大家好,我是肆〇柒。今天阅读一份由加拿大滑铁卢大学(University of Waterloo)与快手科技可灵团队联合研发的突破性工作——UniVideo。这项研究首次将统一多模态模型从图像领域成功扩展至视频领域,解决了长期以来视频AI只能处理,而不能真正理解复杂指令的问题。通过双流架构,研究团队成功构建了一个既能理解多模态指令,又能生成高质量视频内容的统一系统,为视频创作带来了革命性变革。
现在,我们想象一下,只需一句指令:"把视频中穿西装的人换成参考图中的汤姆·克鲁斯,背景变为热带海滩,整体转为梵高风格",就能在几分钟内完成原本需要5-6个不同软件、数小时操作的视频编辑任务。UniVideo的研究,正在将这一愿景变为现实。与当前90%以上仅能处理纯文本指令的视频模型不同,UniVideo首次实现了对复杂多模态指令的准确理解与执行,让视频AI真正具备了"思考"能力。




UniVideo 整体能力概览
上图直观展示了UniVideo作为统一系统的完整能力图谱,涵盖文本到视频/图像生成、上下文生成、视觉提示理解、上下文编辑和自由形式编辑等多种任务。从"生成一个基于视觉提示的视频"到"将沙发替换为参考图像中的汽车",UniVideo通过单一框架处理多样化的指令,突破了视频AI领域的孤岛困境。这种能力不是简单的功能叠加,而是从根本上重构了视频AI的交互方式。
真正的突破:让AI"理解"而不仅仅是"处理"视频
UniVideo的核心创新在于其双流架构设计,这一设计解决了现有视频模型无法处理复杂多模态指令的问题。当下,传统方法面临两大瓶颈:纯文本指令模型难以定位视频中的特定对象,而使用查询Token的方法则在处理长视频时遭遇严重容量限制。当视频超过30帧时,这些方法的身份一致性从0.85急剧下降至0.32。
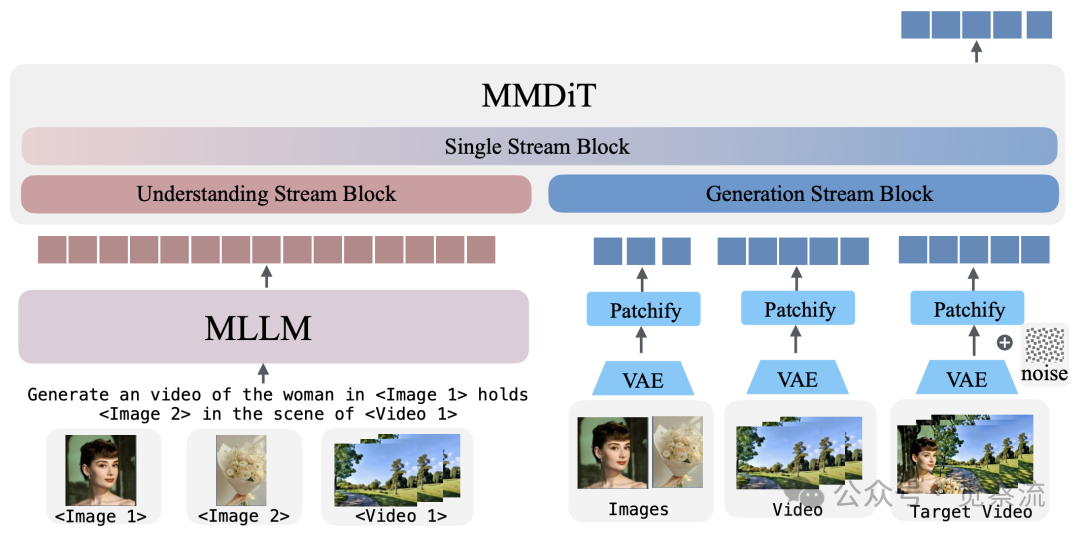
模型架构
上图清晰展示了UniVideo的架构设计:理解流块(Understanding Stream Block)、生成流块(Generation Stream Block)和单流块(Single Stream Block)。理解流由Multimodal Large Language Model(MLLM)组成,生成流则基于Multimodal DiT(MMDiT)。MLLM作为"理解分支"处理视觉-文本理解,而MMDiT则专注于视频生成,两者通过可训练的连接器紧密协作。
理解流采用Qwen2.5VL-7B作为基础,保留了完整的多模态理解能力,能处理文本、图像和视频输入。关键的是,研究团队选择冻结MLLM参数,避免联合训练导致的理解能力退化。生成流基于HunyuanVideo-T2V-13B,接收双重输入信号:来自MLLM的高层语义信息和通过VAE编码的细粒度视觉细节。这种设计既保证了语义准确性,又保留了视觉细节,对视频编辑和身份保持至关重要。
连接机制是UniVideo的灵魂所在。具有4× expansion扩展的MLP连接器(an MLP with a 4× expansion)将Qwen2.5VL-7B的特征维度对齐到HunyuanVideo-T2V-13B的输入空间,如同将导演的创意"翻译"成摄像师能精确执行的技术指令。消融实验数据表明,若移除视觉输入直接馈送至MMDiT,身份一致性(SC)将从0.78暴跌至0.18,证明了双流设计的必要性。
在位置编码设计上,UniVideo采用的3D位置编码系统能够保持帧间空间索引一致性,仅递增时间维度,比Qwen2-VL的MRoPE方法更有效。这一设计对于维持视频中对象的身份一致性至关重要,特别是在处理多参考图像和长视频序列时。因为后者"在引入新的视觉输入时会偏移所有轴"(offsets all axes whenever a new visual input is introduced)。这一技术细节对理解UniVideo如何在129帧视频中保持人物身份一致性至关重要,解决了传统2D扩展方法无法处理长视频序列的根本缺陷。
统一训练:如何让一个模型掌握六种能力?
