5月28日凌晨,DeepSeek 在 Hugging Face 上开源了其更新版的 R1 模型。
此次更新并未更改名称,只在模型路径中标注“0528”以作区分。
 图源deepseek
图源deepseek
官方称这是一次“minor update”,但社区反馈却指向另一种结论:在代码生成、长时推理、格式控制等任务上,这个版本的 R1 的能力已经“近乎o3级别”。
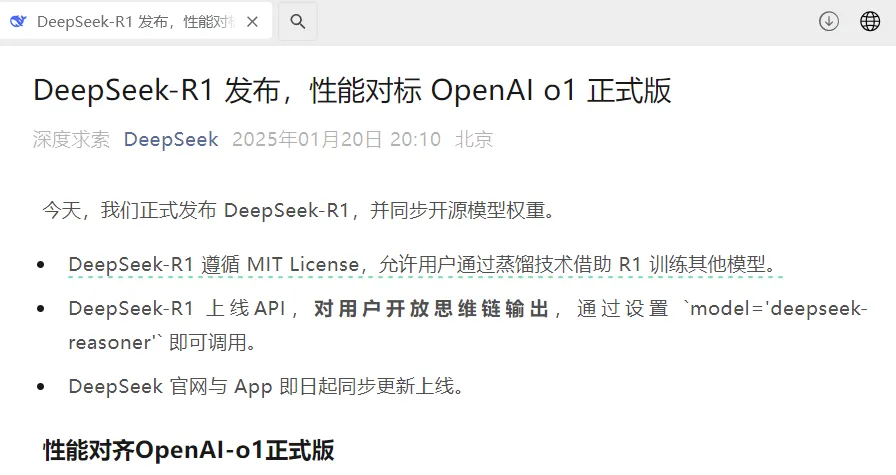
而官方的口风是:“DeepSeek-R1 的性能据称已对齐 OpenAI 的 o1 正式版本,其蒸馏出的轻量模型甚至在多个任务上超越了 o1-mini。”
 图片
图片
图注:推特网友在经典物理模拟测试中,对DeepSeek-R1新旧版本的对比
经国内微博用户实测:编码能力已经可以和Claude 4 掰手腕了。
 图片
图片
此外,此次发布不仅涵盖了权重、配置与模型文档,也同步上线了 App、官网及 API 调用服务,接口对开发者开放。R1 使用 MIT 许可证发布,允许商用,也允许使用其输出结果进行模型蒸馏。
 图片
图片
图注:官方称,在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。图源deepseek
这是中国大模型厂商中,少数同时在算法、产品与授权层面做“全栈开源”的公司之一。
从 R1 到 R1-0528:推理能力的重点优化
据官方信息,此次更新的 R1 模型(标注版本为0528)参数规模约为660B,在训练后期大量采用强化学习技术,以少量标注数据优化模型在数学、编程和语言推理等任务上的表现。
虽然官方并未披露系统性基准测试结果,但多个国内外开发者社区实测显示,R1-0528 在代码生成和复杂推理任务中具备稳定输出能力。
根据用户测试,在 LiveCodeBench 编程测试环境中,R1-0528 在多个任务上表现接近 OpenAI o3-mini(High 模式)和 o4-mini(Medium 模式)。不过,目前尚无该基准的官方排行榜对这一说法予以印证。
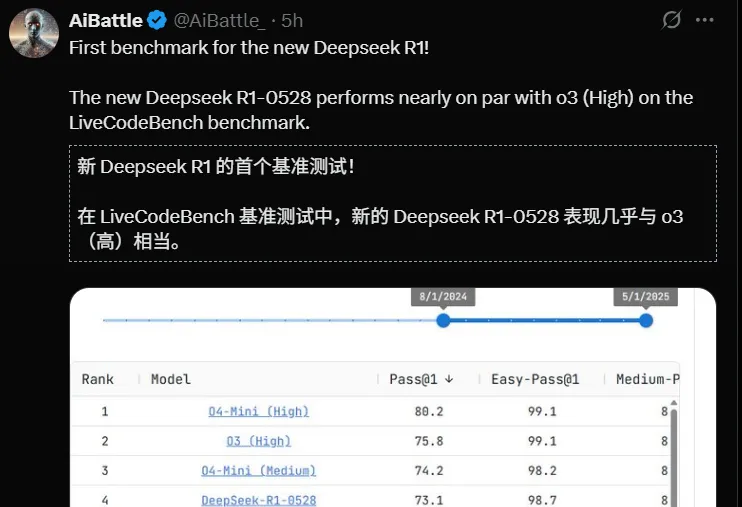 图注:推特用户测试
图注:推特用户测试
尤其在长链条逻辑题中,开发者观察到模型可进行多达20余步的符号化推理,且过程中结构一致性较好。在部分测试场景中,模型思考处理时间可持续数十分钟。
