
大家好,我是肆〇柒。图像生成技术正以前所未有的速度演进,从早期的 GANs(生成对抗网络)到如今的扩散模型,每一次技术迭代都为视觉创作领域注入了新的活力。而近期,GPT-4o 发布的生图能力,真是火出圈,甚至带火了吉卜力风格。GPT-4o 作为统一视觉-语言生成模型,它强大、自然的生图能力,让人们对 AI 图像生成的潜力有了全新的认知。作为一款备受瞩目的多模态生成模型,GPT-4o 在图像生成方面不仅可以生成具有高度真实感的复杂图像,还能实现文本与图像之间的无缝融合。

刚好我扒拉到了一篇论文《An Empirical Study of GPT-4o Image Generation Capabilities》,它详细剖析了 GPT-4o 在图像生成领域的各种表现和能力,内容丰富且全面。现在,就让我们一同深入探索 GPT-4o 的图像生成,看看它是如何在这一领域掀起波澜的。
技术背景:回溯图像生成的演化之路
早期图像生成方法(GANs):生成对抗网络的舞蹈
生成对抗网络(GANs)自诞生以来,便以其独特的对抗训练机制在图像生成领域大放异彩。它巧妙地利用生成器和判别器之间的博弈,使生成器能够不断学习生成更逼真的图像。然而,GANs 的训练过程却如同在钢丝上跳舞,极其不稳定。生成器和判别器需要在动态博弈中达到精妙的平衡,否则极易陷入模式崩溃(Mode Collapse)的困境,导致生成的图像千篇一律,缺乏多样性。这就好比在一场即兴创作的音乐会中,如果乐队成员(生成器)只反复演奏相同的旋律,而忽略了指挥(判别器)的反馈,整个演出就会变得单调乏味。
扩散模型的兴起与优势:另辟蹊径的图像生成魔法
正当 GANs 的研究者们为解决训练难题绞尽脑汁时,扩散模型如同一颗新星闪耀登场。它另辟蹊径,通过逐步添加噪声将图像破坏,再逆向这一过程来学习图像生成。这种独特的方式赋予了扩散模型生成高质量图像的强大能力。与 GANs 相比,扩散模型的训练更为稳定,生成的图像也更加多样化。这就好比是制作一杯香浓的咖啡,先往咖啡豆中加入适量的水(噪声),让其充分浸泡(添加噪声过程),然后再通过滤纸(逆向去噪过程)慢慢滤出一杯口感丰富、层次分明的咖啡(生成图像),整个过程更加可控,也更容易得到理想的口味(图像质量)。
统一生成架构的发展趋势:多模态融合的探索之旅
随着 AI 技术的不断发展,研究者们开始探索能否将文本生成与图像生成统一在一个架构之下。这样的统一生成架构旨在实现一个模型能够同时理解并生成多种模态的数据。这就像是一场跨学科的学术交流,不同领域的学者们(文本、图像等模态)试图找到共同的语言和框架,以便更好地分享知识、激发创新。然而,这一目标的实现并非易事,因为文本和图像在数据形式、语义表达等方面存在着巨大的差异,就好比是让来自不同星球的生物共同建立一个联合王国,需要跨越重重障碍。
GPT-4o 的架构设计与工作原理概述:自回归与扩散的完美邂逅
GPT-4o 在架构设计上实现了自回归模型和扩散模型的创新融合,这种独特的结合是其在多模态生成任务中表现出色的关键所在。
自回归模型的扩展应用
传统自回归模型在文本生成领域取得了巨大成功,它通过预测下一个字符或单词的条件概率,逐步构建起完整的文本序列。GPT-4o 将这一自回归的思想巧妙地扩展到了图像生成领域。在生成图像时,模型会将图像分解为一系列的像素或特征序列,然后依次预测每个像素或特征的值,基于之前已生成的像素或特征信息。这种序列化的生成方式使得 GPT-4o 能够在生成图像时保持与文本生成类似的连贯性和逻辑性,确保生成的图像内容在语义上的一致性和连贯性。这体现了对生图主体强大的控制力。
扩散模型的关键借鉴
扩散模型以其出色的图像生成质量和稳定性而闻名,它通过逐步添加噪声破坏图像,再逆向这一过程来学习图像生成。GPT-4o 借鉴了扩散模型中的多轮迭代优化思想。在生成图像的过程中,模型不仅仅是一次性地生成最终的图像,而是通过多轮的迭代优化,逐步细化和改进生成的图像内容。在每一轮迭代中,模型都会根据当前生成的图像状态和目标分布之间的差异,对图像进行调整和优化,从而不断提高生成图像的质量,使其逐渐接近真实图像的分布。
多模态融合的实现方式
GPT-4o 作为一个多模态生成模型,其核心挑战在于如何有效地融合文本和图像这两种不同的模态数据。为了实现这一目标,GPT-4o 采用了多种创新的技术手段。它先通过将文本和图像分别编码为统一的特征表示,使得两种模态能够在同一个特征空间中进行交互和融合。这种统一的特征表示使得模型能够捕捉到文本和图像之间的语义关联,从而在生成图像时能够准确地遵循文本的指导。之后,GPT-4o 在模型的解码阶段,通过交叉注意力机制等手段,使得图像生成过程能够动态地参考文本信息,从而实现对文本提示的精准响应和图像内容的精细控制。
训练与优化策略
为了使 GPT-4o 能够有效地学习到图像和文本的联合分布,并生成高质量的多模态内容,其训练过程采用了多种先进的优化策略。一方面,模型在训练过程中会同时利用大量的图像 - 文本对数据,通过最大化图像和文本之间的互信息,来增强模型对两种模态之间语义一致性的学习。另一方面,GPT-4o 还采用了预训练和微调相结合的方式,先在大规模的通用数据上进行预训练,以学习到图像和文本的基本特征和通用模式,然后在特定的任务数据上进行微调,以适应具体的图像生成任务要求。这种训练策略不仅提高了模型的泛化能力,还使其能够更好地满足不同应用场景下的个性化需求。
计算资源与效率的平衡
