相邻的 KV 缓存将合并为一个。在生成第一个字符时,KV 缓存长度为 1;生成第二个字符后,新生成的 KV 与前一个被合并,KV 缓存长度仍然保持为 1。这种动态合并机制有效压缩了时间维度上的冗余信息。
然而,这也带来了并行训练上的挑战:虽然两个时间步的 KV 缓存长度相同,但它们所包含的信息不同,若不加以区分,容易导致训练与推理行为不一致。
MTLA 通过一种优雅的方式解决了这一问题。正如下图所示,在训练阶段,MTLA 保留了所有中间状态的 KV 表达,并引入了步幅感知因果掩码(stride-aware causal mask),确保每个 query 在训练时访问到与推理阶段一致的 KV 区域,从而准确模拟增量推理中的注意力行为。
得益于这一设计,MTLA 能够像标准注意力机制一样通过矩阵乘法实现高效并行计算,在保持训练效率的同时完成对时间维度的压缩。
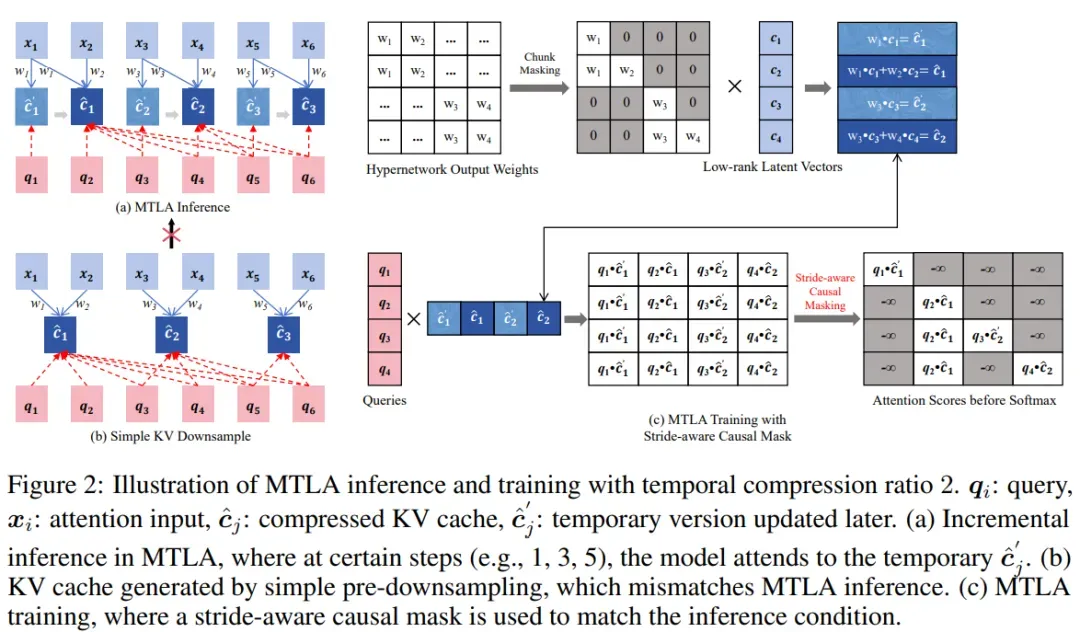
此外,MTLA 还引入了解耦的旋转位置编码(decoupled RoPE)来建模位置信息,并对其进行了时间维度上的压缩,进一步提升了整体效率。
值得强调的是,MTLA 不仅是一种更高效的自注意力机制,它还具备极强的灵活性与可调性。例如,当将时间压缩率 s 设置得足够大时,MTLA 在推理过程中几乎只保留一个 KV 缓存,这种形式本质上就退化为一种线性序列建模方法。换句话说,线性序列建模可以被视为 MTLA 的极端情况,MTLA 在注意力机制与线性模型之间架起了一座桥梁。
然而,在许多复杂任务中,传统注意力机制所具备的二次计算复杂度虽然代价高昂,却提供了更强的建模能力。因此,MTLA 所引入的 “可调时间压缩率 s” 这一设计思路,恰恰为模型提供了一个在效率与性能之间灵活权衡的可能空间。
MTLA 的卓越性能
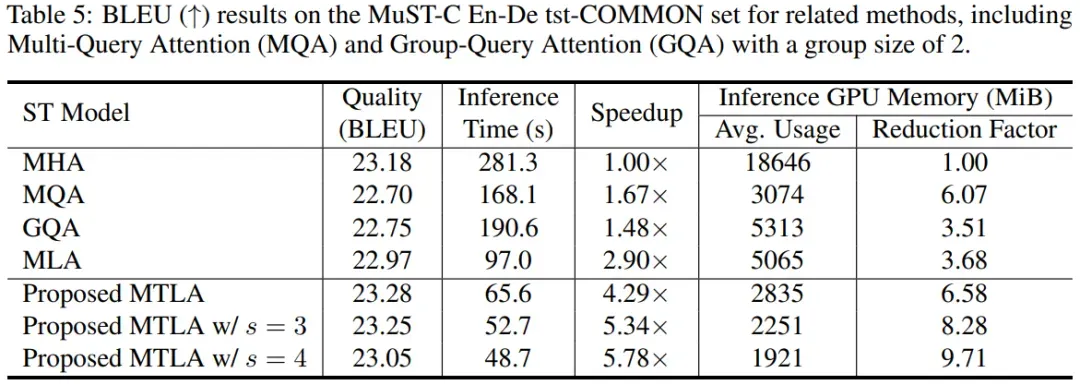
MTLA 在一系列任务中展现了出色的性能,包括语音翻译,文本摘要生成,语音识别和口语理解。例如在语音翻译中,MTLA 在保持与标准 MHA 相当的翻译质量的同时,实现了超过 5 倍的推理速度提升,并将推理过程中的 GPU 显存占用降低了超过 8 倍。
值得注意的是,仅当时间压缩率 s=2 时,MTLA 对 KV 缓存的压缩程度就已经与 MQA 相当,且在模型性能上更具优势。而相比之下,MQA 所采用的减少 KV 头数量的方法已达上限,而 MTLA 还有进一步的空间。
未来发展
MTLA 具备在大规模场景中部署的显著潜力,尤其是在大语言模型参数规模不断扩大、以及思维链等技术推动下生成序列日益增长的背景下,对 KV 缓存进行时空压缩正是缓解推理开销的关键手段。在这样的趋势下,MTLA 有望成为未来大语言模型中自注意力模块的重要替代方案。
当然,与 DeepSeek 提出的 MLA 类似,MTLA 相较于 GQA 和 MQA,在工程落地方面的改动不再是简单的一两行代码可以实现的优化。这也意味着要将其大规模应用到现有 LLM 框架中,还需要来自社区的持续推动与协同开发。
为促进这一过程,MTLA 的实现代码已全面开源,希望能够为研究者与工程实践者提供便利,共同推动高效注意力机制在大模型时代的落地与普及。


