数据智能体到底好不好用?测评一下就知道了!
南洋理工大学、新加坡国立大学携手华为开源推出首个专门针对数据智能体(Data Agents)异构混合数据分析的综合性基准测试FDABench。
该基准横跨50+数据领域、设置了多种难度等级和任务类型,还独创了Agent-Expert协作框架,确保测试用例质量和数据一致性,同时支持Data Agent、RAG、语义算子以及四种典型Data Agent工作流模式。

团队使用FDABench对各种数据智能体系统进行了评估,发现每个系统在响应质量、准确性、延迟和token成本方面都表现出独特的优势。
下面详细来看。
将数据库、PDF、视频、音频异构数据源一网打尽
面对数据驱动决策的需求日益增长,这催生了对能够整合结构化和非结构化数据进行分析的数据智能体的迫切需求。

△Data Agent 样例
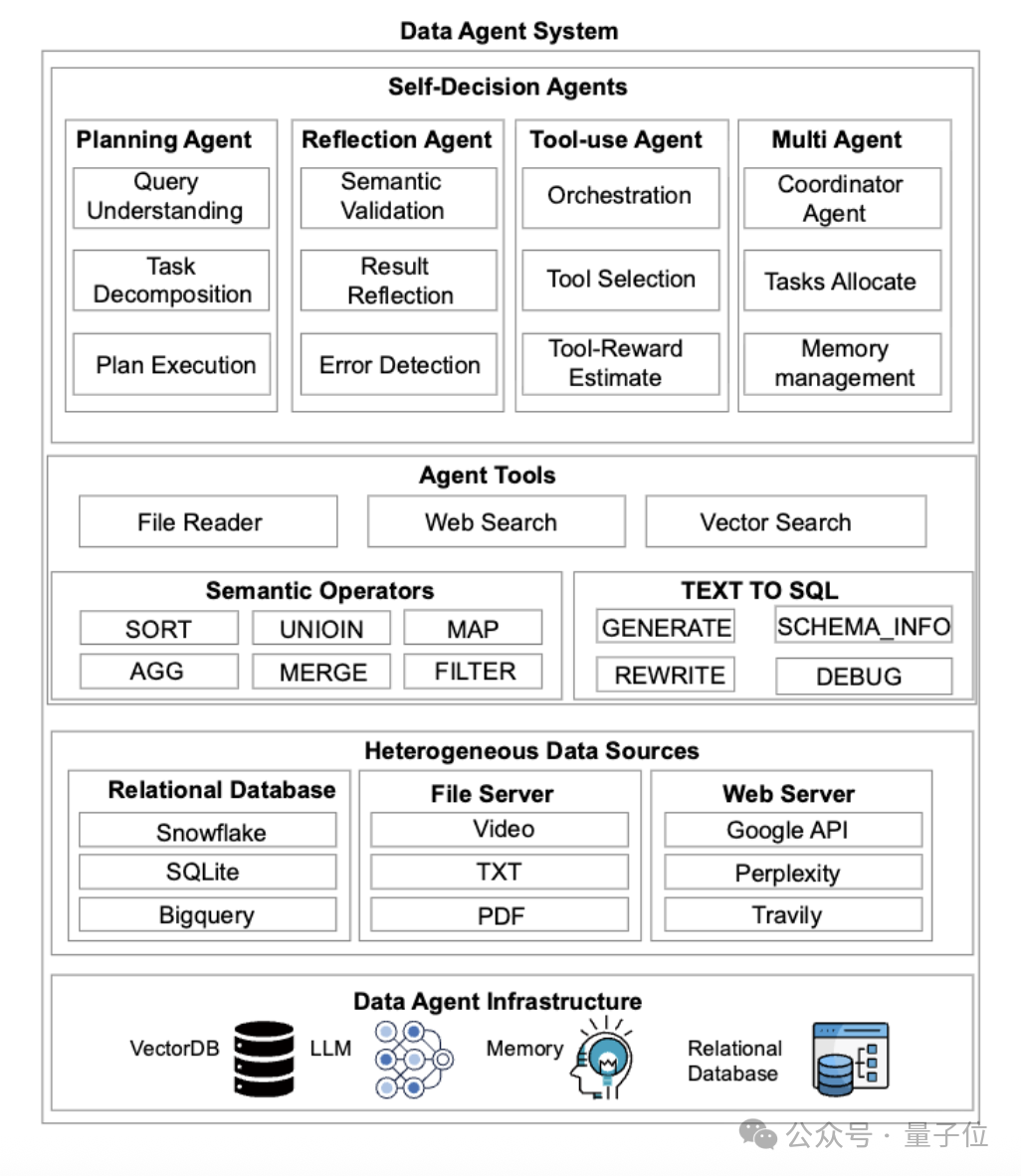 △Data Agent System架构
△Data Agent System架构