GPT-4o 在追求高质量图像生成的同时,也注重计算资源的高效利用和生成效率的提升。通过优化模型结构和采用高效的采样算法,GPT-4o 能够在相对合理的计算成本下,快速生成高质量的图像内容。例如,模型在生成图像时会根据任务的需求和用户的偏好,动态地调整生成过程中的迭代次数和计算精度,从而在生成质量和计算效率之间取得平衡。此外,GPT-4o 还通过分布式训练和模型并行等技术手段,进一步提高了模型的训练和推理速度,使其能够更好地服务于实际应用中的实时性和高吞吐量要求。
实验评估方法:解码 GPT-4o 的性能密码
评估模型的选择依据:精选对手,一较高下
在对 GPT-4o 的图像生成能力进行评估时,选择合适的对比模型至关重要。这就好比是在一场百米赛跑中,要挑选出水平相当的选手一同竞技,才能凸显出参赛者的真实能力。因此,选取了一系列在图像生成领域表现突出的开源和商业模型作为对比对象。这些模型涵盖了从传统的 GANs 派生模型到最新的扩散模型,以及一些基于大型语言模型(LLM)扩展而来的多模态模型。它们都在各自的细分领域有着独特的技术和应用场景,能够为 GPT-4o 的评估提供全面的参照系。
主要比较的开源和商业模型介绍:群雄逐鹿
• Gemini 2.0 Flash :作为一款备受瞩目的多模态模型,Gemini 2.0 Flash 在图像生成、文本理解等多个任务上展现出了强大的性能。它采用了先进的训练技术和优化策略,能够快速生成高质量的图像,并且在多模态融合方面有着独特的设计。就好比是一位身怀多项绝技的武林高手,在不同的竞技场都能大显身手。
• Midjourney v6.1 :提到图像生成,就不得不提 Midjourney。这个版本的 Midjourney 在艺术风格图像的生成上有着深厚的造诣。它能够根据简洁的文本描述,生成极具艺术美感和创意的图像,仿佛是一位专注于艺术创作的天才画家,用独特的色彩和构图手法为人们带来视觉盛宴。
• 在开源领域 ,像 Stable Diffusion 系列模型(如 SDXL1.0、SD3 Medium、SD1.5)等也赫赫有名。这些模型凭借着强大的社区支持和灵活的定制能力,被广泛应用于各种图像生成任务。它们就像是开源世界中的瑞士军刀,虽然不像商业模型那样精致,但胜在功能全面、可扩展性强,能够满足不同用户的需求。
评估涵盖的四大类任务及其具体细分:全方位扫描 GPT-4o 的能力图谱
本次评估全面覆盖了图像生成领域的四大类任务,每一类任务都包含多个具体细分任务,以此来全方位考察 GPT-4o 的图像生成能力。这四大类任务分别是:
• 文本到图像(Text-to-Image)任务 :包括复杂文本遵循能力(如属性绑定、数量、对象关系等)、文本渲染能力(短文本与长文本渲染)、文档图像生成、全景图像生成等。这些任务旨在检验模型是否能够准确理解文本描述,并将其转化为符合语义的图像。
• 图像到图像(Image-to-Image)任务 :涵盖风格转换、图像编辑、定制化、故事图像生成等。重点评估模型在给定输入图像的基础上,按照指定要求进行图像变换和创作的能力,例如将一幅风景照转换成梵高的绘画风格,或者在一张照片中添加、删除特定物体等。
• 低级视觉任务 :如图像去噪、去雨、去雾、图像超分辨率、修复与外推、图像上色与重打光等。主要考察模型对于图像基本质量的优化能力,能否在去除干扰因素(如噪声、雨迹等)的同时,增强图像的细节和视觉效果。
• 空间控制任务 :包含基于 canny、深度、草图、姿态和蒙版的图像生成任务。用于评估模型在给定特定结构或条件约束(如边缘图、深度图等)下生成符合要求图像的能力,这在一些需要精确控制图像结构的应用场景(如建筑制图、工业设计等)中具有重要意义。
• 图像到 3D(Image-to-3D)任务 :包括从 2D 图像到 3D 模型的生成、2D UV 映射到 3D 渲染、新视图合成等任务,用以评估模型在三维建模和视图合成方面的能力。
• 图像到 X(Image-to-X)任务 :如图像分割(参考分割、语义分割、全景分割)、边缘检测与图像抠图、显著目标检测、镜面检测、阴影检测、深度估计与表面法线估计、布局检测与文本检测、目标跟踪等,全面考察模型在图像理解和分析方面的表现。
在对 GPT-4o 的文本到图像任务表现进行深入分析之前,我们先来了解一下它在该任务中可能会出现的错误类型。下表展示了 GPT-4o 与其他基线模型在文本到图像任务中的错误类型对比,这有助于我们更好地理解其在后续具体任务表现中的优势与不足。
图例说明:
• Low Visual Quality (低视觉质量):图像合成模型无法生成精细的对象细节,或者产生模糊的输出。典型情况包括人体变形或手部形状不真实。
• Inconsistent Generation (生成不一致):图像合成模型生成的输出或图像细节与输入图像不一致。
• Lack of Knowledge (知识缺乏):图像合成模型缺乏特定领域的知识,例如特定的艺术风格,因此生成的结果虽然在视觉上看似合理,但实际上是错误的。
• Failure to Follow Instructions (无法遵循指令):图像合成模型错误地理解了输入提示,从而产生了不一致的结果。例如,它可能无法捕捉到指定的数量、颜色或对象排列。
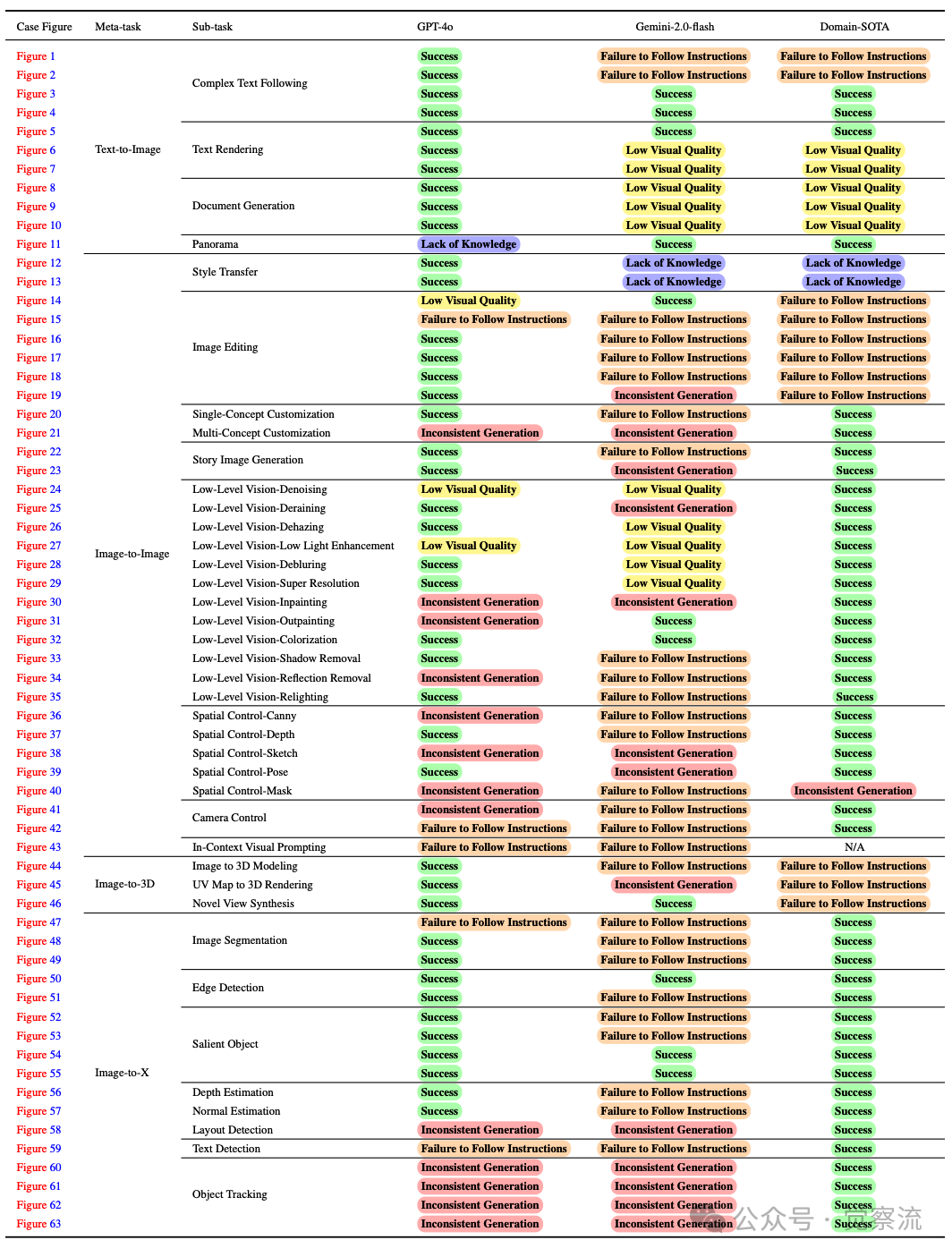
GPT-4o与基线模型对比:在图像生成任务中的定性错误分析
由于本文的图片众多,加上为了方便大家对照上表查看,所有与表格对应的图片,我都保留了与表格一致的编号。
文本到图像(Text-to-Image)任务表现:用文字绘制图像的魔法
复杂文本遵循能力:精准解读,图像跃然而出
在复杂文本遵循能力方面,GPT-4o 展现出了非凡的实力,犹如一位精通多种语言的翻译官,能够精准地将文本中的语义信息转化为图像中的视觉元素。无论是多对象的组合,还是对象之间复杂的属性和关系,它都能够一一对应地在图像中呈现出来。

