大家好,我是小寒
今天给大家分享机器学习中的一个关键概念,SHAP
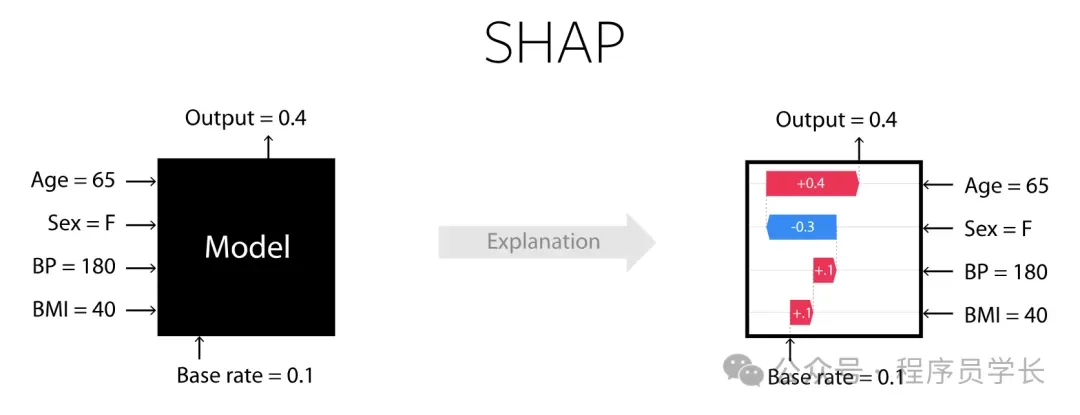
SHAP 是一种用于解释机器学习模型输出的统一框架。它基于博弈论中的 Shapley 值,用来量化每个特征对模型预测结果的贡献度。帮助我们理解模型为什么做出这样的预测。
简单来说,SHAP 计算每个特征在不同特征组合中对预测的边际贡献,从而为复杂模型提供透明、可解释的输出。
SHAP 的核心原理
SHAP 的理论基础来源于合作博弈论中的 Shapley 值。
在合作博弈论中,Shapley 值用于公平地分配合作者在合作中所产生的总收益。
SHAP 将这一思想巧妙地应用到机器学习模型的特征贡献分配上。
- 参与者:对应机器学习中的特征。
- 合作收益:对应模型的预测结果。
- 目标:计算每个特征对预测结果的边际贡献,即该特征加入模型后带来的增益。
在 SHAP 中,模型预测值被视为总收益,而每个特征则被视为一个参与者。SHAP 值就是计算每个特征在所有可能的特征组合中对预测的平均边际贡献,从而解释了为什么模型会做出某个特定的预测。
为什么要用 SHAP
在现实世界的应用中,很多机器学习模型,尤其是复杂的模型(如深度学习、集成树模型),往往被称为“黑箱”模型。
这意味着我们知道它们能做出预测,但很难理解它们为什么会做出某个特定的预测。
这种缺乏透明度会带来许多问题:
- 信任问题:用户和利益相关者可能不信任模型的决策,尤其是在高风险领域(如医疗诊断、金融信贷)。
- 调试与改进:当模型表现不佳时,我们难以定位问题出在哪里,是数据问题还是模型本身的问题?哪个特征导致了错误的预测?
