图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。
有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?
这一切,现在通过一个由港科大(广州)和字节联合出品的全新的开源框架——ComfyMind实现了。

ComfyMind是一个通用视觉生成框架,它旨在用一套系统,统一处理从文本到图像、从图像到视频等所有主流视觉生成任务。

在多个行业基准测试中,ComfyMind的性能全面超越现有开源方法,达到了与闭源的GPT-4o-Image相媲美的水平。
从“手工作坊”到“智能工厂”
无论是让棱镜散射出物理精确的彩虹,还是给蛋糕切上一块,甚至将一个Logo无缝融入产品,ComfyMind都能轻松胜任。
来看看效果。
结合光学知识,生成一张玻璃棱镜的光散射的图像:

给一张蛋糕的图像,将给定蛋糕切角:

给一张Logo图像,将Logo嵌入杯子:

生成一个长度为8秒的海边燃烧的篝火的视频:

虽然视觉生成模型突飞猛进,但真正能“一套系统包打所有任务”的开源框架依旧脆弱,难以支撑真实生产诉求;
相对地,闭源GPT-Image-1(即GPT-4o-Image)虽效果出众,却无法被社区自由扩展或调优。
ComfyUI的节点式设计为“可视化、模块化”奠定了基础,理论上任何任务都能通过组合节点完成;
然而,当工作流跨越多模态、多阶段时,手工搭建不仅耗时费力,更对专业知识要求极高,成为创作的门槛。
ComfyAgent等LLM-驱动方案已经开始尝试自动生成工作流,但它们依赖扁平JSON 解码,既难以表达模块层级,又缺乏执行端反馈,导致节点缺漏与语义漂移。
人类艺术家在构建复杂流程时,会先拆解任务,再局部试错、局部修正。
借鉴这一策略,该团队提出ComfyMind:以“原子工作流”为最小单位,以自然语言描述接口,结合树状规划加局部反馈执行,将视觉内容创作转化为分层决策问题,从而在保持灵活性的同时,显著提升稳健性与扩展性。
给Comfyui装上大脑,会规划,更会“返工”

上图展示了ComfyMind系统pipeline。
整体架构:“ComfyUI × 多代理协同”
ComfyMind将ComfyUI仅视为底层执行引擎:所有高层决策由规划-执行-评估三代理协作完成。
规划代理自顶向下拆解任务;
执行代理把每一步映射成JSON工作流并结合ComfyUI进行具体生成;
评估代理在生成流程结束时使用VLM判定生成质量与指令一致性,并把诊断信息返回给上一层级。
语义工作流接口:把节点图“函数化”
论文提出的语义工作流接口将社区验证的T2I、I2V、Mask生成等模板封装为“原子工作流”,并以自然语言标注其功能和必选/可选参数。
规划代理因此能够在纯语义空间像调用高阶函数那样组合模块,无需接触易错的JSON语法,彻底消除“漏节点”“拼接错误”等结构性故障。
所有SWI描述集中于单一文档直接注入LLM上下文,摆脱对3200+节点检索数据集的依赖,实现零-RAG的快速扩展能力。
树状规划+局部反馈:「分块-修补」策略
复杂指令被递归拆分为子目标,形成 语义搜索树;每个节点代表局部规划,边对应一次SWI调用。
系统在节点处仅执行链首函数并即时评估——若失败,错误与重规划被限制在当前层级,已通过的分支原地保留,避免全链重跑与策略振荡。
全面的性能评估,在三大基准对比
ComfyBench自动工作流构建
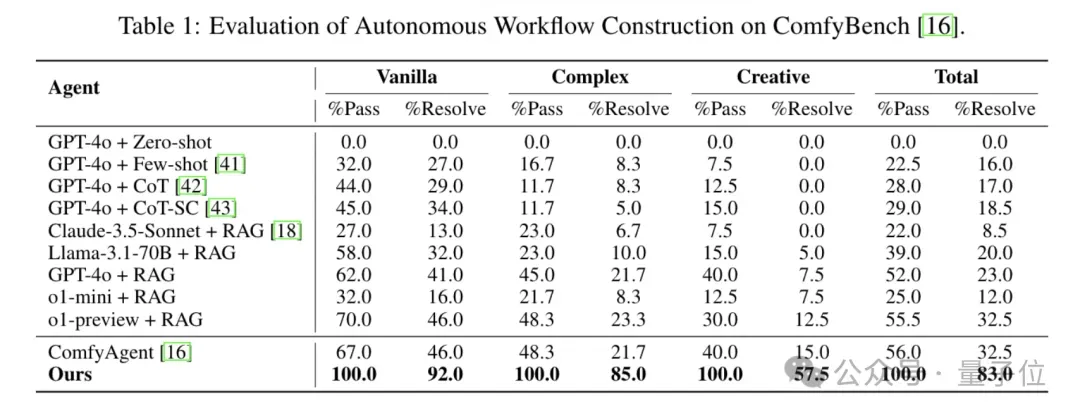
ComfyMind在ComfyBench全难度任务上取得100%的通过率,消除JSON级失败。
同时,将问题解决率在Vanilla、Complex、Creative难度上分别较ComfyAgent提升100%、292%和283%,凸显多代理-ComfyUI体系在通用生成与编辑任务上的卓越泛化能力与输出质量。
Geneval文生图
在GenEval中,ComfyMind获得0.90总分,较开源基线SD3与Janus-Pro-7B分别领先0.16和0.10,并在六大维度中的五项及总体成绩超越GPT-Image-1。
定性对比进一步显示,在各类约束下,本系统同时满足了指令并生成视觉连贯的高质量图像。


Reason-Edit图像编辑
在Reason-Edit基准上,ComfyMind以0.906的GPT-score较前开源SOTA SmartEdit提升+0.334,并接近GPT-Image-1(0.929)。
定性对比亦表明,ComfyMind相较于在精准完成复杂编辑指令的同时还保持了非编辑区域的细节与风格一致。
而GPT-Image-1常出现纹理丢失、色调漂移或比例失真等瑕疵。

总结
论文提出了基于ComfyUI平台构建的全新框架ComfyMind。
ComfyMind将视觉内容创建概念化为一个模块化、语义结构化的规划流程,并将基于树的规划与局部反馈执行相结合。
ComfyMind框架性能超越了之前的开源方法,并取得了与GPT-Image-1相当的结果。
相关论文,在线Demo, 代码,项目主页等均已公开公布。
感兴趣的小伙伴可以进一步体验和探索。
论文链接: https://arxiv.org/abs/2505.17908项目主页链接: https://litaoguo.github.io/ComfyMind.github.io/在线Demo链接: https://envision-research.hkust-gz.edu.cn/ComfyMind/