Figure 1: 任务:组分式文本生成图像。评估图像 - 文本对齐在属性绑定、数感和对象关系上的表现。设置:每行展示一个文本提示以及来自 GPT-4o、Gemini 2.0 Flash 和 Midjourney v6.1 的生成输出。观察结果:GPT-4o 在所有方面均优于 Gemini 2.0 Flash 和 Midjourney v6.1。然而,GPT-4o 在处理具有特殊几何形状的不常见对象时存在困难

Figure 3: 任务:组分式文本生成图像。评估图像 - 文本对齐在复杂构图上的表现。设置:每行展示一个文本提示以及来自 GPT-4o、Gemini 2.0 Flash 和 FLUX.1-Pro 的生成输出。观察结果:与 Gemini 2.0 Flash 相比,GPT-4o 和 FLUX 能够生成更和谐自然的场景
上图展示了 GPT-4o 在复杂文本遵循能力方面的具体表现,与 Gemini 2.0 Flash 和 FLUX 相比,其在生成复杂文本描述的图像时,能够更准确地捕捉文本中的细节信息,生成的图像更符合文本要求。
在属性绑定这一关键维度上,GPT-4o 几乎可以做到完美地将文本描述中的颜色、形状、纹理等属性准确无误地赋予相应的物体。例如,当要求生成 “一只黄色的狗狗在蓝色的草地上奔跑” 时,它能够清晰地描绘出黄色的狗狗形象以及蓝色草地的背景,而且两者之间的搭配自然协调,毫无违和感。在数量方面,它也表现得十分出色,能够精准地生成指定数量的物体,不会出现多生成或少生成的情况。对于对象关系的理解更是堪称一绝,无论是二维空间中的相对位置关系,还是三维空间中的遮挡、交互等复杂关系,它都能够巧妙地在图像中展现出来。比如,在生成 “一个人站在一匹马的前面” 这样的图像时,它能够正确地处理人物与马匹之间的空间关系,让人物自然地出现在马匹前面,而不是漂浮在空中或者与马匹相互穿插。
与其他模型相比,GPT-4o 在复杂文本遵循能力上无疑处于领先地位。它在面对长文本描述时,依然能够保持较高的准确性和连贯性,而一些其他模型则容易在复杂的文本要求下迷失方向,生成的图像要么遗漏关键元素,要么将对象之间的关系处理得混乱不堪。下图展示了 GPT-4o 在复杂文本遵循能力方面的具体表现,与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,其在生成复杂文本描述的图像时,能够更准确地捕捉文本中的细节信息,生成的图像更符合文本要求。

Figure 2: 任务:组分式文本生成图像。评估图像 - 文本对齐在属性绑定和复杂构图上的表现。设置:每行展示一个文本提示以及来自 GPT-4o、Gemini 2.0 Flash 和 Midjourney v6.1 的生成输出。观察结果:在准确生成与文本提示对齐的对象方面,GPT-4o 超过了其他两个模型。但对于更抽象和创意的任务,Midjourney v6.1 表现最佳
文本渲染能力:让文字在图像中绽放光彩
GPT-4o 的文本渲染能力更是令人称奇,无论是短文本还是长文本,它都能够以一种自然、美观的方式将其融入图像之中。在短文本渲染方面,它与现有的基线模型表现相当,能够准确地生成符合提示要求的简短文本内容,例如在图像中生成带有标语的海报或者带有简短说明的插图等。图2 展示了 GPT-4o 在短文本渲染任务中的表现,与 Gemini 2.0 Flash 和其他基线模型相比,其生成的短文本在字体、颜色和排版上都更加自然美观,与图像内容的融合度更高。

Figure 5: 任务:简短文本渲染。在图像上生成与提示对齐的简洁文本内容(通常在 10 个词以内)。设置:每个样本均基于引导式文本提示生成。并与之前的 SOTA 模型和 FLUX 进行比较。观察结果:在短文本渲染方面,GPT-4o 的性能与现有的 SOTA 基线相当,能够始终如一地遵循提示且错误最少。除 FLUX 外,所有评估的方法在此设置中均能提供高保真度的结果
然而,当涉及到长文本渲染时,GPT-4o 的优势便开始凸显。它能够生成连贯且详细的长文本内容,在超过 100 个字符的文本生成中,出现错误的字符数量极少,通常少于三个。

Figure 7: 任务:长文本渲染
上图进一步展示了 GPT-4o 在长文本渲染任务中的具体案例,与 Gemini 2.0 Flash 和 Ideogram 3.0 等模型相比,其生成的长文本在连贯性、准确性和视觉效果上都更胜一筹。
这就好比是一位耐心且细致的书法家,能够一笔一划地写出长篇的文章,而不会出现错别字或者字迹潦草的情况。相比之下,其他模型在长文本渲染时往往会出现较多的错误,或者生成的文本模糊不清、难以辨认,仿佛是匆匆忙忙写就的草稿,难以达到 GPT-4o 那种精准而又优雅的效果。下图展示了 GPT-4o 在长文本渲染任务中的具体案例,与 Gemini 2.0 Flash 和 Ideogram 3.0 等模型相比,其生成的长文本在连贯性、准确性和视觉效果上都更胜一筹。

