
译者 | 核子可乐
审校 | 重楼
生成式AI正在重塑企业运营模式,以前所未有的规模实现自动化、内容生成和智能决策。从AI驱动的聊天机器人到高级代码生成和创意设计,生成式AI正在通过提升效率与创新能力引发行业革命。然而,伴随技术进步而来的还有企业必须应对的重大安全风险。
现实挑战在于,随着AI系统日益智能化和复杂化,其面临的威胁与风险也在持续演变。确保AI在开发与部署全周期的安全性至关重要。
本文提供实用的安全检查清单,帮助企业安全采用生成式AI技术。通过理解关键安全风险、部署必要技术并遵循最佳实践,企业能在释放生成式AI潜力的同时,确保数据、模型和用户安全。
检查清单分为两大类别:
• 生成式AI核心安全风险
• 生成式AI必要安全技术
生成式AI的核心安全风险
生成式AI引入了企业必须直面的新型安全风险,包括数据泄露、模型篡改和未授权访问等。若缺乏适当防护措施,这些风险可能导致严重的隐私与安全漏洞。
1. 数据隐私与合规风险
生成式AI可能暴露敏感数据,违反GDPR、HIPAA等法规要求。若AI模型未加防护地处理机密信息,企业将面临法律、财务和声誉风险。确保合规需要严格的数据处理、访问控制和定期审计。
例如,2023年三星员工误将机密数据输入ChatGPT,引发企业数据隐私与AI误用重大担忧。
应对数据隐私与合规风险的举措包括:
- 使用角色控制限制AI访问敏感数据
- AI处理前实施数据匿名化与加密
- 审计AI交互是否符合GDPR、HIPAA等要求
- 使用AI治理工具执行数据保护政策
2. 虚假信息与偏见
AI模型可能生成错误或误导性内容(即"幻觉")。若训练数据存在偏见,AI可能强化刻板印象并产生不公平结果。企业必须确保AI生成内容准确、符合伦理且无偏见。2023年某AI新闻网站就曾发布虚假文章,误导公众并严重损害到其公信力。
- 定期测试AI模型的偏见与准确性
- 使用多样且高质量的训练数据
- 对关键AI输出实施人工审核
- 建立AI伦理准则确保负责任使用
3. 未授权访问与滥用
一旦缺少安全措施,未授权用户可能访问AI模型,导致数据盗窃或篡改。内部人员与外部黑客均可能成为威胁来源,尤其是在API安全防护薄弱或配置错误等背景之下。某案例中,因API漏洞导致AI聊天机器人公开用户对话,隐私受到侵害。应对措施包括:
- 强制对AI访问实施多因素验证(MFA)
- 实施角色基础访问控制
- 监控AI活动日志中的可疑行为
- 定期开展安全审计与渗透测试
4. 数据投毒
攻击者可通过注入恶意输入破坏AI训练数据,导致模型输出被篡改。这可能引发偏见决策、虚假信息或可利用漏洞。某实验中,研究人员通过投毒数据集操纵人脸识别系统,使其错误识别目标。相关防护策略包括:
- AI处理前验证并清洗训练数据
- 使用差分隐私防止数据篡改
- 部署异常检测工具识别被污染数据
- 使用验证过的多样数据集重新训练模型
5. 伪造“ChatGPT”与仿冒攻击
诈骗者制作伪造AI工具模仿ChatGPT等服务,诱骗用户分享敏感数据或安装恶意软件。这些仿冒品常以移动应用、浏览器扩展或钓鱼网站形式出现,甚至混入官方应用商店。安装后可能窃取登录凭证、财务信息或传播恶意软件。相关防护建议包括:
- 仅从官方渠道使用验证过的AI工具
- 教育员工识别假冒AI与钓鱼诈骗
- 部署安全工具检测欺诈性AI服务
- 向监管部门举报假冒AI平台
6. 模型窃取
攻击者可通过利用API漏洞分析响应来提取专有AI模型,导致知识产权盗窃和竞争优势丧失。北卡罗来纳州立大学研究发现:"研究者已证明无需入侵设备运行即可窃取AI模型。该技术新颖之处在于,即使攻击者对支持AI的软件或架构毫无先验知识也可实施盗窃。"