与多数开源模型不同,DeepSeek-R1 的另一特征在于其明确允许并鼓励“模型蒸馏”。
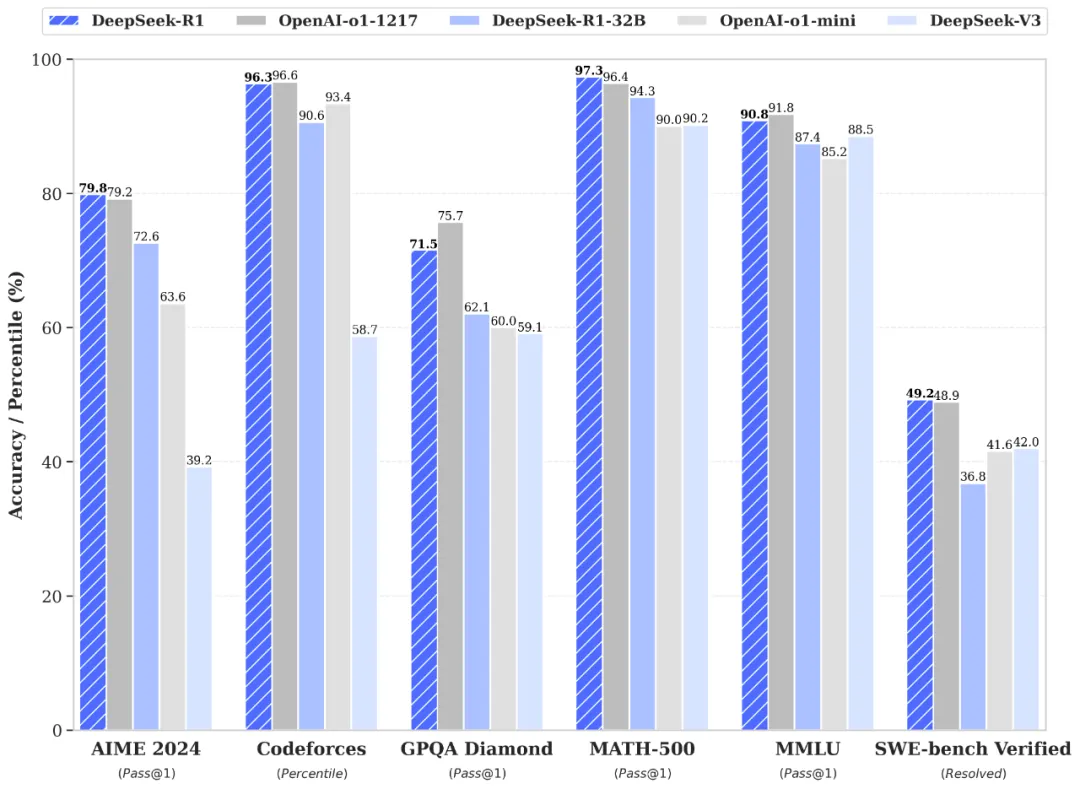
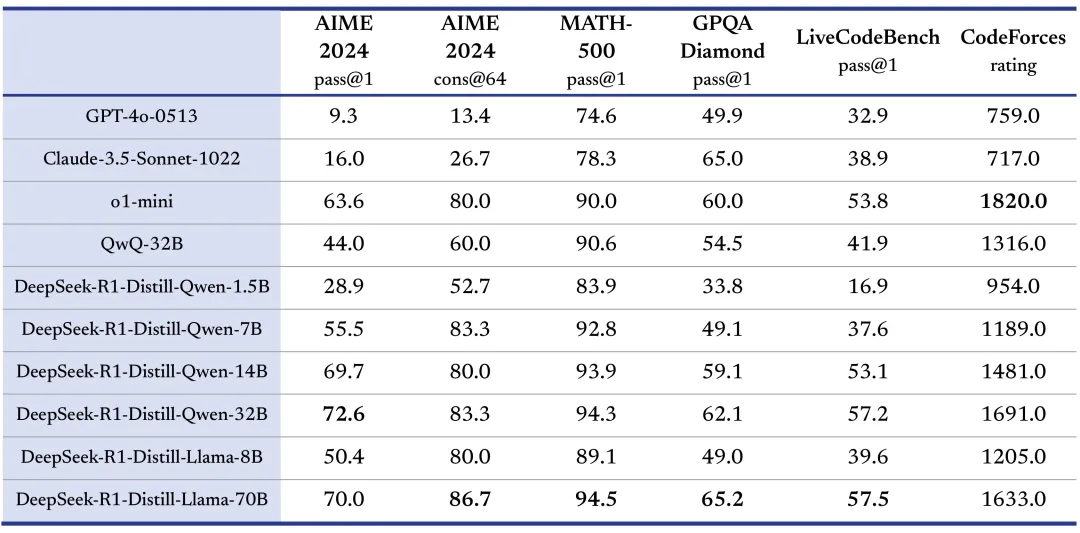
官方同步开源了两个660B规模的大模型(DeepSeek-R1 与 DeepSeek-R1-Zero),并基于其推理输出训练了6个不同规模的子模型,其中 32B 与 70B 两个中型版本,在多个通用能力维度上据称“可对标 OpenAI o1-mini”。不过相关测试细节与完整评估方法尚未公开,仍待进一步验证。
 开源了6个小模型。图源deepseek
开源了6个小模型。图源deepseek
对比之下,这种“从大模型生成小模型”的思路,也让 DeepSeek 的开源策略更贴近“可部署”的实际场景,而非仅停留在评测表现层。
目前,这些模型均已上传至 Hugging Face,且标注为 MIT License,意味着任何企业与开发者均可在不经授权的前提下用于商用或二次开发。
 图片
图片
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
在产品层面,用户可通过“深度思考”模式直接体验 R1 推理能力,在 App 或网页端完成任务调用。API 接入方式为 model='deepseek-reasoner',并提供明确定价策略:百万 tokens 的输入成本为 1 元(缓存命中)至 4 元(未命中),输出成本为每百万 tokens 16 元。
 图片
图片
抱抱脸链接:https://huggingface.co/deepseek-ai
关于Deepseek:争气的国产AI
今年,DeepSeek突然登上全球AI舞台。
它的聊天应用一度冲上苹果和安卓商店的榜首,背后的模型在多个基准测试中超越Meta Llama和OpenAI GPT-4o,吸引了华尔街分析师和硅谷技术官员的罕见一致关注。微软将其接入Azure,英伟达CEO称其“创新出色”。
DeepSeek起初并不做 AI 模型,它的母公司是量化基金“九坤投资”,创始人梁文锋是浙江大学出身的 AI 爱好者。2015年开始试水交易系统,2019年正式设立对冲基金。在量化交易中摸索多年的算法团队,成为日后DeepSeek模型训练的基础。