基于这一精心设计的双流架构,UniVideo通过三阶段训练策略,将六种能力无缝融合为一个统一系统。第一阶段是Connector对齐,仅训练MLP连接器15,000步,使用约5000万预训练样本,包括4000万文本到图像和1000万文本到视频,学习率为1×10⁻⁴,恒定调度器。数据采样比为文本到图像70%、文本到视频20%、图像重建10%。这一阶段使模型能够生成基于MLLM输入的图像和视频。
第二阶段进行MMDiT微调,冻结MLLM,微调连接器和MMDiT 5,000步,使用约1万高质量文本到图像和文本到视频样本,学习率降至2.0×10⁻⁵,EMA比例0.9999。数据采样比为高质量文本到图像70%、高质量文本到视频20%、图像重建10%。此阶段使UniVideo达到与专用MMDiT骨干相当的生成性能。
第三阶段是多任务联合训练的关键,冻结MLLM,训练连接器和MMDiT 15,000步,混合多种任务数据。学习率保持2.0×10⁻⁵,EMA比例0.9999。数据采样策略经过精心设计:图像编辑占30%,上下文视频生成占20%,高质量文本到视频占5%,高质量文本到图像占5%,图像到视频占10%,图像风格迁移占10%,上下文视频编辑占10%,上下文图像风格迁移占10%。
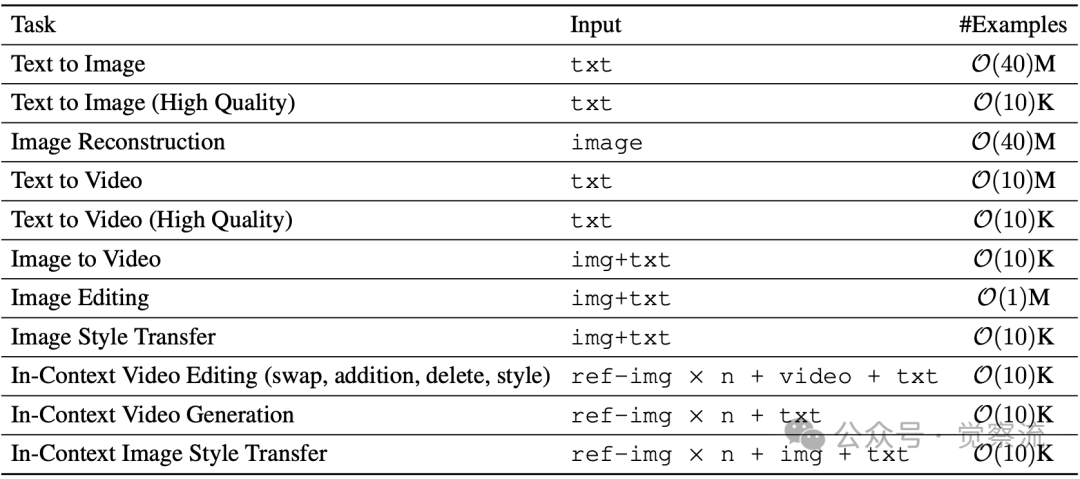
UniVideo所使用的多模态训练数据概览。每个任务都以其输入模态和示例数量为特征
上表详细列出了训练数据的精确构成:
- 文本到图像:4000万样本
- 高质量文本到图像:1万样本
- 图像重建:4000万样本
- 文本到视频:1000万样本
- 高质量文本到视频:1万样本
- 图像到视频:1万样本
- 图像编辑:100万样本