Figure 6: 任务:长文本渲染。在图像上生成扩展的、连贯的且与提示一致的文本内容。设置:与包括 POSTA、Gemini 2.0 Flash、Ideogram 3.0 和 Playground-v3 在内的高级基线进行评估比较。观察结果:GPT-4o 在长文本渲染方面表现出色,能够生成连贯、详细的文本信息,且字符错误极少。相比之下,像 Gemini 2.0 Flash、Ideogram 3.0 和 Playground-v3 这样的模型在面对长提示时,常常出现更多错误或生成模糊的文本,而 POSTA 的定制多步流程有时能产生具有竞争力的精准度。总体而言,GPT-4o 在扩展文本生成方面超越了大多数商业模型,并与专门的研究方法相媲美
文档图像生成:打造专业文档的视觉盛宴
在文档图像生成任务中,GPT-4o 同样交出了一份令人满意的答卷。与 Gemini 2.0 Flash 和 Playground-v3 相比,它能够生成布局更整洁、内容更连贯的文档图像。
例如,在生成一篇学术论文的首页图像时,GPT-4o 能够精准地按照学术论文的标准格式,将标题、作者列表、摘要等内容合理地布局在页面上,字体大小适中、行间距均匀,整体排版美观大方。下图展示了 GPT-4o 在文档图像生成任务中的表现,与 Gemini 2.0 Flash 和 Playground-v3 相比,其生成的文档图像在布局和内容一致性方面明显更优。

Figure 8: 任务:文档图像生成。设置:每行展示一个文本提示以及来自 GPT-4o、Gemini 2.0 Flash 和 Playground-v3 的生成输出。观察结果:与其他两个模型相比,GPT-4o 能够生成更一致且准确的字体和格式

Figure 9: 任务:文档图像生成。设置和观察结果同上

Figure 10: 任务:文档图像生成。设置和观察结果同上
以上展示了 GPT-4o 在文档图像生成任务中的表现,与 Gemini 2.0 Flash 和 Playground-v3 相比,其生成的文档图像在布局和内容一致性方面明显更优。
全景图像生成:解锁 360 度的视觉沉浸体验
全景图像生成对于 GPT-4o 来说却是一个不小的挑战。尽管它能够生成出近似于全景图的图像,但在确保图像边界连续性方面存在明显的不足。与其他基线模型相比,GPT-4o 在生成的全景图像中,左右两侧往往无法做到无缝连接,导致图像的整体性和沉浸感大打折扣。图11 展示了 GPT-4o 在全景图像生成任务中的表现,与 Pano-SD 和 Gemini 2.0 Flash 相比,其生成的全景图像在边界连续性方面存在明显差距,这可能是由于其训练数据中全景图像的代表性不足,使得它在学习全景图像的生成特征时存在一定的偏差。
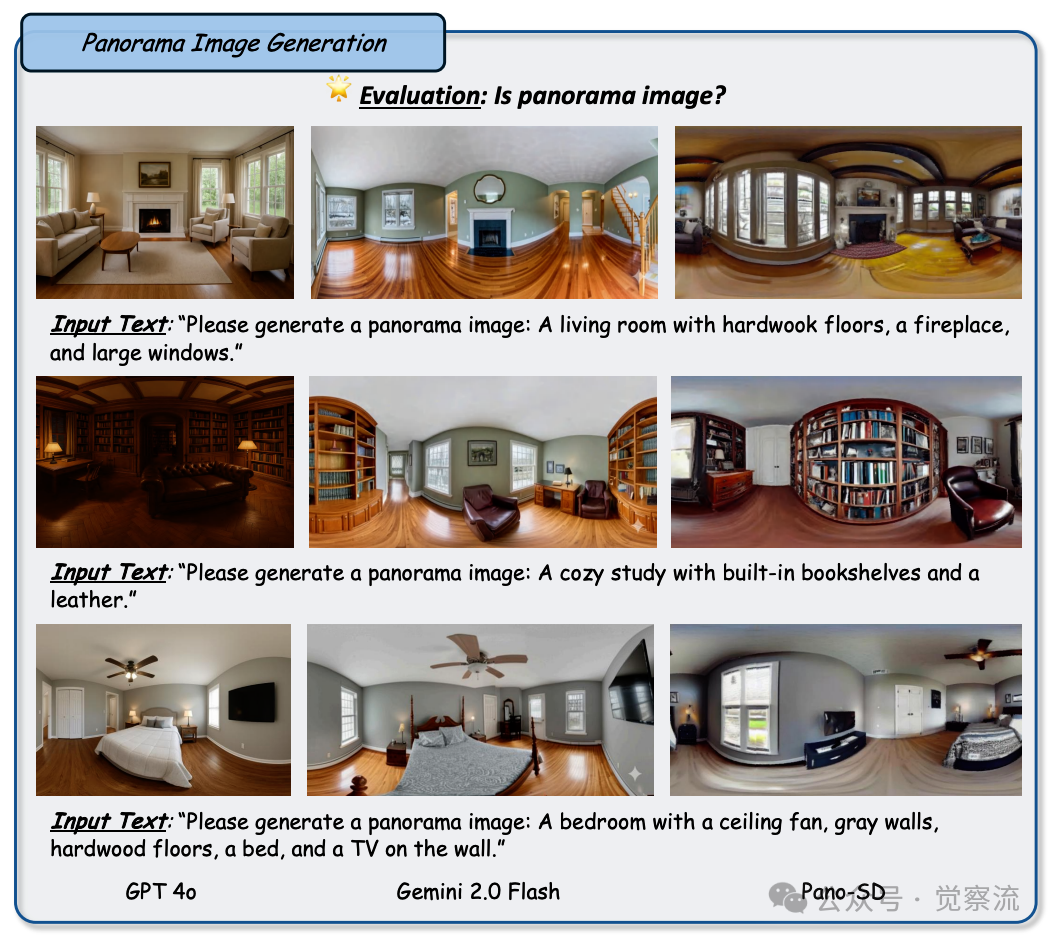
Figure 11: 任务:全景图像生成,旨在创建静态场景的沉浸式 360 度视图。设置:将 GPT-4o 与诸如 Pano-SD 和 Gemini 2.0 Flash 之类的成熟基线进行比较,以评估连贯全景图像的生成效果。观察结果:尽管基线模型能够可靠地生成左右两侧无缝连接的全景图,但 GPT-4o 通常只能近似生成全景视图,并在维持图像边界连贯性方面存在困难。这种不足可能归因于其训练数据中全景图像表示有限,且倾向于生成垂直纵横比较高而非较宽的图像,使其在此任务中不如基线模型。
图像到图像(Image-to-Image)任务表现:图像变形的奇幻之旅
风格转换:一键切换,畅游艺术风格的海洋
在风格转换任务中,GPT-4o 如同一位技艺高超的画家,能够轻松地将一幅图像转换成多种艺术风格,同时忠实地保留了原始图像的内容细节。在面对多种艺术风格的转换要求时,它都能够精准地捕捉到每种风格的独特特征,并将其巧妙地应用到生成的图像中。图12 和图13 分别展示了 GPT-4o 在自然场景和人物面部图像风格转换任务中的表现,与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,其生成的图像在风格保真度和内容保留方面均表现出色。