 DeepSeek Founder Liang Wenfeng
DeepSeek Founder Liang Wenfeng
2023年,九坤成立DeepSeek Lab,作为科研独立体。彼时正值中国AI创业热潮复燃,百度、字节、阿里、MiniMax、月之暗面先后发布通用大模型。DeepSeek一开始就选了一条不一样的路:自建数据中心、强调计算效率,并迅速在一年内迭代三代模型。
DeepSeek V2于2024年春天发布,以“推理能力”突出出圈。相比同行更重堆参数、跑分的路径,DeepSeek强调模型在复杂任务下的“思考能力”——数学、物理、代码,正是V2和后续R1模型发力的重点。
V3版本上线于2024年末,DeepSeek宣称它在内测中超越了OpenAI的GPT-4o。2025年1月,DeepSeek-R1问世,定位为“reasoning model”。它在 Hugging Face 上以MIT协议发布,成为业内少见能商业化改造的高性能模型之一。
一方面,DeepSeek通过模型架构优化和训练效率提升,大幅压缩了推理成本。另一方面,它在市场价格上极为激进:不少模型免费开放、接口调用价格低于行业平均值,甚至迫使阿里、字节等国内玩家降价或免费开放部分模型。
这也引发了对其商业模式的质疑。截至目前,DeepSeek并未公开融资轮次,也尚未启动商业化路径。据接近公司人士透露,其运营主要依赖母公司九坤提供的算力和资金资源。相比依靠云厂商和VC支持的AI创业者,DeepSeek的路线更像是“实验室模式”。
这种不以盈利为目的的打法,引发了一系列连锁反应:2025年1月,受DeepSeek影响,英伟达股价单日下跌近18%;3月,美国政府多次点名DeepSeek,建议封禁;5月,微软在参议院听证会上明确禁止员工使用DeepSeek产品,理由是“数据安全”和“宣传内容风险”。
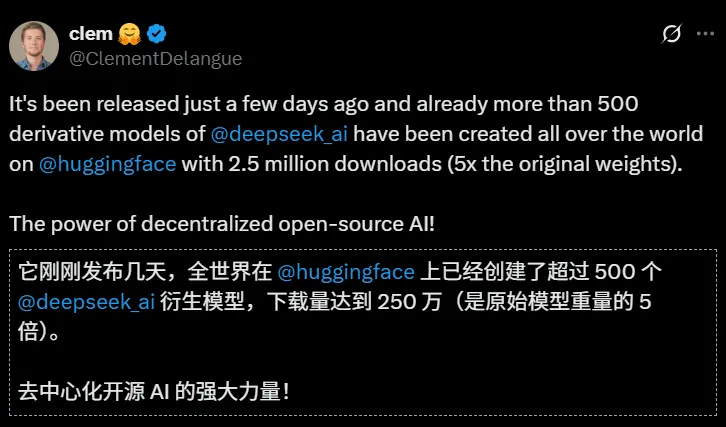 图注:来自抱抱脸联合创始人的认可
图注:来自抱抱脸联合创始人的认可
从社区反馈来看,DeepSeek模型的可用性极高。截至今年5月,开发者基于R1模型创建的“衍生模型”已超过500个,总下载量突破250万次。这种“实用主义开源”反而提升了模型影响力。