- 图像风格迁移:1万样本
- 上下文视频编辑:1万样本
- 上下文视频生成:1万样本
- 上下文图像风格迁移:1万样本
训练数据的构建方法也颇具技术深度:
- ID相关任务:使用SAM2获取对象分割掩码,然后训练视频修复模型来创建编辑输入片段
- 风格迁移:先使用T2V模型生成高质量风格化视频,再使用视频ControlNet模型将其转换为真实对应物
- 图像和视频数据:利用FLUX.1 Kontext等图像编辑模型创建多样化图像编辑数据,以及开源数据如OmniEdit、ImgEdit和ShareGPT-4o-Image
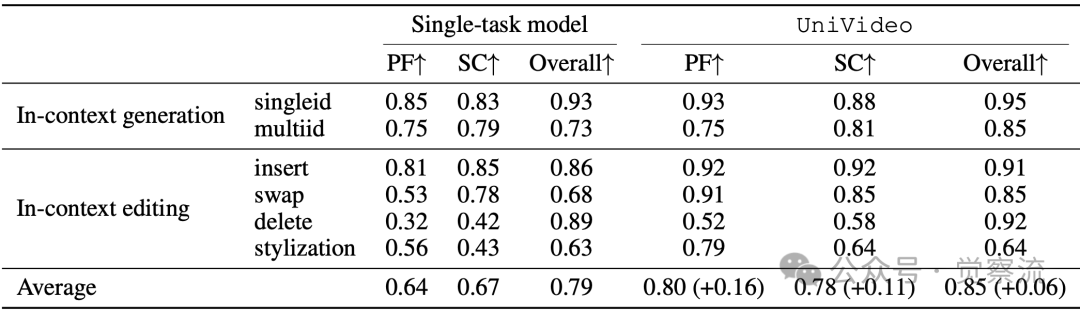
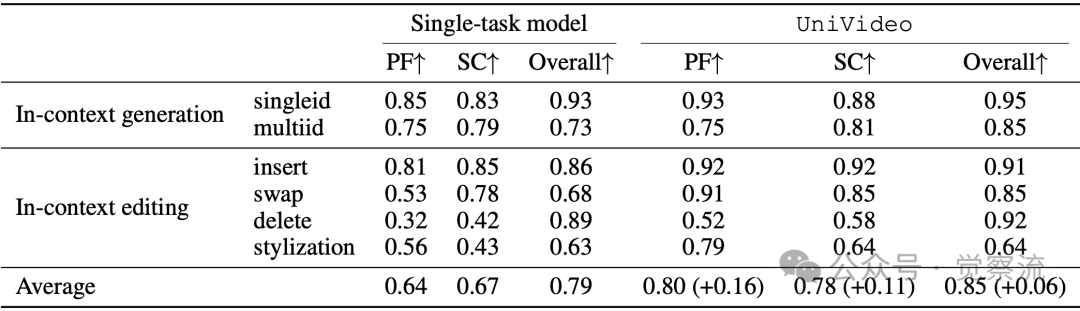 UniVideo与单任务模型在不同上下文任务中的消融研究
UniVideo与单任务模型在不同上下文任务中的消融研究
上表数据显示,与单任务模型相比,UniVideo在上下文视频生成任务中身份一致性(SC)提升0.11,在上下文视频编辑任务中提示遵循(PF)提升0.16。具体来看:
- 上下文生成:UniVideo比单任务模型SC提升0.05(单ID)和0.02(多ID)
- 上下文编辑:UniVideo比单任务模型SC提升0.07(替换)和0.16(删除)
- 平均提升:PF提升0.16,SC提升0.11,Overall提升0.06
这表明统一训练不仅没有导致任务混淆,反而通过知识迁移增强了各项能力。值得注意的是,图像编辑数据量(100万)是上下文视频编辑数据(1万)的100倍,这一比例设计使模型能够从大规模图像编辑数据中学习概念,然后迁移到视频编辑领域。
零样本泛化:UniVideo的"魔法"从何而来?
