
译者 | 布加迪
审校 | 重楼
“你能为我们开发一个聊天机器人吗?” 如果你的IT团队还没有收到这个请求,相信我,很快就会收到。随着大语言模型(LLM)的兴起,聊天机器人已成为新的必备功能——无论你是交付SaaS服务、管理内部工具,还是仅仅试图解读庞大的文档。问题是什么?仅仅将搜索索引粘贴到LLM上是不够的。
如果你的聊天机器人需要从文档、日志或其他内部知识来源获取答案,你不仅仅要构建聊天机器人,还要构建检索管道。如果你不考虑数据的存储位置、检索方式以及迁移成本,你将面临一个臃肿且脆弱的系统。
本文将详细介绍如何构建一个真正的对话式聊天机器人——它能够利用检索增强生成(RAG)技术,尽量缩短延迟,并避开悄无声息地扼杀利润的云出站费用陷阱。LLM是简单的部分,基础设施才是困难的部分,也是成本所在。
我将介绍一个简单的对话式AI聊天机器人Web应用程序,它有类似ChatGPT的UI,你可以轻松配置它,以便与OpenAI、DeepSeek 或任何其他大语言模型(LLM)配合使用。
第一部分:RAG 基础知识
检索增强生成(RAG)是一种将LLM的生成特性应用于文档集合的技术,从而生成能够根据文档内容有效回答问题的聊天机器人。
实现的典型RAG将集合中的每个文档拆分成几个大小大致相等且相互重叠的块,并为每个块生成嵌入(embedding)。嵌入是有成百上千个维度的浮点数向量(列表)。两个向量之间的距离表示它们的相似度。距离小表示相似度高,距离大表示相似度低。
然后,RAG应用程序将每个块及其嵌入加载到向量存储库(vector storage)中。向量存储库是一个专用数据库,可以执行相似度搜索——给定一段文本,向量存储库就能通过比较嵌入来检索按其与查询文本的相似度排序的块。
不妨将各部分整合起来:
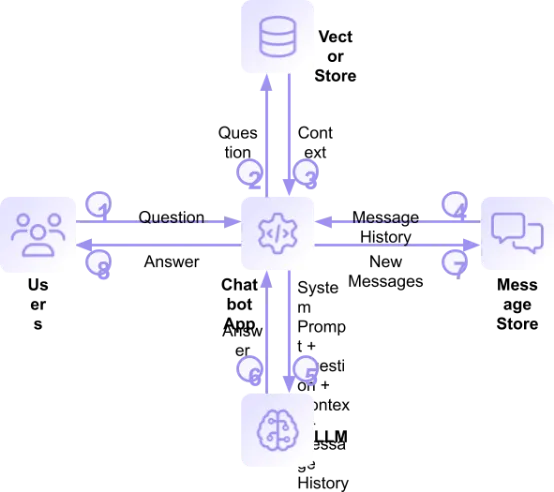
获得用户提出的问题(1)时,RAG应用程序可以查询向量存储库,查找与问题(2)类似的文本块。这些文本块构成了帮助LLM回答用户问题的上下文。以下是使用文档集合的示例:获得问题“告诉我关于对象锁的信息”时,向量存储库向应用程序(3)返回四个文档块,每个块约170个字。以下是每个块的文本链接及简短摘录:
- 对象锁:使用对象锁合法保留功能,可以防止文件被更改或删除;然而,不可变性没有明确的保留期。
- 对象锁:你可以对新创建的存储桶或现有的存储桶启用对象锁。
- 对象锁:对象锁在设计时已考虑到了Veeam Backup & Replication中的不可变性功能。
- 使用与S3兼容的API 启用对象锁:若要对现有的S3兼容存储桶启用对象锁,请将值为1的x-amz-bucket-object-lock-token标头添加到S3 Put Object Lock Configuration API调用中。
不出所料,四个结果中有三个是来自关于对象锁的主要文档文章的摘录。
为了提供对话体验,RAG应用程序在消息存储库中保存聊天历史记录。RAG应用程序检索消息历史记录(4),并将其作为查询的一部分(将发送给LLM)。步骤2和步骤4(从向量存储库检索数据和从消息存储库检索数据)可以同时执行,因为它们彼此互不依赖。
系统提示为LLM生成答案设定了指导原则。在RAG中,系统提示通常规定答案应该基于检索到的文档数据,而非模型记忆,并尝试通过确保模型在未找到相关文档的情况下不会捏造信息来防止出现幻觉。以下是 RAG应用程序中的系统提示:
Use the following pieces of context and the message history to answer the question at the end. If you don't know the answer, just say that you don't know; don't try to make up an answer.