Figure 12: 任务:风格迁移,旨在将图像渲染成特定的艺术风格,同时保留原始内容。设置:在多个艺术领域内,将 GPT-4o 与 Gemini 2.0 Flash 和 Midjourney v6.1 进行比较,进行自然场景风格迁移。观察结果:与 Midjourney v6.1 相比,GPT-4o 在内容保留方面表现出明显优势,能够维持精细的内容细节和结构连贯性。在风格方面,它忠实地遵循文本描述,有效呈现生动的色彩搭配和柔和的轮廓,这些正是目标风格的特征。这种对齐方式显著超越了 Gemini 2.0 Flash 和 Midjourney v6.1,凸显了 GPT-4o 在保留内容及忠实呈现多样风格方面的强大能力。

Figure 13: 任务:风格迁移,旨在将图像渲染成特定的艺术风格,同时保留原始内容。设置:在多个艺术领域内,将 GPT-4o 与 Gemini 2.0 Flash 和 Midjourney v6.1 进行比较,进行人脸风格迁移。观察结果:与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,GPT-4o 在内容保留方面表现出明显优势,能够维持精细的内容细节和结构连贯性。在风格方面,它忠实地遵循文本描述,有效呈现生动的色彩搭配和柔和的轮廓,这些正是目标风格的特征。这种对齐方式远远超越了 Gemini 2.0 Flash 和 Midjourney v6.1,凸显了 GPT-4o 在保留内容及忠实呈现多样风格方面的强大能力。
无论是将自然风光照片转换成梵高的《星月夜》风格,还是将人物肖像转换成迪士尼卡通风格,GPT-4o 都能够生成具有高度风格保真度和内容保留的图像。与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,它在风格转换过程中展现出了更强大的内容保留能力。其他模型在转换过程中往往会出现对象形状扭曲、细节丢失或者风格不一致的问题,仿佛是在模仿名家画作风格时,只学到了表面的笔触,却未能领会其精髓。而 GPT-4o 却能够深入理解不同风格背后的艺术内涵,并将其恰到好处地融入到图像中,使生成的图像既具有目标风格的独特魅力,又不失原始图像的核心内容。
图像编辑:随心雕琢,塑造图像的千变万化
GPT-4o 在图像编辑任务中的表现堪称惊艳,无论是对图像进行细微的修改还是大规模的变换,它都能够轻松应对,并且展现出令人赞叹的细粒度编辑和主体保留能力。图14 和图15 分别展示了 GPT-4o 在细粒度编辑和大规模图像转换任务中的表现,与 Gemini 2.0 Flash 和其他基线模型相比,其生成的图像在细节处理和整体效果上都更胜一筹。

Figure 14: 任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/MGIE 对比。观察结果:GPT-4o 的成功率高于 MGIE(示例 2/5),但偶尔会更改意外的元素(示例 4 中的面包)或光影结构(示例 5)。这可能源于其在训练中更强的泛化能力和创意适应性关注,尽管保真度降低表明在微调期间对结构细节的约束不足。

Figure 15: 任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/MGIE 对比。观察结果:从示例 1-3 可以看出,GPT-4o 在细节编辑和大规模修改(包括遮挡情况)方面成功率更高。这可能源于 GPT-4o 更强的上下文理解和对缺失或被遮挡元素的推断能力,使其能够进行更精准的局部编辑,即使在部分可见的情况下也能进行连贯的大规模修改。然而,它有时会抹去非目标元素(例如示例 5 中的房子),并显著改变全局光照(示例 4)。
在细粒度编辑方面,它能够精准地修改图像中微小的物体细节,如在一张食物图片中,它可以将盘子里的一根火柴棍精确地移到另一个位置,或者在一幅人物肖像中,细致地调整发丝的形状和走向。这种对细节的精准把控,使得它在处理需要精细调整的图像编辑任务时表现出色。在大规模图像转换方面,例如将一幅白天的城市街景图转换成夜晚的霓虹灯闪烁效果,或者将一张普通照片转换成具有油画质感的艺术作品,GPT-4o 能够在保持整体画面结构和语义一致性的同时,有效地完成风格和内容的大规模转变。
在图像编辑任务中,GPT-4o 展现出了强大的风格编辑能力,能够根据文本提示准确地调整图像的整体风格,同时保持图像的结构完整性。

Figure 16: 任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/MGIE 对比。观察结果:从示例 1 可以看出,GPT-4o 在风格编辑方面表现出卓越的性能,能够有效解读风格指令并保留图像的全局结构——这是基线模型(MGIE、Gemini 2.0 Flash 和 MagicBrush,后续将进一步展示)所缺乏的能力。这可能源于其在训练过程中更强的跨模态理解和结构意识.上图展示了 GPT-4o 在风格编辑任务中的表现,尤其是在处理复杂场景时,能够更好地理解和执行风格转换指令。GPT-4o 在图像编辑任务中不仅能够处理复杂的风格转换,还能在涉及具体对象的编辑中表现出色,例如对图像中的特定物体进行修改或替换。

Figure 17: 任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/LEDITS++/MagicBrush 对比。观察结果:从示例 2 和 3 可以看出,GPT-4o 对涉及“货架上的橙子”和“大象行走的水面”等指令的理解更强,并将这种理解转化为更准确的编辑。这表明在生成过程中,文本提示在视觉上下文中的定位更佳.上图展示了 GPT-4o 在处理具体对象编辑任务中的表现,尤其是在理解文本提示并将其准确应用于图像编辑方面。

Figure 18: 任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/MagicBrush 对比。观察结果:此组示例进一步证明了 GPT-4o 在风格编辑和背景修改方面的强大能力,与图 16 先前展示的结果一致上图进一步展示了 GPT-4o 在风格编辑和背景修改方面的强大能力,与之前的实验结果一致。

图19:任务:图像编辑,用于修改视觉元素和构图。设置:GPT-4o 与 Gemini 2.0 Flash/MagicBrush 对比。观察结果:示例 4 突显了 GPT-4o 卓越的图像理解能力——能够准确区分头发和围巾(MagicBrush 在此失败),从而执行编辑操作。在示例 5 中,其对飞机标志和文本的精准保留进一步证明了强大的对象保留能力
上图展示了 GPT-4o 在图像编辑任务中的具体表现,尤其是在处理复杂对象时的精准识别和保留能力。
与其他图像编辑模型相比,GPT-4o 在主体保留和指令遵循能力上具有明显优势。它能够准确地识别出图像中的主体对象,并在编辑过程中保持其完整性,不会出现其他模型常见的主体模糊、变形或者丢失等问题。同时,它对编辑指令的理解和执行也非常精准,能够严格按照用户的要求进行图像修改,而不是像一些其他模型那样,对指令产生误解或者执行不到位,导致编辑结果与用户预期相差甚远。
定制化:专属图像,满足个性化的无限想象
在定制化任务中,GPT-4o 像是一位贴心的私人定制设计师,能够根据给定的参考图像和文本描述,生成符合要求的定制化图像。图20 和图21 分别展示了 GPT-4o 在单概念定制化和多概念定制化任务中的表现,与 Gemini 2.0 Flash 和其他基线模型相比,其生成的图像在概念再现和文本对齐方面表现出色。