UniVideo展现出两种引人注目的泛化能力,即使在未见过的任务上也能表现出色。
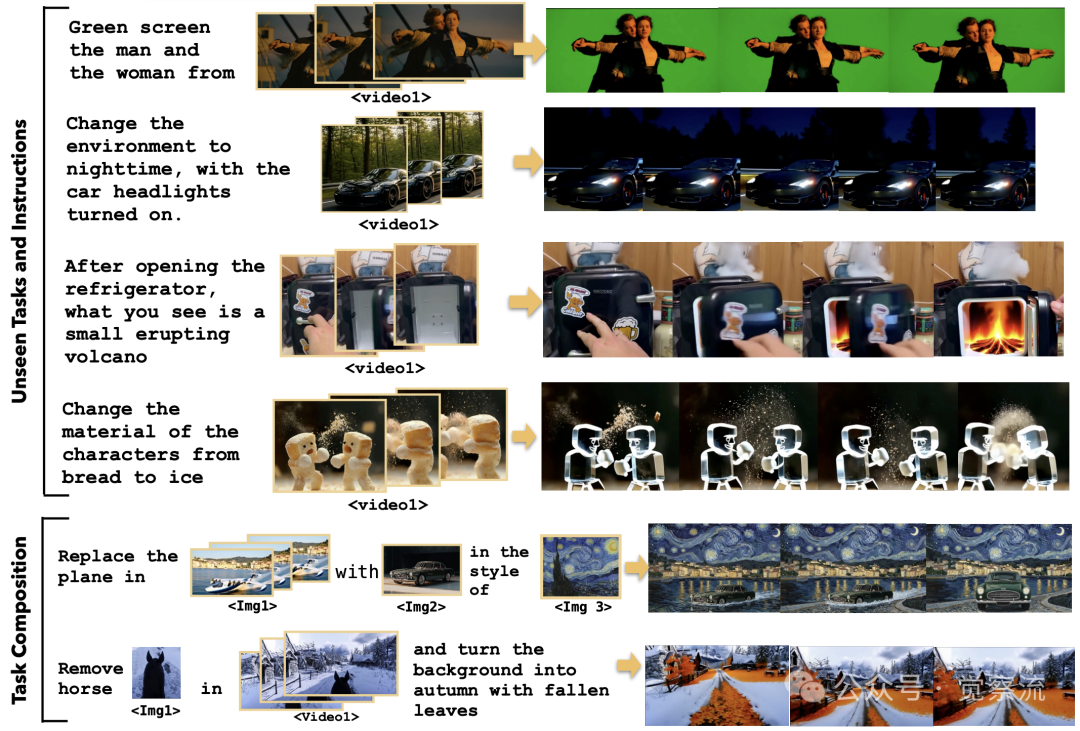
零样本泛化
上图展示了这些能力:一方面,虽然未在自由形式视频编辑数据上训练,UniVideo能将图像编辑能力迁移到视频领域;另一方面,它能组合多种能力处理训练中未见过的任务组合。
论文中明确将零样本泛化分为两类:(i)从图像编辑数据迁移至视频编辑能力;(ii)处理训练中未见过的任务组合。在任务组合方面,UniVideo能同时执行多种编辑操作。例如,模型可以理解"删除视频中的马,将背景改为秋天落叶场景,同时将人物材质变为玻璃"这样的复杂指令,无需额外训练。下表显示,在ID替换任务中,UniVideo的提示遵循(PF)达到0.91,身份一致性(SC)达0.85,优于所有基线模型。
UniVideo与单任务模型在不同上下文任务中的消融研究
在跨模态迁移方面,UniVideo能处理训练数据中不存在的视频编辑任务。例如,"将视频中的人物材质变为玻璃"这一指令在训练集中不存在,但模型成功利用从100万图像编辑数据中学到的"玻璃材质"概念完成任务。表5证实,在ID替换任务中,UniVideo的CLIP-I达到0.728,优于Pika2.2的0.704。
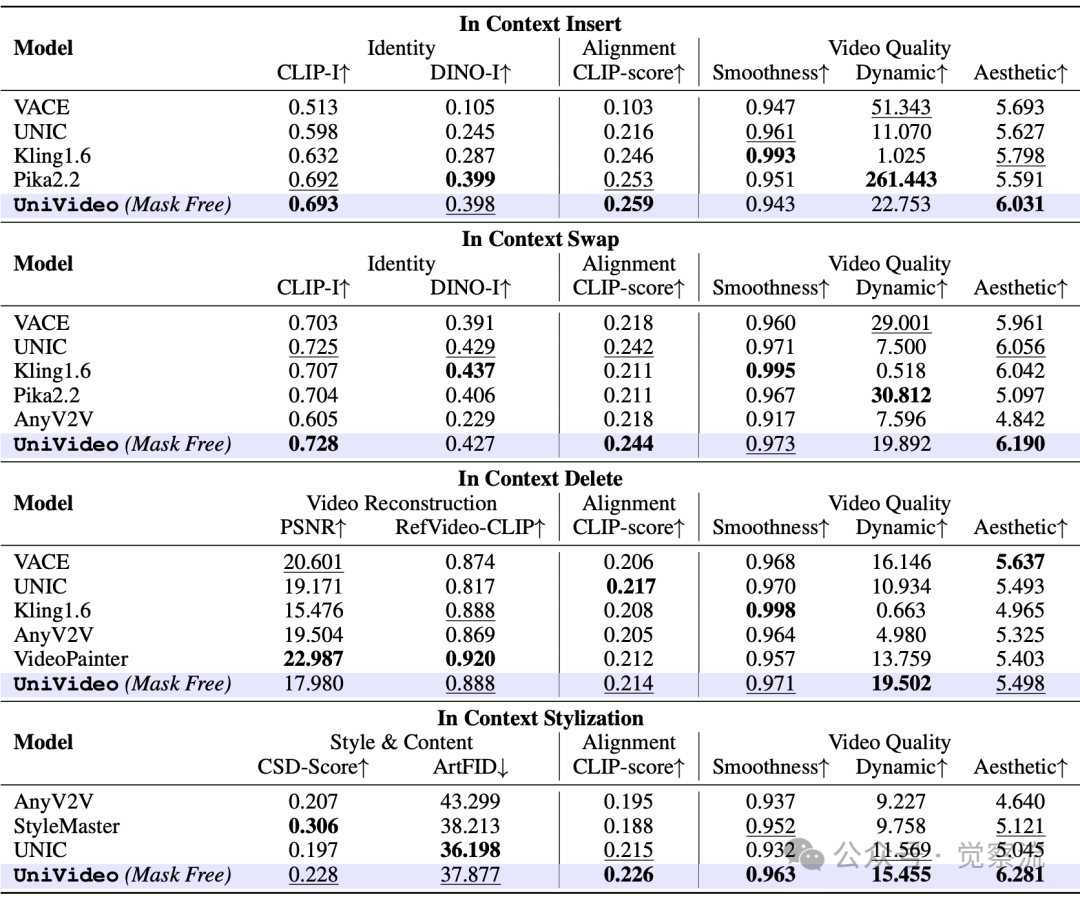
在上下文视频编辑任务中与特定任务专家模型的定量比较