- 公平性与偏见:模型是否基于不公平或有偏见的特征做出了决策?SHAP 可以帮助我们识别潜在的偏见。
- 合规性:在某些行业,解释模型决策是法规要求。
SHAP 的出现,为解决这些问题提供了强大的工具,它能够提供:
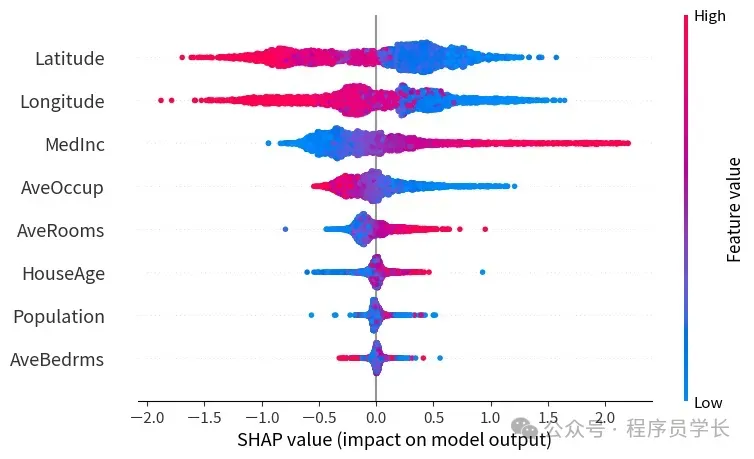
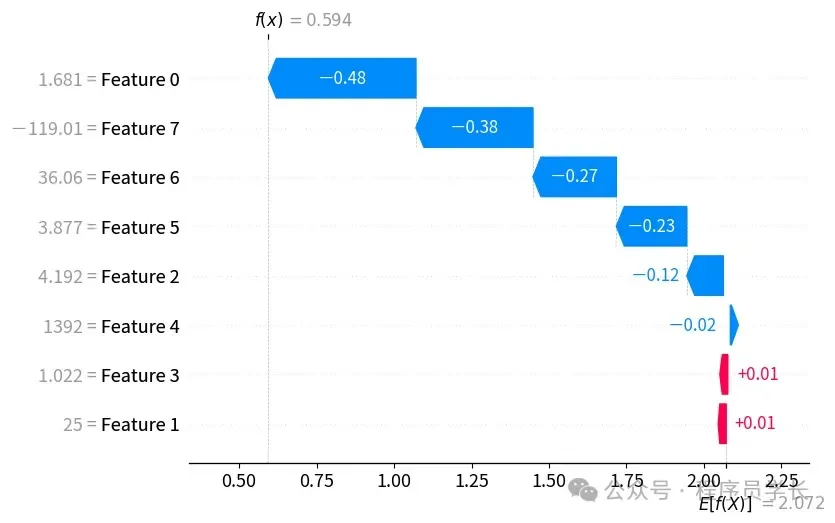
- 局部可解释性解释单个预测是如何形成的。例如,为什么一个特定的客户被预测为“流失”?哪些特征导致了这个结果?
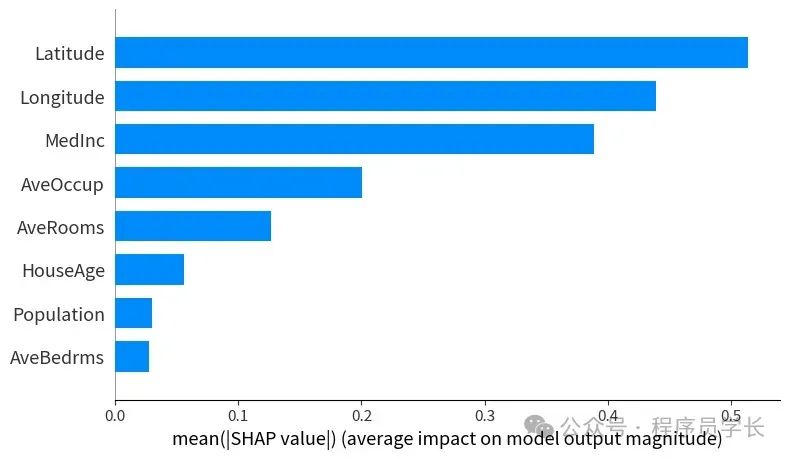
- 全局可解释性理解整个模型的行为。哪些特征对模型的整体预测贡献最大?特征之间是否存在交互作用?
数学公式

可加性解释模型
SHAP 提出了一种“可加性解释模型”的概念,即任何复杂的模型预测都可以被解释为基线值与特征贡献的加和

计算 SHAP 值的近似方法
由于直接计算 Shapley 值涉及到遍历所有可能的特征组合,计算复杂度为 O(2n),这在特征数量较多时会面临组合爆炸的问题。
因此,SHAP 提出了多种近似算法来提高计算效率
- Kernel SHAP这是一种模型无关的 SHAP 算法,通过训练一个加权线性回归模型来近似 Shapley 值。它使用一个特殊的核函数来给不同的特征组合赋权重,使得与目标预测更相似的组合具有更高的权重。
- Tree SHAP专为树模型(如决策树、随机森林、XGBoost、LightGBM)设计的优化算法。Tree SHAP 利用树模型的结构特性,可以比 Kernel SHAP 更高效、更精确地计算 Shapley 值。
- Deep SHAP针对深度学习模型设计的算法。它通过反向传播 Shapley 值来解释神经网络的输出。
案例分享
下面是一个 Python 示例代码,展示如何用 SHAP 库来解释一个简单的模型预测。
复制