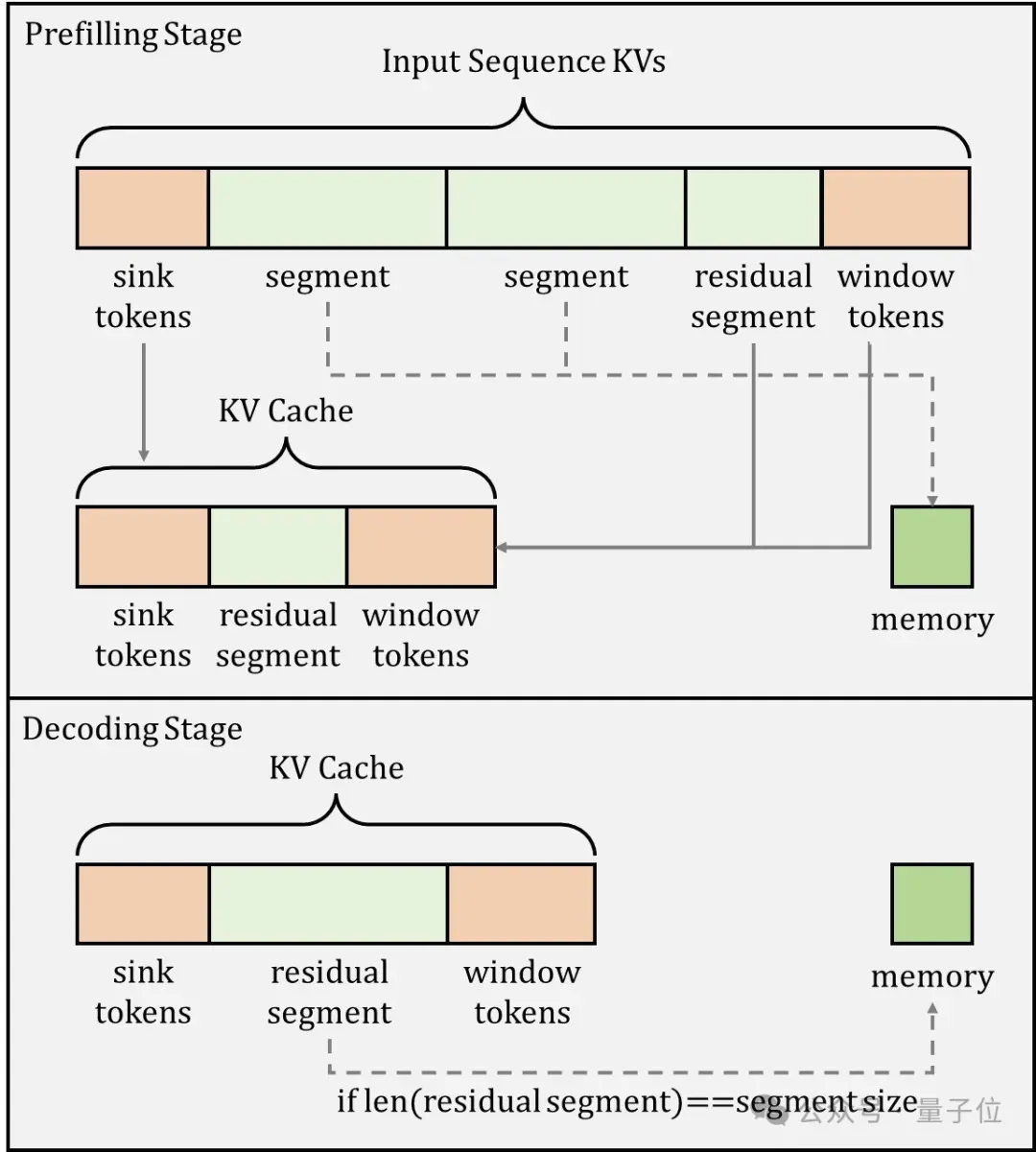

EdgeInfinite在推理时采用了两个策略:
1.保留特定token的kv cache:在推理过程中的固定保留了两种特殊token的kv cache,即sink token(序列最开始的一些token)和window token(序列末尾的一些token),这些token对于保留语义和位置信息非常重要,需要将它们保留为未压缩状态来确保高质量的推理输出。
2.长短文本任务路由机制:EdgeInfinite可以灵活的和已有的基础模型相结合,来提升基础模型的长文本能力,同时也不影响基础模型的短文本能力,这是通过推理时动态的长短文本任务路由来实现的。
实验结果
研究人员使用vivo自研的 BlueLM-3B 作为基础模型,在 LongBench 这个包含多种长文本任务的数据集上测试 EdgeInfinite 的性能,同时将EdgeInfinite与三种KV Cache优化方法(SnapKV、PyramidKV和StreamingLLM)以及保留完整KV Cache的原始模型(FullKV)进行比较。