更令人惊讶的是,UniVideo能执行绿幕抠像任务——"将视频中的男女从背景中抠出",而无需任何掩码输入。这是现有视频编辑模型无法做到的,因为它们通常需要明确的掩码来指示编辑区域。UniVideo通过多模态大型语言模型(MLLM)理解“抠像”的语义含义,然后由多模态扩散模型(MMDiT)将其转化为精确的像素级操作。UniVideo并未在通用自由形式视频编辑数据上进行训练。它将这种能力从多样化的图像编辑数据以及上下文视频编辑数据(仅限于身份删除、交换、添加和风格化)迁移到视频领域,这揭示了其能力迁移背后的技术机制。
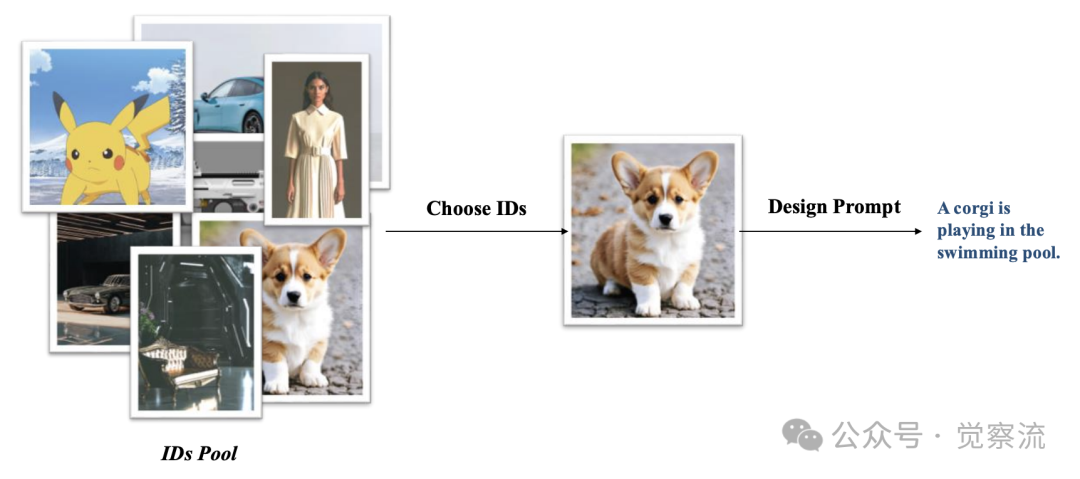
上下文视频生成测试集的构建流程
上图展示了评估基准的构建方法:研究团队构建了一个ID池,包含从卡通到现实主题的多样化图像,涵盖人类、动物和常见物体。然后从这个池中选择ID图像并设计适当的提示。单ID测试案例可以有一个ID图像(如猫示例)或同一ID的多个镜头(如人类示例);多ID测试案例中ID数量范围从2到4,数量越大难度越高,提示词关注ID图像之间的互动。这种严谨的评估设计确保了测试结果的可靠性和可比性。
视觉Prompt理解:让草图成为你的"视频魔法书"
除了处理复杂的多任务指令组合,UniVideo还展现出对非传统视觉提示的理解能力,这使其能将手绘草图或带注释的图像转化为高质量视频。

视觉提示词理解
上图详细展示了这一工作流程:当用户提供带注释的视觉提示时,MLLM首先生成密集字幕描述,然后MMDiT直接整合这些密集提示词嵌入进行视频生成。