Figure 20: 任务:单概念定制。目标是生成能够忠实再现参考图像中的单一视觉概念的图像,同时与给定的文本描述保持一致。设置:参考图收集自先前工作,结果比较包括 GPT-4o、Gemini 2.0 Flash 和 DisEnvisioner。每行包含输入参考图、文本提示及相应输出。观察结果:GPT-4o 在忠实再现单一视觉概念方面表现出色,保真度高且紧密贴合给定文本描述。它始终超越 Gemini 2.0 Flash,并取得与 SOTA 方法 DisEnvisioner 媲美的成果。然而,部分生成图像仍有轻微“复制 - 粘贴”伪影,表明仍有改进空间。

Figure 21: 任务:多概念定制。目标是生成能够有效整合参考图像中的多个视觉概念的图像,同时与给定的文本描述保持一致。设置:参考图收集自先前工作,结果比较包括 GPT-4o、Gemini 2.0 Flash 和 MS-Diffusion。每行包含输入参考图、文本提示及相应输出。观察结果:在整合多个视觉概念方面,GPT-4o 取得了具有竞争力的成果,对各个概念的保真度高且与文本提示对齐良好。然而,面对独特或复杂的组合时,其性能有所下降。尽管如此,GPT-4o 仍超越了 Gemini 2.0 Flash,并取得了与 SOTA 方法相当的成果
在单概念定制化任务中,它能够忠实地再现参考图像中的视觉概念,并紧密贴合文本描述的要求。例如,在要求它根据一张狗的图片和 “一只戴着红色帽子的狗” 这样的文本描述生成图像时,它能够精准地将狗的形象与红色帽子这一元素结合在一起,生成的图像既保留了参考图像中狗的形态特征,又符合文本描述的定制化要求。与 Gemini 2.0 Flash 相比,GPT-4o 在定制化任务中展现出更精准的概念再现能力和文本对齐能力,尽管它的生成图像中偶尔还会出现一些 “复制 - 粘贴” 般的细微瑕疵,但整体效果已经相当出色。
对于多概念定制化任务,GPT-4o 依然能够展现出较强的竞争力。它能够在不同上下文中有效地结合多个视觉概念,生成符合要求的图像。不过,当面对某些独特组合(如让一只狗穿上人类的连衣裙)时,它可能会出现一些困难,这可能是因为训练数据中缺乏相关的定制化样本,导致模型在处理这类特殊组合时缺乏足够的经验。尽管如此,它在多概念定制化任务中的表现依然优于 Gemini 2.0 Flash,并且与当前最先进的定制化方法不相上下。
故事图像生成:用图像编织连贯的故事章节
GPT-4o 在故事图像生成任务中,展现出了强大的叙事连贯性和面板连续性能力,仿佛是一位擅长讲故事的漫画家,能够根据输入的文本叙述,生成一系列连贯且富有表现力的故事图像。图22 和图23 分别展示了 GPT-4o 在短篇故事和长篇故事生成任务中的表现,与 Gemini 2.0 Flash 和 StoryDiffusion 等模型相比,其生成的故事图像在连贯性和表现力方面更具优势。

Figure 22: 任务:故事图像生成。目标是基于叙事文本生成连贯的故事序列,可选择以前期故事画面或角色图像为条件。设置:每个示例整合输入的叙事文本(以及在有的情况下参考角色图像)与一系列生成的故事面板。将 GPT-4o 的输出与 Gemini 2.0 Flash、StoryDiffusion 和 SEED-Story 进行比较。观察结果:GPT-4o 呈现出强大的叙事连贯性和画面连续性,达到或超越了通用基线水平

Figure 23: 任务:故事图像生成。目标是基于叙事文本生成连贯的故事序列,可选择以前期故事画面或角色图像为条件。设置:每个示例整合输入的叙事文本(以及在有的情况下参考角色图像)与一系列生成的故事面板。将 GPT-4o 的输出与基线模型(包括 Gemini 2.0 Flash 和 DiffSensei)进行比较。观察结果:在特定情境下(例如日本黑白漫画),GPT-4o 在精确角色一致性和画面数量方面略有不足,而像 DiffSensei 这类专用模型表现出更佳的性能
在面对简短的故事叙述时,它能够生成包含多个面板的连贯故事图像,每个面板都能够准确地反映故事的不同情节,并且在图像风格和人物形象上保持一致。例如,对于一个关于渔夫的三段式故事,它能够生成三个相互关联的图像面板,分别展示渔夫准备出海、在海边劳作以及满载而归的场景,整个故事通过图像被完整而生动地展现出来。与 Gemini 2.0 Flash 相比,GPT-4o 在故事图像生成中更注重叙事的连贯性和图像的连续性,而 Gemini 2.0 Flash 有时会生成内容混乱的单一面板图像,无法清晰地传达出完整的故事。
在处理更长的故事叙述时,GPT-4o 依然能够保持较好的性能。它能够根据用户提供的文本叙述和前面已经生成的图像,逐步生成后续的故事图像,确保整个故事在图像中连贯地展开。然而,当涉及到特定风格(如日本黑白漫画)的图像生成时,GPT-4o 的表现虽然较好,但在人物形象的连贯性、面板数量的精准性等方面仍有提升空间。与专门为日本黑白漫画生成设计的方法(如 DiffSensei)相比,GPT-4o 在这些细节上的处理还不够精细,这表明在特定领域的图像生成任务中,针对特定风格和要求进行优化的模型仍然具有一定的优势。
低级视觉任务表现:雕琢图像细节的匠心工艺
图像去噪、去雨、去雾等任务:驱散阴霾,还原清晰视界
在低级视觉任务中的图像去噪、去雨、去雾等方面,GPT-4o 显示出了不俗的能力,它能够有效地去除图像中的各种干扰因素,恢复出更加清晰、干净的图像内容。图24 展示了 GPT-4o 在图像去噪任务中的表现,与 Gemini 2.0 Flash 和 InstructIR 相比,其生成的图像在细节保留和噪声去除方面更为出色。

Figure 24: 任务:图像去噪,旨在去除噪声信息,获取高质量清晰版本。设置:将 GPT-4o 与 InstructIR 和 Gemini 2.0 Flash 进行比较,评估去噪后的图像。观察结果:GPT-4o 能够恢复高质量的去噪图像。除了第二张图像(无法完全去除噪声)外,其他图像均无噪声明显。然而,在低级任务中,GPT-4o 对内容一致性的保持不佳 —— 许多图像的背景色和物体形状发生了变化,例如第一张图像的背景色和第四张图像的地板。
在图像去噪任务中,GPT-4o 能够精准地识别出图像中的噪声点,并将其去除,同时保留图像中的重要细节和纹理信息。例如,在处理一张充满噪点的夜景照片时,它能够使画面变得光滑干净,同时依然能够清晰地呈现出夜景中的建筑轮廓、灯光效果等细节。
在去雨任务中,图25 展示了 GPT-4o 的表现,它能够将雨滴在图像上留下的条纹痕迹抹去,还原出没有下雨时的场景。对于雨滴落在玻璃上形成的复杂痕迹,GPT-4o 能够准确地分析其形状和分布,并将其去除,使背景的景象变得清晰可见。