尽管数据智能体Data Agents在让用户执行复杂分析任务方面展现出潜力,但该领域仍存在三个关键局限性:
- 首先,由于难以设计出能评估智能体在多源分析任务中各项能力的测试用例,全面的数据智能体Benchmark仍然缺失;
- 其次,构建结合结构化和非结构化数据的可靠测试用例成本高昂且极其复杂;
- 第三,现有基准的适应性和通用性有限,导致评估范围狭窄。
为应对这些挑战,团队提出了FDABench,这是首个专门为评估多源数据分析场景中的智能体而设计的数据智能体基准。
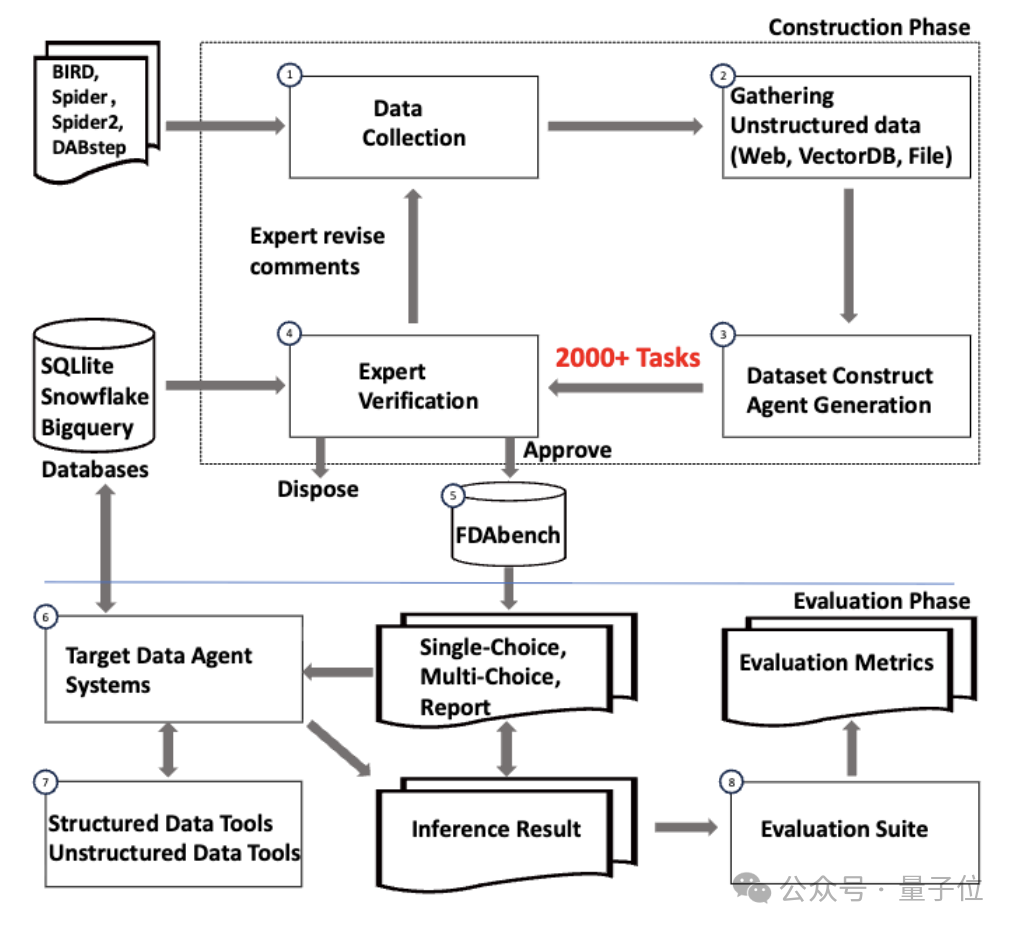 △FDAbench概览
△FDAbench概览
这个基准涵盖了2007个不同的测试任务,覆盖50多个领域,比如金融、电商,还有简单、中等、难三种难度。 推理所需数据包括结构化数据库、PDF文档、视频、音频等异构数据源。
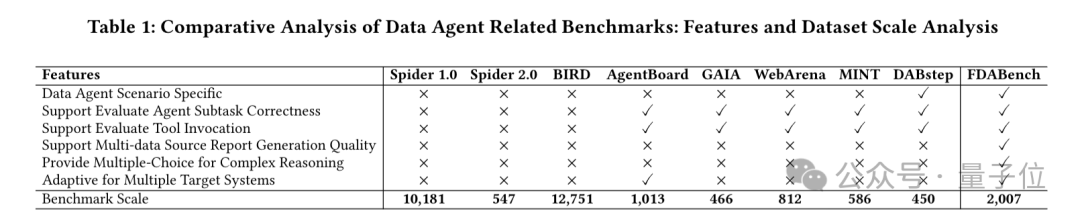
任务类型也分三种:单选题(比如算具体数值)、多选题(比如选多个正确结论,包含具体数值和综合报告推理)、写报告(比如整合数据出分析报告),能全面测数据智能体的能力。