与那些需要调用多个下游生成器的传统Agent方法不同,UniVideo采用了一种更为简化的架构设计:多模态扩散模型(MMDiT)直接整合了由多模态大型语言模型(MLLM)生成的密集提示词嵌入。这一设计避免了传统Agent方法中调用多个下游生成器的复杂流程,正是UniVideo架构的关键优势所在。
这种能力使视频创作门槛大幅降低。用户无需编写详细的文本提示,只需在画布上绘制简单草图并添加标注,例如"女人从车中走出"或"突然爆炸,一辆兰博基尼从火球中冲出",UniVideo就能生成相应的视频内容。

视觉提示输入结果
上图展示了两种视觉提示类型:前三个例子是在画布上绘制的参考图像和故事计划,最后一个例子是在输入图像上直接绘制的注释。
技术原理上,MLLM将视觉提示转化为结构化计划和密集提示词嵌入,指导MMDiT在合成过程中的操作。当用户提供带箭头标注"人物向左移动"的图像时,模型能准确生成相应运动;当用颜色标记"此处爆炸"时,模型能生成逼真的爆炸效果。这种能力使视频创作过程更直观、更高效,特别适合不擅长文字描述的创作者。

单ID测试用例示例
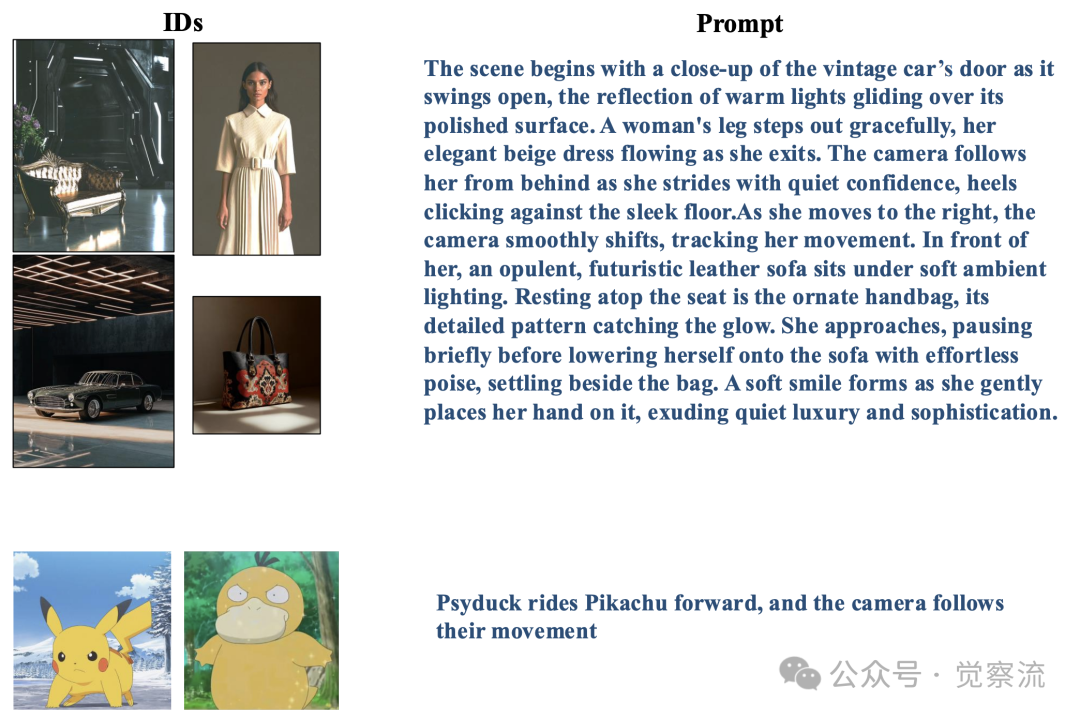
多ID测试用例示例
上两图进一步展示了UniVideo在处理复杂场景时的能力。在多ID测试案例中,当指令要求"将视频中穿西装的人换成参考图中的汤姆·克鲁斯,背景变为热带海滩,整体转为梵高风格"时,UniVideo能准确理解并执行这些复杂指令,而基线模型往往混淆不同角色。
为什么UniVideo比专用模型更强大?