Figure 25: 任务:图像去雨,旨在去除雨痕,获取高质量清晰版本。设置:将 GPT-4o 与诸如 InstructIR 和 Gemini 2.0 Flash 之类的成熟基线进行比较,评估去雨后的图像。观察结果:GPT-4o 的整体表现良好。然而,该模型在维持低级视觉细节的内容一致性方面存在困难 —— 例如,第一张图像中北极熊的背景不自然地变粉,水下场景失去深度和清晰度,花朵的颜色和排列也出现变化。相比之下,InstructIR 在所有示例中展现出最为一致的性能,能有效地去除雨水,同时保留原始场景的结构、色彩和构图。总体而言,在此次比较中,InstructIR 是图像修复最为均衡且精准的模型。
在去雾任务中,下图展示了 GPT-4o 的能力,它能够有效地去除雾气对图像的影响,增强图像的对比度和清晰度,让原本被雾气笼罩的景物重新展现出来。例如,对于一张在大雾天气下拍摄的山景照片,GPT-4o 可以将其转换成一幅清晰可见山峦起伏、植被分布的图像,让观者仿佛能够感受到山间的清新空气。

Figure 26: 任务:图像去雾,旨在去除雾气信息,获取高质量清晰版本。设置:将 GPT-4o 与诸如 InstructIR 和 Gemini 2.0 Flash 之类的成熟基线进行比较,评估去雾后的图像。观察结果:GPT-4o 在去雾方面表现尚可,能够在多数场景中恢复更清晰的结构和对比度。然而,其输出图像常带有灰暗或脱色的色调,尤其在第二和第三行中较为明显。Gemini 2.0 Flash 生成的图像色彩更为丰富,但往往残留部分雾气,导致输出不够锐利。相比之下,InstructIR 的表现最为出色,在所有示例中提供了最自然、最锐利的去雾效果,同时保留了原始色彩和细节。总体而言,InstructIR 在消除雾气同时保持真实感方面展现出最强大的能力。
与 Gemini 2.0 Flash 相比,GPT-4o 在这些图像恢复任务中生成的图像质量更高,细节更加丰富。而与专门用于图像恢复的 InstructIR 模型相比,GPT-4o 在去噪任务中的表现稍逊一筹,无法像 InstructIR 那样将图像中因噪声而模糊的背景颜色和物体形状完全恢复到原始状态。但在去雨和去雾任务中,GPT-4o 与 InstructIR 的表现相当,都能够有效地去除干扰因素,生成较为满意的图像。
图像超分辨率、修复与外推:重塑图像,绽放全新活力
在图像超分辨率、修复与外推任务中,GPT-4o 能够显著增强图像的细节和视觉效果,将低分辨率图像转换成高分辨率图像,并且能够对图像中缺失或损坏的部分进行合理的修复和外推。图27 展示了 GPT-4o 在图像超分辨率任务中的表现,与 Gemini 2.0 Flash 相比,其生成的高分辨率图像在细节丰富度和图像质量上都更为出色。

Figure 27: 任务:低光照图像增强,旨在提高图像亮度以获得高亮度图像。设置:将 GPT-4o 与诸如 InstructIR 和 Gemini 2.0 Flash 之类的成熟基线进行比较,评估图像亮度。观察结果:在低光照增强任务中,GPT-4o 可以提高图像亮度并恢复基本可视度,但常常引入不自然的光照并丢失细节,特别是在第二行中,图像仍然过暗。相比之下,InstructIR 始终提供最均衡的结果,在提升可视度的同时保留真实的色彩和纹理,使其在所有三个示例中表现最佳。
在图像超分辨率任务中,它能够根据图像中的已有信息,合理地添加细节,使图像的分辨率得到提高,同时保持图像的自然度和真实感。例如,将一张模糊的人物照片转换成一张清晰的高分辨率照片,GPT-4o 能够准确地恢复出人物的面部细节、头发纹理等关键信息,让人物形象更加生动逼真。
在图像修复任务中,图28 展示了 GPT-4o 的能力,对于图像中被遮挡或者损坏的区域,GPT-4o 能够根据周围的内容进行合理的填充和修复。比如在一幅风景画中,如果有一块大面积的污渍遮挡了部分景色,GPT-4o 可以根据周围的山川、河流、树木等元素,生成符合整体画面风格的内容来填补空白区域,使画面恢复完整。

Figure 28: 任务:图像去模糊,旨在去除模糊信息以获得清晰图像。设置:将 GPT-4o 与诸如 InstructIR 和 Gemini 2.0 Flash 之类的成熟基线进行比较,评估去模糊后的图像。观察结果:在运动去模糊方面,GPT-4o 恢复了一些清晰度,特别是在诸如文本或面部等细节上,但内容与原始图像不匹配。Gemini 2.0 Flash 在某些情况下锐化图像稍好,但可能引入过度平滑,使结果看起来不自然。总体而言,InstructIR 展示了最佳的去模糊性能 —— 恢复清晰的边缘、面部特征和文本,同时保持自然纹理。它始终如一地在所有示例中产生最稳定且视觉上最令人信服的结果
在图像外推任务中,图29 展示了 GPT-4o 的表现,它能够基于图像的边界信息,合理地扩展图像的内容,生成新的区域,让图像看起来更加完整和丰富。例如,对于一张只拍摄到人物上半身的照片,GPT-4o 可以外推生成人物的下半身以及周围的环境,使其变成一张全身照片。

