
更多实测:
嗨大家好!我是阿真!
抢到首发了!
阿里发布了万相2.6系列模型。
其他的来不及猛猛测了,先上官方Demo
当视频在手机上无法加载,可前往PC查看。先说重点,主要更新点在下列几个方面:
- 国内首个支持“角色扮演”功能,可以参考形象和人物音色,参考形象可以是人物、动物或者物体;
- 单人表现双人合框都可以尝试,人物音色也可以匹配;
- 可以多个镜头智能调度了,可以在一致性统一的基础上智能分镜;
- 视频时长扩展,最长可以15秒了,分辨率最高1080P,叙事更完整,画面也更丰富了。
现在可以将人物、动物、物体设定为角色,然后基于参考素材生成表演视频了。在此前的AI视频生成技术框架中,我们只能通过文本描述或单张图片引导模型生成视频内容,无法精确控制视频中的角色形象。万相2.6现在也引入了「角色扮演」能力,从根本上改变了这一创作逻辑。
设定元素为视频主角后,轻松调用,模型会基于参考素材生成连续的表演内容。镜头也是有智能调度的分镜,这个后面会提到。
此外,还有一个亮点,万相2.6不仅能够提取参考视频和素材中的视觉特征,还能同步捕捉声音特征,确保了角色生成视频后在形象与声音两个维度上的一致性。现在处理多人同框对话的复杂场景的时候,角色的口型动作与各自的语音内容都能精确地对应了。
使用起来很简单,在这里直接录制或上传自己录制的视频,然后通过@ 就可以调用了。
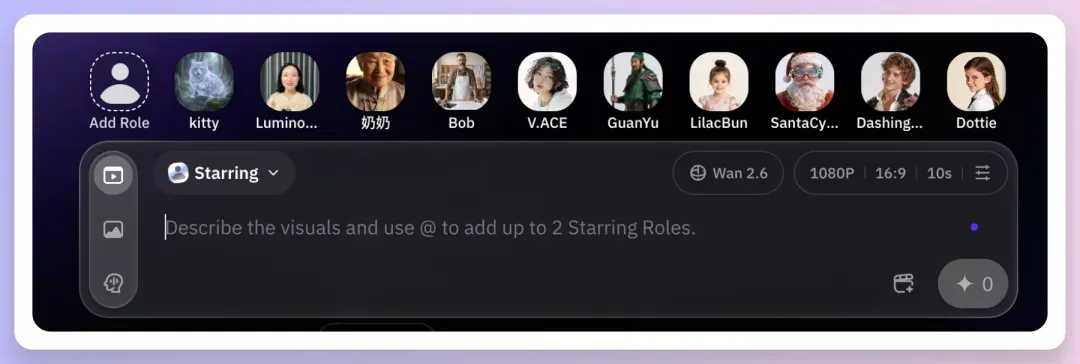
比如下面的女声就是我上传的视频中我自己的声音,然后参考自己的角色+音色的,后期配音就不用费老大劲了。
另外,视频中合成的声音也摆脱了明显的机械感,现在的节奏和情感表达都比较趋近于真实的人声了。
合拍包括了单人独立表演与双人同框合拍两种模式,并且可以基于参考视频中的IP形象进行视频生成,保持角色外观一致性,还可以同步参考输入视频中的声音特征,实现声画匹配,也同时支持通过提示词对视频内容、动作、场景进行精细化控制。
AI视频生成中的音频处理一直是技术难点。早期模型生成的视频都是默片,后续叠加了语音合成能力,也普遍存在口型与声音不匹配、多人场景音色乱套、人声质感机械麻木无感情纯念稿等问题。
万相2.6在声画同步方面基于之前也有针对性优化,上传音频,或者上传音频+图片,都可以得到视频情绪和口型音色都一致的视频了。
比如这段,是基于我上传《报菜名》驱动的音频生成的视频,只提供了图片和音频文件,没有写提示词,它自己完成的口型匹配和音色情绪匹配,哪怕是很板正的正面图,也加入了流畅的镜头切换
镜头智能调度是AI视频领域的技术难题了,常规来说模型大都是擅长生成单一镜头的高质量画面,一到了完成多个镜头的叙事角度就拉胯了。创作者制作多个镜头切换体现氛围情绪的画面的时候,往往都是一个一个镜头生成+剪辑。效率低、角色形象变化都是常有的事。
万相2.6模型新的智能分镜能力,允许我们可以通过简洁的文本描述传达叙事意图,模型自动规划镜头数量、景别切换及镜头时长分配。除了大全景或者太远的景人物可能会糊掉以外,在从特写到中全景的镜头方面的运镜效果是较为稳定的。
另外,模型能够在镜头切换过程中保持关键视觉信息的一致性。面部细节、服饰细节、背景环境等在镜头切换之间能相对比较好地维持一致性,人物变形甚至换脸的问题就大大减少了。同时,在声画同步上的匹配精度也是能听出有优化了的,整体听起来很和谐。
比如下面这个,只需要一张图+提示词,一次性完成宠物电台搞笑视频。在图生视频的基础上,两个角色的音色各有特色,细节到猫子离镜头远的时候声音会变小,镜头也会在发言对象说话的时候推进,整体还是比较丝滑的。
视频生成时长是衡量AI视频模型能力边界的重要指标之一。时长越长,模型就越需要在更大的时间跨度内维持画面质量、运动连贯性及语义一致性,技术难度直接指数级上去了。
万相2.6现在已将文生视频与图生视频的生成时长提升至15秒,参考生视频模式下的生成时长为10秒。15秒的连续视频时长,可以输出一个具备起承转合的微型故事。对于短视频平台的内容创作者而言,这意味着几乎可以直接生成一条完整的成品内容了。
当视频在手机上无法加载,可前往PC查看。万相2.6新模型这次从多个维度上进行了更新,每个功能也是在对应着专业影视创作流程中的核心的需求。甚至部分能力是有明显的差异化优势的,比如角色参考中的声画同步完成度,和多人合拍的配音也不串味不混淆等等。
相信未来在多个领域会有很多非常刚需的场景可以靠万相2.6实现,比如用在短视频、广告、影视前期和虚拟 IP 等多种场景中,创作者或品牌只需使用固定的人物或形象素材,就能快速生成多条风格统一的视频内容,减少反复制作的时间和成本。自动画面顺序和节奏,会相对降低剪辑和配音的工作量,让团队把更多精力放在内容想法和整体效果上,也更方便在早期就理清视频呈现是否合适。
万相2.6系列模型现已开放使用,已经在以下渠道上线:
阿里云百炼:https://bailian.console.aliyun.com/?tab=model#/model-market/all?providers=wan
万相官网: https://tongyi.aliyun.com/wan/
好了,今天的最新快速资讯就到这里,感兴趣的朋友们可以前往体验,有更多玩法和经验,欢迎一起交流讨论。
期待大家的猛猛三连鼓励,下期见~