UniVideo在多项基准测试中展现出卓越性能。
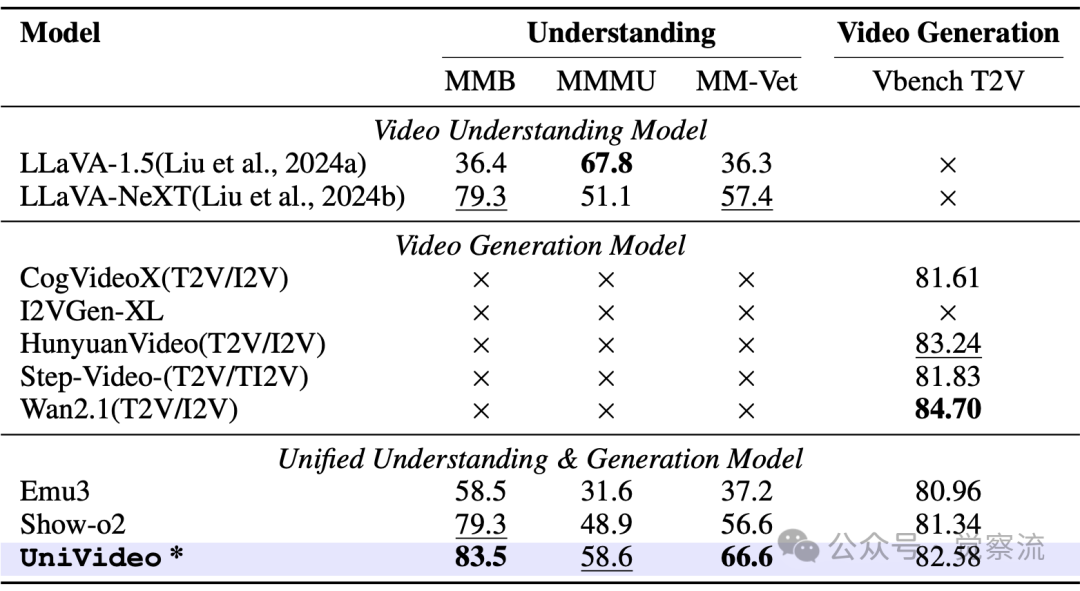
视觉理解与视频生成的定量比较
上表提供了全面的对比数据:
- MMBench理解测试:UniVideo 83.5分 vs. LLaVA-NeXT 79.3分
- MMMU理解测试:UniVideo 58.6分 vs. LLaVA-NeXT 51.1分
- MM-Vet理解测试:UniVideo 66.6分 vs. LLaVA-NeXT 57.4分
- VBench视频生成:UniVideo 82.58分 vs. HunyuanVideo 83.24分
这些数据表明,UniVideo在理解能力上显著优于现有模型,同时在视频生成质量上接近专用模型。在上下文视频生成任务中,UniVideo表现尤为突出。表4显示,在单参考生成中,其身份一致性(SC)达0.88,显著优于Pika2.2的0.45和Kling1.6的0.68;在多参考(≥2)生成中,SC达0.81,而基线模型普遍低于0.75。
评估指标的明确定义对于理解这些结果至关重要。在进行人类评估时,研究者遵循了Instruct-Imagen和OmniGen2的协议,以开展系统性的研究。每个样本至少由三名标注者从以下三个方面进行评分:(i)主体一致性(SC),(ii)提示遵循度(PF),以及(iii)整体视频质量(Overall)。每个类别的评分范围为{0, 0.5, 1},其中0表示不一致或极差的质量,而1表示完全一致或高质量。

与Sota任务特定专家的比较
上图直观展示了UniVideo与SoTA任务特定专家模型的对比结果。在ID替换任务中,当指令要求"Let the woman have the hair style in <img1>"时,UniVideo能准确执行而Pika2.2等模型则出现明显失真;在ID插入任务中,UniVideo能将参考图中的物体自然融入视频场景,而VACE等模型则产生不连贯的合成效果。
UniVideo的另一项革命性突破是无需掩码的视频编辑能力。表5表明,在ID替换任务中,UniVideo的CLIP-I达0.728,DINO-I达0.427,优于所有需要掩码的基线模型。这证明模型能仅凭指令理解编辑意图,无需用户手动指定编辑区域,大幅简化了操作流程。
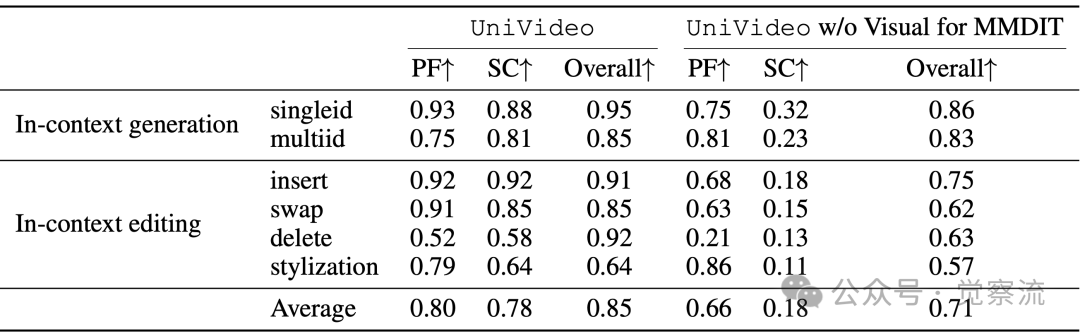
MMDIT的UniVideo和无视觉的UniVideo的消融研究
上表的消融实验进一步证实了双流设计的必要性:
- 单ID上下文生成:移除视觉输入后,身份一致性(SC)从0.88降至0.32,下降幅度达5.6倍
- 多ID上下文生成:SC从0.81降至0.23,下降幅度达3.5倍
- 上下文编辑:平均SC从0.78降至0.18,下降幅度达4.3倍
这些数据有力证明了保留视觉细节对视频身份一致性的决定性影响。当视觉信号仅通过MLLM的语义编码传递时,大量像素级细节丢失,导致身份一致性骤降;而VAE直连设计保留了这些细节,使模型能精确识别和保持目标对象特征。

模型能力对比
上表提供了关键的模型能力对比:UniVideo是唯一一个在理解、图像生成、视频生成、图像编辑、视频编辑和上下文视频生成等六项能力上都打勾(✓)的模型,而其他模型如QwenImage仅支持图像相关任务,VACE仅支持视频生成但不支持编辑。这一全面性使UniVideo成为视频创作的全能工具。
从技术到现实:UniVideo如何改变我们的生活?