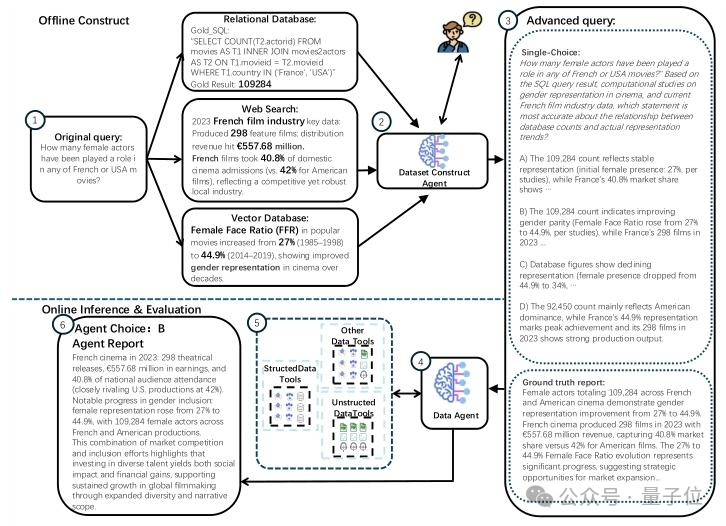
△FDABench样例
团队还设计了统一Agent-Expert协作框架,同时支持Data Agent、RAG、语义算子以及四种典型Data Agent工作流模式(规划Planning、工具使用Tool-use、反思Reflection、多智能体Multi-Agent),可无缝集成不同Data Agent系统架构。
不管数据智能体是靠“提前规划步骤”、“调用工具”、“自我修正”还是“多智能体协作”工作,都能兼容测试,不用换个数据智能体就重新搭测试框架。
研究人员用FDABench测试了市面上常见的几种数据智能体。
一类是通用的数据分析系统,比如能生成财务报告的DAgent、能处理多模态数据的Taiji;
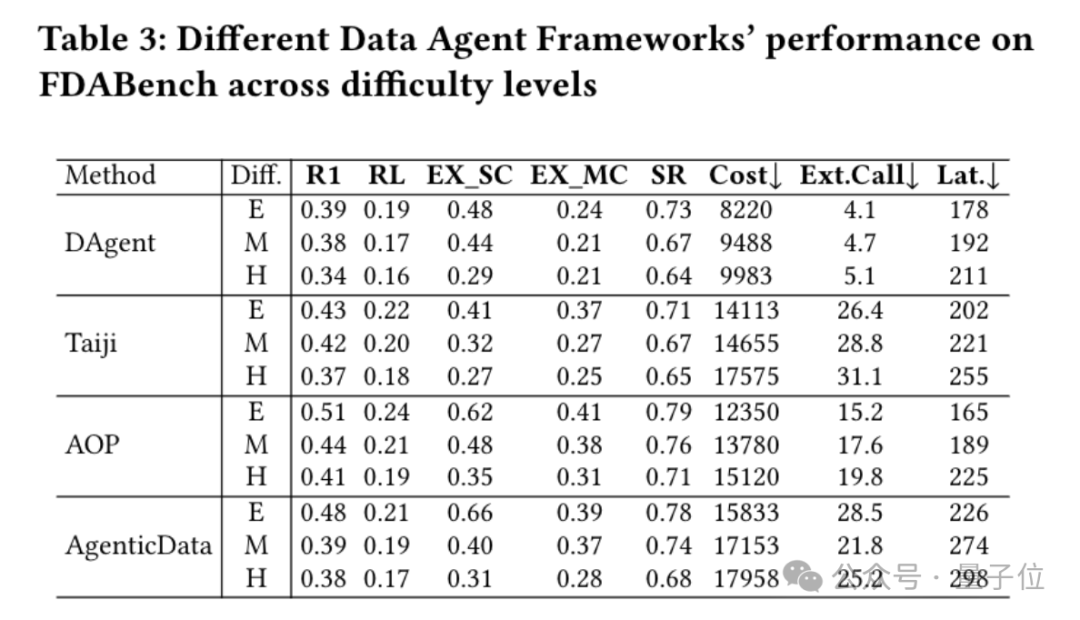
一类是擅长语义理解的语义算子系统,比如能精准处理用户自然语言查询的LOTUS;