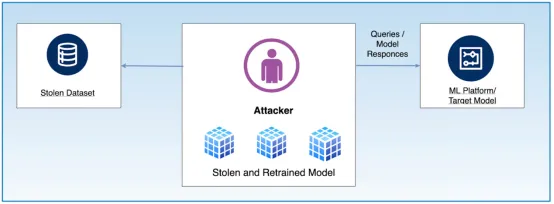
图一:模型窃取流程
上图展示了攻击者向目标模型发送大量查询并收集响应,利用输入输出数据训练仿制模型的过程,可能引发知识产权盗窃和未授权使用。
防护方案包括:
- 限制API访问并设置请求频率限制
- 部署时加密AI模型
- 使用水印技术追踪未授权使用
- 监控API活动中的可疑提取模式
7. 模型逆向攻击
黑客可通过逆向工程AI模型恢复敏感训练数据,可能暴露机密或个人数据。某案例中,研究人员从人脸识别模型中重建面部图像,泄露训练用的用户隐私数据。Andre Zhou在其GitHub仓库中整理了模型逆向攻击相关资源与研究清单。
模型逆向攻击与模型窃取攻击的区别在于,逆向攻击通过分析模型输出反推训练数据,获取隐私信息;模型窃取攻击则通过查询响应复制模型功能,窃取知识产权。
相关防护步骤包括:
- 使用差分隐私保护训练数据
- 限制API响应以控制模型暴露
- 应用对抗性防御措施阻止逆向攻击
- 定期对AI模型进行漏洞评估
8. AI增强的社会工程攻击
AI可生成高度逼真的钓鱼邮件、Deepfake深度伪造视频和语音仿冒内容,使社会工程攻击更具迷惑性。某欧洲公司遭遇AI生成语音仿冒高管声音,成功授权22万欧元欺诈交易。
相关防护措施包括:
- 使用开源工具(如Google SynthId)或商业工具培训员工识别AI诈骗
- 部署AI驱动的安全工具检测深度伪造内容
- 对金融交易实施多因素验证
- 监控通信中的异常模式
生成式AI中的必要安全技术
保护生成式AI需要综合运用加密、访问控制、安全API等技术。监控工具可捕捉异常活动,防御措施能抵御攻击。遵循隐私规范可确保AI使用的安全性与公平性。此外,还需关注以下技术方向以提升AI应用的安全水平:
1. 数据防泄漏方案
数据防泄漏(DLP)方案会监控并控制数据流,防止敏感信息泄露或滥用。相关实施建议包括:
- 使用AI驱动的DLP工具检测并拦截未授权数据共享
- 实施严格的数据分类与访问策略
- 监控AI生成输出防止意外数据泄露
- 定期审计日志中的可疑活动
2. 零信任架构
零信任架构基于身份、上下文和最小权限原则实施严格访问控制。相关实施举措包括:
- 对AI访问实施MFA
- 使用身份与访问管理工具执行最小权限原则
- 持续监控并验证用户与AI交互
- 网络分段限制AI系统暴露面
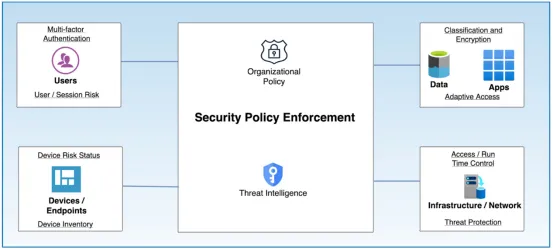
图二:零信任架构
3. 加密与机密计算
加密技术保护静态与传输中的AI数据,机密计算在安全环境中保护敏感AI操作。相关实施建议包括:
- 使用AES-256加密存储数据,使用TLS 1.2+协议传输数据
- 采用硬件安全飞地处理AI任务
- 实施同态加密实现隐私保护计算
- 定期更新加密协议防范漏洞
总结
保护生成式AI需要采取适当措施以维护数据、模型和用户安全,企业需持续优化安全策略,主动应对核心风险。具体包括部署强访问控制、数据保护政策和定期安全测试,同时开展充分研究确保满足自身需求与监管要求。遵循本文提供的检查清单,企业将可安全且创新地使用生成式AI技术。
原文标题:A Comprehensive Guide to Protect Data, Models, and Users in the GenAI Era,作者:Boris Zaikin