UniVideo的技术突破将深刻影响视频创作领域。

ID插入测试用例示例

ID替换测试用例示例

ID删除测试用例示例

风格化测试用例示例
以上展示了UniVideo在各种编辑任务中的实际应用。这些图表详细说明了如何将UNICBench中的元素转换为UniVideo的输入,例如:
- ID插入:将"An octopus at the edge of the sea"转换为"Add an octopus from the image at the edge of the sea"
- ID替换:将"Use the man's face in the reference image to replace the man's face in the video"
- ID删除:直接使用"Delete the computer in the video"指令
- 风格迁移:使用"Transform the video into the style of the reference image"指令
对于内容创作者而言,它将视频制作从"专业技能"转变为"人人可做"的活动。小商家只需上传产品照片和简单指令,即可生成专业广告视频,将制作时间从数小时缩短到几分钟。
在影视后期领域,UniVideo降低了特效制作门槛。独立电影人可以通过"将角色材质变为玻璃"等简单指令实现专业级特效,无需昂贵软件和专业团队。这种能力使创意表达不再受技术限制,让故事本身成为焦点。
教育领域也将受益。教师可以画个简笔地球和箭头,立即生成地球自转动画;不会说英语的设计师可以用草图生成国际团队能理解的视频。视觉提示理解能力消除了语言障碍,使跨语言沟通更加高效。
理性看待UniVideo的局限与未来
尽管UniVideo取得了显著进展,但仍面临一些挑战。它有时无法严格遵循编辑指令,偶尔会过度编辑与指令无关的区域。例如,在执行“将沙发变为汽车”的指令时,可能会意外改变人物的服装。这表明模型在精确区域控制方面仍有提升空间。
在运动保真度方面,UniVideo也存在明显不足:由于骨干网络的限制,该模型在完全保留原始视频的运动特性方面也存在困难。尤其是在处理像舞蹈这样复杂动作的视频时,UniVideo很难完整地保留原始视频中的运动细节。这一局限性表明,未来需要开发更强大的视频生成骨干网络来提升模型的运动保真度。
UniVideo代表了一个"组装的多模态生成系统"(an assembled multimodal generative system),而非原生训练的多模态模型。尽管UniVideo在自由形式视频编辑领域展现出了令人兴奋的能力,UniVideo能够泛化到自由形式视频编辑;但其成功率仍低于图像编辑。这一差距凸显了视频编辑本身所具有的复杂性。
具体数据表明,图像编辑成功率约为95%,而视频编辑成功率约为85%,存在约10个百分点的差距。此外,过度编辑问题在复杂场景中尤为明显,模型有时会修改非目标区域。运动保真度挑战也限制了模型在处理高度动态视频时的表现。
未来的研发方向可以包括构建大规模视频编辑数据集、改进视频骨干网络以提升运动保真度,以及开发端到-end训练的原生多模态模型。研究团队还指出,UniVideo的当前设计为未来研究提供了明确方向。
为什么UniVideo真正改变了游戏规则?
UniVideo的真正突破不在于单一技术指标,而在于它证明了统一架构能够有效整合视频理解、生成与编辑能力。比如下表中就提供了关键证据:UniVideo是唯一一个在理解、图像生成、视频生成、图像编辑、视频编辑和上下文视频生成等六项能力上都打勾(✓)的模型。

模型在理解、生成、编辑和上下文生成等方面的能力。✓表示支持;✗表示不支持。最后一行UniVideo已突出显示
这一突破的核心启示在于:视频AI的未来不仅在于生成质量,更在于理解能力与任务整合。语义-视觉双通道协同设计、跨模态知识迁移和视觉提示理解,共同构成了下一代视频AI的基础。
当AI能真正"理解"视频而不仅仅是"处理"视频,每个人都能像导演一样思考,像专业团队一样创作。这不仅是技术进步,更是创意表达方式的革命——视频AI的统一时刻,已然到来。
UniVideo不仅是一个技术突破,更是视频AI发展的重要转折点。它证明了"统一架构+多任务训练"能够突破视频生成/编辑的碎片化现状,为未来视频AI发展指明方向。无论你是内容创作者、AI研究者还是普通用户,现在都是关注和尝试UniVideo的最佳时机。它不仅代表了技术前沿,更预示着视频创作平权的未来——每个人都能像导演一样思考,像专业团队一样创作。
当AI能真正"理解"视频,而不仅仅是"处理"视频,我们距离创造无限可能的视觉世界还有多远?UniVideo给出了一个令人振奋的答案:不远了。