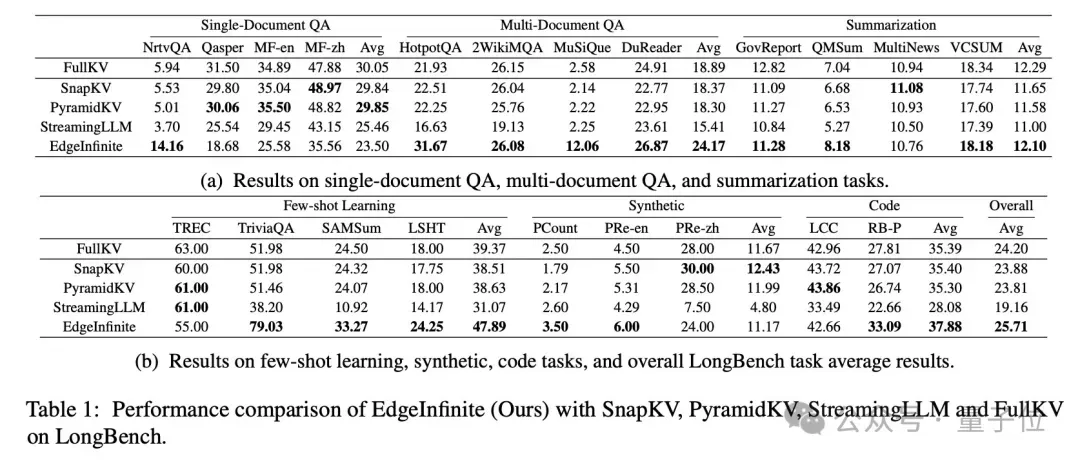
实验结果(如上图)显示,EdgeInfinite在多文档问答和少样本学习这些任务上,相比其他的方法有明显优势;在其中部分任务上还会优于原始的 FullKV 模型,整体模型效果还是很有竞争力的。
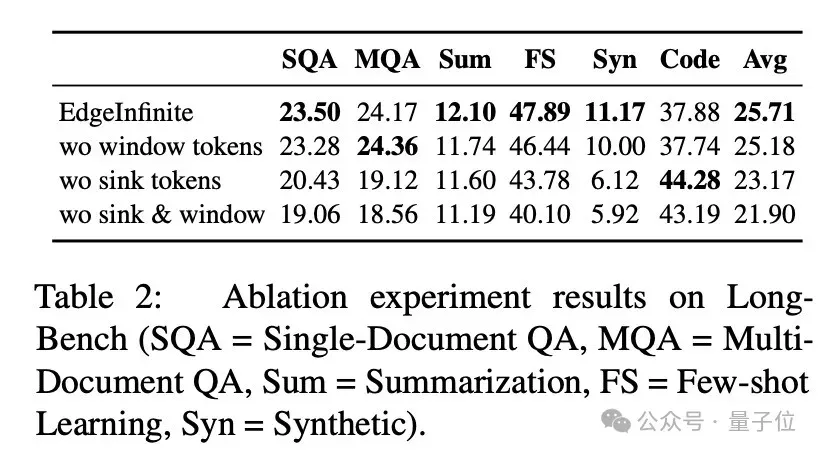
研究人员还做了消融实验来验证推理时保留特定token是很重要的。实验结果(如上图)表明,如果去掉sink token或者window token,推理效果会受到很大影响。
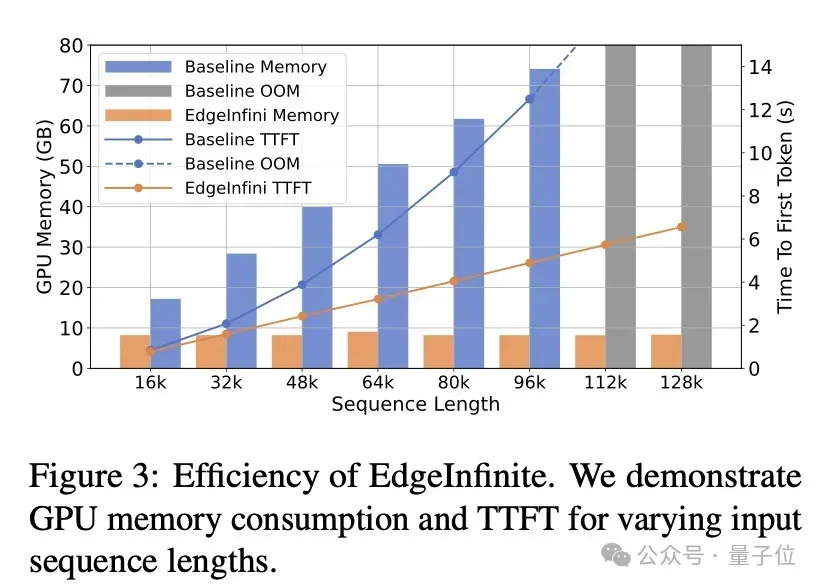
和原始的BlueLM-3B模型相比,EdgeInfinite在处理长文本输入时,首词出词时间更短,占用的内存也更少;即使输入文本长度增加,EdgeInfinite 的内存占用也保持在相对稳定的水平。
未来,EdgeInfinite有望在更多资源受限的设备上广泛应用,提升各类长文本处理任务的效率。比如在智能语音助手、移动办公文档处理等场景中,让用户获得更流畅的体验。
论文链接:https://arxiv.org/pdf/2503.22196