RAG 将系统提示、上下文、对话中的最后几条消息以及用户的问题提交给LLM(5),LLM会生成一个但愿有所帮助的答案(6)。以下是它对上述问题的回答:
对象锁是一项允许用户强制云存储中存储的文件不可更改的功能。以下是关于对象锁的几个要点:
- 不可变性:文件锁定后,在指定的保留期到期或合法保留解除之前,无法修改或删除。
- 保留期:用户可以在锁定文件时设置保留期。在此期间,文件将保持不可变状态,这意味着文件无法更改或删除。
- 合法保留:用户可以将文件置于合法保留状态,这将无限期地阻止修改或删除,直到保留被解除。
- 启用对象锁:可以为新存储桶或现有存储桶启用对象锁,但必须在上传文件之前在存储桶层面加以启用。
- 集成:一些应用程序(比如Veeam Backup和Replication)内置了对象锁支持,方便了希望确保备份期间文件不可变的用户。
- 无需额外费用:使用对象锁无需额外费用,然而锁定的文件仍需支付标准的存储费用。
- 锁定错误:如果用户锁定文件的时间超过预期,可能需要联系支持人员以解决问题,在某些情况下,这可能需要关闭存储帐户。
总之,对于需要确保数据完整性并遵守数据保留相关法规的组织而言,对象锁是一项至关重要的功能。
RAG应用程序将用户的问题和LLM的回复添加到消息存储库(7),将答案返回给用户(8),然后等待下一个问题。
示例应用程序一览
示例应用程序已发布在GitHub上。该应用程序是开源的,采用MIT许可证,因此你可以不受任何限制地将其用于试验。该应用程序使用与S3兼容的API,因此它可以与任何与S3兼容的对象存储库兼容。
请注意,与任何与一个或多个云服务提供商(CSP)集成的示例应用程序一样,运行该示例应用程序时可能会产生费用,包括存储数据和从CSP下载数据的费用。下载费用通常名为“出站费”,可能很快就会超过存储数据的费用。AI应用程序通常会集成多家专业提供商的功能,因此你应该仔细检查云存储提供商的定价,免得月底收到账单时大吃一惊。货比三家,几家专业的云存储提供商提供慷慨的每月免费出站流量限额,最高可达存储数据量的三倍,有的存储提供商还为合作伙伴提供无限量的免费出站流量。
README文件详细介绍了配置和部署;我在本文中将作一概述。该示例应用程序使用 Python和Django Web框架编写而成。API凭据和相关设置通过环境变量来配置,而LLM和向量存储库通过Django的settings.py文件来配置:
复制CHAT_MODEL: ModelSpec = {
'name': 'OpenAI',
'llm': {
'cls': ChatOpenAI,
'init_args': {
'model': "gpt-4o-mini",
}
},
}
# Change source_data_location and vector_store_location to match your environment
# search_k is the number of results to return when searching the vector store
DOCUMENT_COLLECTION: CollectionSpec = {
'name': 'Docs',
'source_data_location': 's3://rag-app-bucket/pdfs',
'vector_store_location': 's3://rag-app-bucket/vectordb/docs/openai',
'search_k': 4,
'embeddings': {
'cls': OpenAIEmbeddings,
'init_args': {
'model': "text-embedding-3-large",
},
},
}示例应用程序经配置后,使用OpenAI GPT-4o mini。不过,README文件解释了如何通过Ollama框架使用不同的在线LLM,比如DeepSeek V3 或Google Gemini 2.0 Flash,甚至像Meta Llama 3.1这样的本地LLM。如果你确实运行本地LLM,务必选择适合你硬件的模型。我尝试在搭载M1 Pro CPU的MacBook Pro上运行Meta的Llama 3.3,它有700亿个参数(70B)。仅仅回答一个问题花了将近3个小时!Llama 3.1 8B适合得多,不到30秒就能回答问题。
请注意,文档集合配置了向量存储库的位置,该存储库包含技术文档库作为示例数据集。README文件包含一个应用程序密钥,该密钥对PDF和向量存储库拥有只读访问权限,因此你无需加载自己的文档集即可试用该应用程序。
如果你想使用文档集合,一对自定义命令允许你将它们从云对象存储加载到向量存储库中,然后查询向量存储库以测试一切是否正常。
首先,你需要加载数据:
复制% python manage.py load_vector_store Deleting existing LanceDB vector store at s3://rag-app-bucket/vectordb/docs Creating LanceDB vector store at s3://rag-app-bucket/vectordb/docs Loading data from s3://rag-app-bucket/pdfs in pages of 1000 results Successfully retrieved page 1 containing 618 result(s) from s3://rag-app-bucket/pdfs Skipping pdfs/.bzEmpty Skipping pdfs/cloud_storage/.bzEmpty Loading pdfs/cloud_storage/cloud-storage-add-file-information-with-the-native-api.pdf Loading pdfs/cloud_storage/cloud-storage-additional-resources.pdf Loading pdfs/cloud_storage/cloud-storage-api-operations.pdf ... Loading pdfs/v1_api/s3-put-object.pdf Loading pdfs/v1_api/s3-upload-part-copy.pdf Loading pdfs/v1_api/s3-upload-part.pdf Loaded batch of 614 document(s) from page Split batch into 2758 chunks [2025-02-28T01:26:11Z WARN lance_table::io::commit] Using unsafe commit handler. Concurrent writes may result in data loss. Consider providing a commit handler that prevents conflicting writes. Added chunks to vector store Added 614 document(s) containing 2758 chunks to vector store; skipped 4 result(s). Created LanceDB vector store at s3://rag-app-bucket/vectordb/docs. "vectorstore" table contains 2758 rows
不要被“不安全的提交处理程序”警告吓倒,我们的示例向量存储库永远不会接收并发写入,因此不会发生冲突或数据丢失。
现在,你可以通过查询向量存储库来验证数据是否已存储。请注意来自向量存储库的原始结果包含一个标识源文档的S3 URI:
复制% python manage.py search_vector_store 'Which S3 API operation would I use to upload a file?'