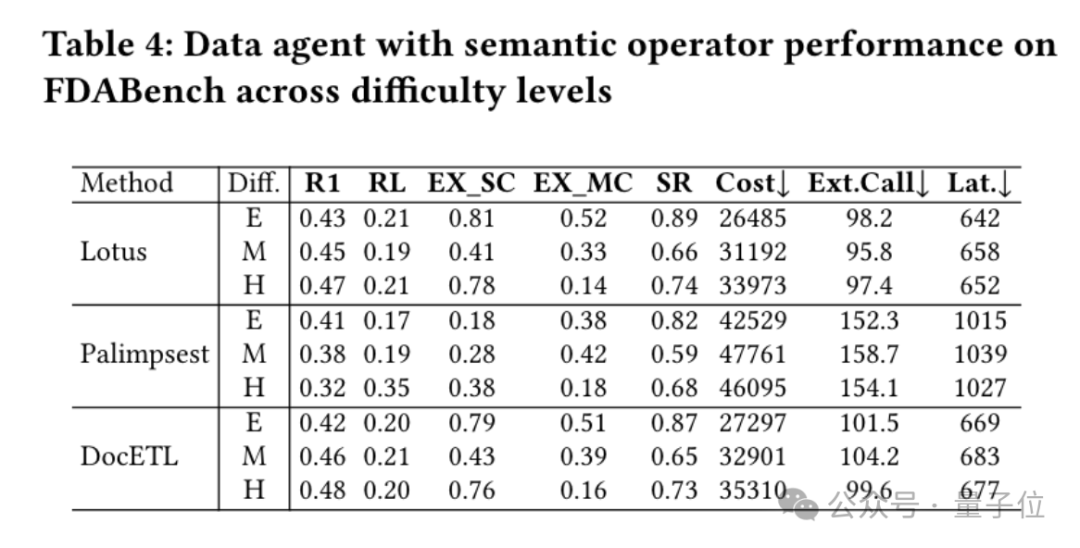
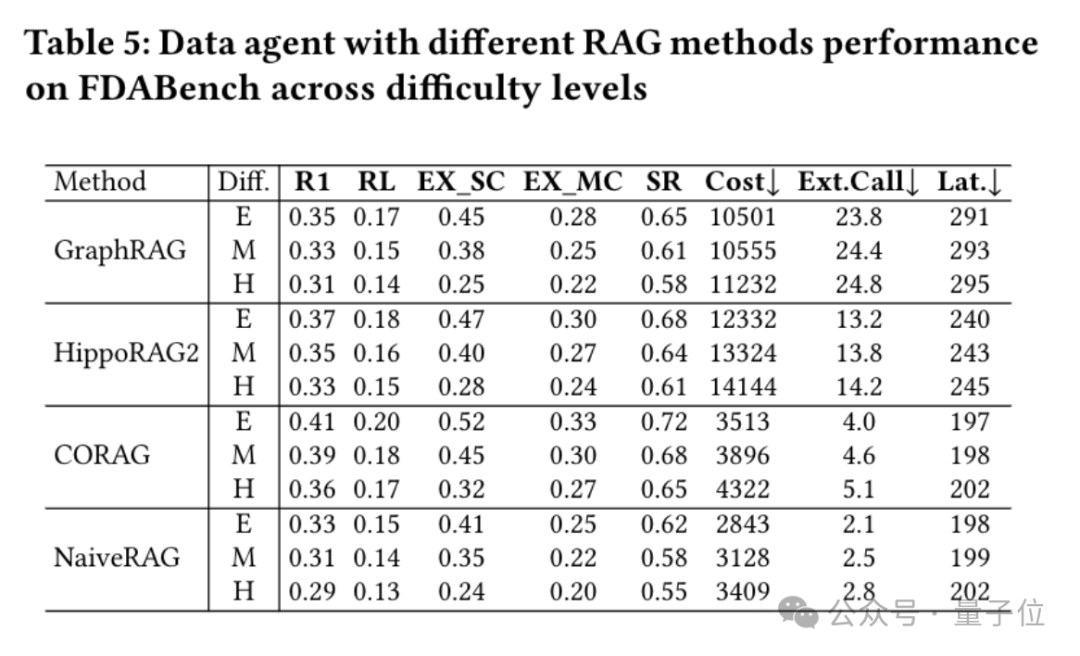
还有一类数据智能体Data Agent是带检索增强(RAG,能查外部数据辅助分析)的系统,比如Data Agent+GraphRAG。
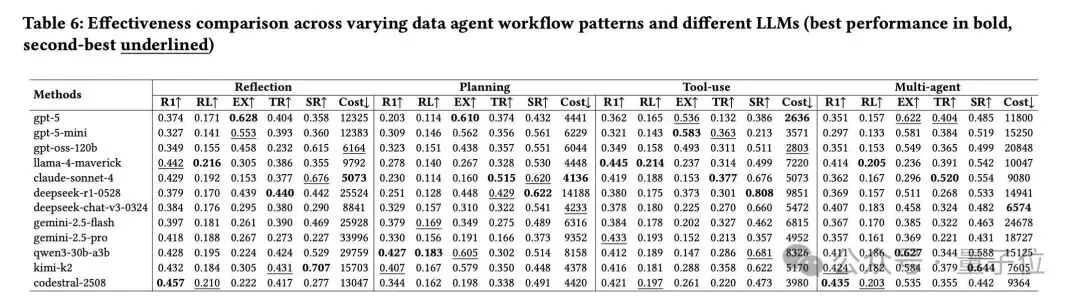
研究人员也提供了对于不同基础模型和智能体架构的全面测试:
团队还尝试去对每种数据智能体进行计算资源拆解,统计了数据智能体每个阶段的耗时和总体系统延迟:
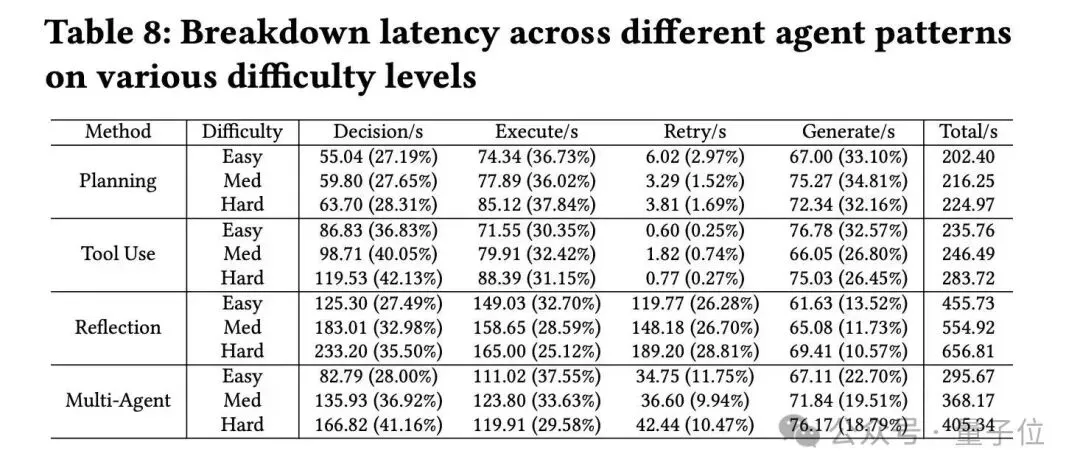
测试后发现:
- 架构复杂度权衡复杂Data Agent架构(如Multi-Agent、Reflection)在异构数据分析准确性上显著优于简单架构,但代价是计算成本成倍增加(6-20倍资源消耗),简单架构如Planning则在效率上占优但面对复杂问题适应性有限;
- 计算资源重分配效应观察到不同Data Agent架构本质是通过重新分配计算开销实现优化——Reflection架构将26-29%计算用于重试机制换取高质量输出,Planning架构将32-35%用于生成阶段保证效率,这种“认知负载重分配”为根据任务场景选择合适架构提供了量化指导
- 模型-架构适配性大规模Agenic Data下预训练的模型即使是Non-Thinking Model(如Kimi-k2)在复杂Multi-Agent和Reflection架构下依旧表现突出,一些Thinking Model(如DeepSeek-R1)在复杂Data Agent架构中反而出现“双重推理惩罚”现象,这表明模型选择需要匹配架构复杂度。
总结一下就是,没有完美的Data智能体,有的快但复杂任务拉胯,有的准却费钱又慢,选的时候要看需求。
而FDABench的作用,就是帮你清楚测出哪个系统最适合你的需求。
论文地址:https://arxiv.org/pdf/2509.02473
代码地址:https://github.com/fdabench/FDAbench