2025-04-07 16:24:51,615 ai_rag_app.management.commands.search_vector_store INFO Opening vector store at s3://blze-ev-ai-rag-app/vectordb/docs/openai
2025-04-07 16:24:51,615 ai_rag_app.utils.vectorstore DEBUG Populating AWS environment variables from the b2-ev profile
Found 4 docs in 5.25 seconds
2025-04-07 16:24:57,386 ai_rag_app.management.commands.search_vector_store INFO
page_cnotallow='b2_list_parts b2_list_unfinished_large_files b2_start_large_file b2_update_file_legal_hold b2_update_bucket b2_upload_file b2_update_file_retention b2_upload_part S3-Compatible API To go directly to the detailed S3-Compatible API operations, click here. To learn more about using the S3-Compatible API, click here. API Operations Object Operations S3 Copy Object S3 Delete Object S3 Get Object S3 Get Object ACL S3 Get Object Legal Hold S3 Get Object Retention S3 Head Object S3 Put Object S3 Put Object ACL S3 Put Object Legal Hold S3 Put Object Retention S3 Abort Multipart Upload S3 Complete Multipart Upload S3 Create Multipart Upload S3 Upload Part S3 Upload Part Copy S3 List Multipart Uploads Bucket Operations S3 Create Bucket S3 Delete Bucket S3 Delete Bucket CORS S3 Delete Bucket Encryption S3 Delete Objects S3 Get Bucket ACL S3 Get Bucket CORS S3 Get Bucket Encryption S3 Get Bucket Location S3 Get Bucket Versioning' metadata={'source': 's3://blze-ev-ai-rag-app/pdfs/cloud_storage/cloud-storage-api-operations.pdf'}
...示例应用程序的核心是RAG类。几种方法可以创建RAG的基本组件,但在这里我们将介绍_create_chain() 方法如何使用开源LangChain AI框架,将系统提示、向量存储库、消息历史记录和LLM整合在一起。
首先,我们定义系统提示,包含上下文的占位符——RAG 将从向量存储库检索的那些文本块:
复制# These are the basic instructions for the LLM
system_prompt = (
"Use the following pieces of context and the message history to "
"Answer the question at the end. If you don't know the answer, "
"just say that you don't know, don't try to make up an answer. "
"\n\n"
"Context: {context}"
)然后,我们创建一个提示模板,将系统提示、消息历史记录和用户问题组合在一起:
复制# The prompt template brings together the system prompt, context, message history and the user's question
prompt_template = ChatPromptTemplate(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="history", optinotallow=True, n_messages=10),
("human", "{question}"),
]
)现在,我们使用LangChain表达式语言(LCEL)将各个组件组成一个链。LCEL允许我们以声明式的方式定义组件链;也就是说,我们提供所需链的大体表示,而不是指定组件应如何链接在一起:
复制# Create the basic chain
# When loglevel is set to DEBUG, log_input will log the results from the vector store
chain = (
{
"context": (
itemgetter("question")
| retriever
| log_data('Documents from vector store', pretty=True)
),
"question": itemgetter("question"),
"history": itemgetter("history"),
}
| prompt_template
| model
| log_data('Output from model', pretty=True)
)注意log_data()辅助方法,它仅仅记录其输入数据,并将其传递给链中的下一个组件。
为链分配名称使我们能够在调用它时添加检测机制。你将在本文后面看到我们如何添加一个回调处理程序,该处理程序将执行该链所花费的时间注释到链的输出中:
复制# Give the chain a name so the handler can see it named_chain: Runnable[Input, Output] = chain.with_config(run_name="my_chain")
现在,我们使用LangChain的RunnableWithMessageHistory类来管理从消息存储库添加和检索消息。Django框架为每个用户分配会话ID,我们使用它作为存储和检索消息历史记录的键:
复制# Add message history management return RunnableWithMessageHistory( named_chain, lambda session_id: RAG._get_session_history(store, session_id), input_messages_key="question", history_messages_key="history", )
最后,log_chain()函数将链的ASCII表示打印输出到调试日志中。请注意,即使不使用session_id,我们也必须提供预期的配置:
复制log_chain(history_chain, logging.DEBUG, {"configurable": {'session_id': 'dummy'}})这是输出——它提供了直观的图示,表明了数据如何在链中流动:
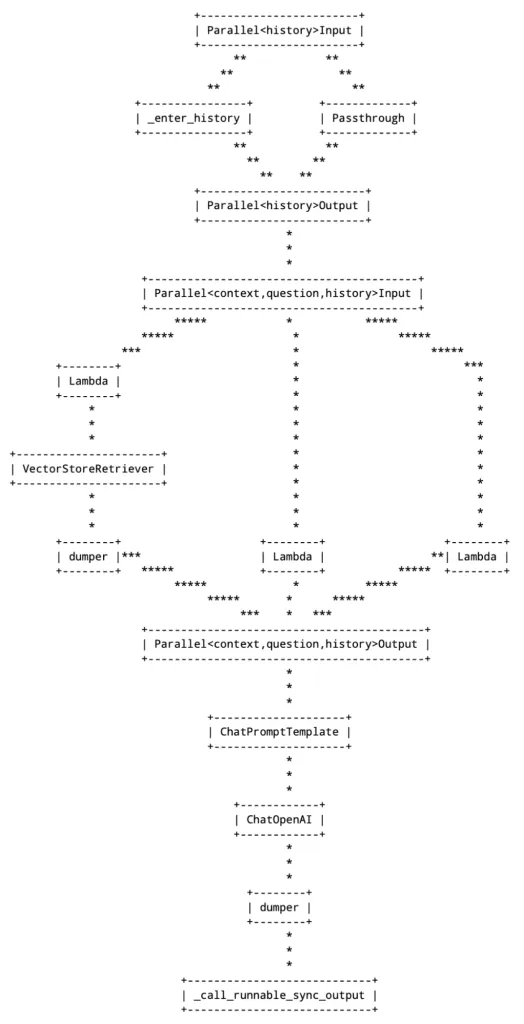
转储器组件由log_data()辅助方法插入,用于将沿链传递的数据记入日志。相比之下,Lambda组件由itemgetter()方法插入,用于从传入的Python字典中提取元素。
RAG类的invoke()函数用于响应用户的问题,非常简单。以下是代码的关键部分:
复制response = self._chain.invoke(
{"question": question},
cnotallow={
"configurable": {
"session_id": session_key
},
"callbacks": [
ChainElapsedTime("my_chain")
]
},
)链的输入是一个包含问题的Python字典,而config参数使用Django会话密钥和回调函数配置链,该回调函数用执行时间注释链的输出。由于链输出包含Markdown格式,因此处理来自前端请求的API端点使用开源markdown-it库将输出渲染为HTML以供显示。
其余代码主要涉及渲染Web UI。一个有趣的方面是,负责在页面加载时渲染UI的 Django视图使用RAG的消息存储库来渲染对话,因此如果你重新加载页面,也不会丢失上下文。
运行此代码!
如上所述,示例AI RAG应用程序是开源的,采用MIT许可证,我鼓励你将其用来探索RAG。README文件建议了几种扩展方法,如果你考虑在生产环境中运行该应用程序,也请你注意README的结尾部分:
[…]为了让你快速上手,我们通过几种方式简化了应用程序。如果你希望在生产环境中运行该应用程序,需要注意以下几点:
- 该应用程序不使用数据库来存储用户帐户或任何其他数据,因此无需身份验证。所有访问都是匿名的。如果你希望用户登录,则需要将Django的AuthenticationMiddleware类恢复到MIDDLEWARE配置,并配置数据库。
- 会话存储在内存中。如上所述,你可以使用Gunicorn将应用程序扩展为多线程,但你需要配置Django会话后端才能在多个进程中或多个主机上运行应用程序。
- 同样,对话历史记录存储在内存中,因此你需要使用持久化消息历史记录实现机制(比如 RedisChatMessageHistory)才能在多个进程中或多个主机上运行应用程序。
最重要的是,玩得开心!AI是一项迅猛发展的技术,厂商和开源项目每天都在发布新功能。但愿你觉得这个应用程序是不错的入门工具。
原文标题:A Practical Guide To Building a RAG-Powered Chatbot,作者:Pat Patterson