Figure 29: 任务:图像超分辨率,旨在提高图像分辨率。设置:将 GPT-4o 与诸如 InstructIR 和 Gemini 2.0 Flash 之类的成熟基线进行比较,评估去模糊后的图像。观察结果:在超分辨率方面,InstructIR 在所有示例中提供了最自然且详细的结果 —— 恢复了读卡器上的细微边缘、章鱼上的逼真纹理以及风景中的锐利树木。GPT-4o 提高了清晰度,但错过了诸如章鱼表面和树叶等细节。Gemini 2.0 Flash 产生的图像比 GPT-4o 更加锐利,但在章鱼和树叶等有机区域引入了不自然的纹理和伪影
与其他模型相比,GPT-4o 在这些任务中展现了更强大的细节生成能力和整体一致性。它生成的高分辨率图像在细节丰富度和图像质量上都优于 Gemini 2.0 Flash,但在像素一致性和图像内容保真度方面,与专门用于图像恢复的 InstructIR 模型相比还有一定的差距。InstructIR 更注重于像素级的精确修复,能够更好地保持图像的原始结构和内容,而 GPT-4o 则更倾向于在整体风格和视觉效果上进行优化,可能会对图像内容进行一定的调整和修改,以达到更好的视觉效果。
图像上色与重打光:赋予图像色彩与光影的魅力
在图像上色与重打光任务中,GPT-4o 能够为灰度图像添加生动的色彩,或者对已有图像的光照效果进行重新调整,使其呈现出不同的视觉氛围。图30 展示了 GPT-4o 在图像上色任务中的表现,与 Gemini 2.0 Flash 和其他基线模型相比,其生成的上色图像色彩鲜艳、自然,符合物体的实际特征和场景的氛围要求。
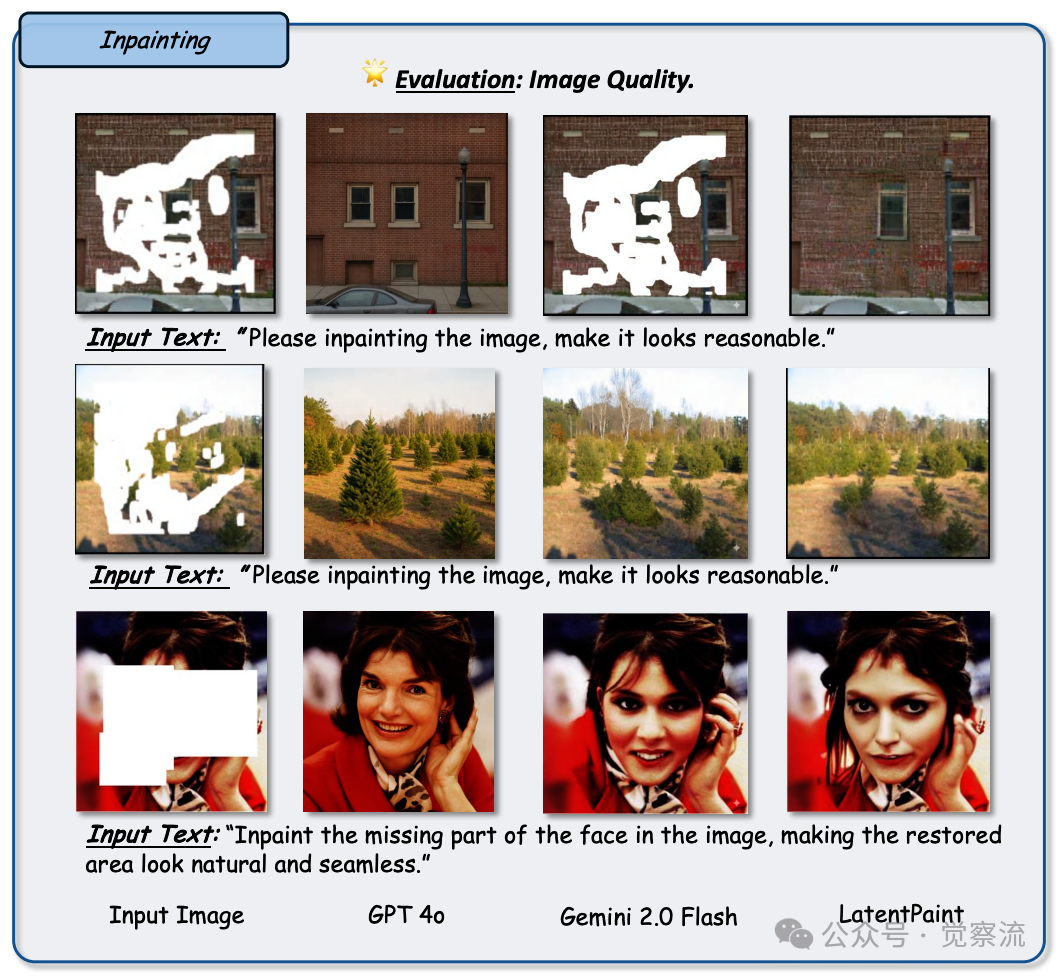
Figure 30: 任务:图像修复,旨在恢复图像中缺失或被遮挡的区域,使其自然且与上下文一致。设置:将 GPT-4o 与诸如 Gemini 2.0 Flash 和 LatentPaint 之类的基线进行比较,评估其真实填补遮挡区域的能力。观察结果:GPT-4o 能够生成合理的补全,但通常缺乏精细结构和纹理对齐 —— 例如,第一行的砖块显得平坦且错位。Gemini 2.0 Flash 生成的纹理在视觉上更为连贯,尤其是在像第二行这样的自然场景中,但可能会引入轻微的过度平滑。LatentPaint 表现最佳,准确地重建了面部细节以及第三行中诸如头发和表情等复杂纹理,展示了卓越的语义理解和视觉一致性
在图像上色任务中,它能够根据图像的内容和上下文信息,合理地选择颜色并将其应用到图像中。例如,对于一幅黑白的历史建筑照片,GPT-4o 可以根据建筑的材质、年代、风格等因素,为其添加逼真的色彩,让这些建筑仿佛重新焕发生机。
在重打光任务中,图31 展示了 GPT-4o 的能力,它能够根据用户的指令或者参考图像的光照效果,对图像中的光照进行调整。比如,将一张在日光下拍摄的照片转换成在烛光下的温馨氛围,或者将一张室内照片的光照调整成黄昏时分的柔和光线效果。

Figure 31: 任务:图像外扩,旨在将图像的视觉内容连贯且真实地扩展到原始边界之外。设置:将 GPT-4o 与 Gemini 2.0 Flash 以及一些专用外扩方法(SGT +、StrDiffusion 和 Dream360)进行比较,评估其在扩展内容的同时保持光照、纹理和语义视觉一致性方面的能力。观察结果:专用外扩方法始终生成最连贯的扩展 —— 例如,在第一行中准确保持房间的光照和装饰,在第二行中延续建筑线条和街道透视,并在第三行中创建无缝的雪景。GPT-4o 提供了合理的结构,但通常缺乏细节和纹理的连贯性,如雪的渐变不匹配或缺少阴影。Gemini 2.0 Flash 在语义扩展方面比 GPT-4o 稍胜一筹,但在广阔场景(如最后一行的沙漠)中可能会引入光照不一致和突兀的过渡
GPT-4o 能够准确地分析图像中的物体形状、材质以及场景布局,合理地调整光照方向、强度和颜色,使图像呈现出用户期望的光照效果。然而,在某些情况下,GPT-4o 可能会对图像内容产生一定的误解,导致颜色或光照效果不符合用户的预期。例如,当用户要求将图像中的某个物体设置为特定颜色时,GPT-4o 可能会因为对物体的识别不准确而添加错误的颜色。此外,在处理复杂光照场景时,它的表现可能不如专门用于光照估计和调整的模型(如 IC-Light),这些模型在处理多光源、复杂材质和遮挡关系的光照场景时更加精准和细腻。
空间控制任务表现:精准操控图像空间的奇妙法则
在空间控制任务中,GPT-4o 能够根据 canny、深度、草图、姿态和蒙版等不同的条件约束,生成符合要求的图像。图32 至图36 分别展示了 GPT-4o 在基于 canny 边缘图、深度图、草图、姿态图和蒙版的图像生成任务中的表现,与基于 ControlNet 的方法和 Gemini 2.0 Flash 相比,其生成的图像在整体质量和细节表现方面具有一定的优势。

Figure 32: 任务:图像上色,旨在根据文本提示为灰度图像添加逼真且语义一致的色彩。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 CtrlColor 进行比较,重点关注它们遵循指令和生成自然上色结果的能力。观察结果:总体而言,CtrlColor 表现最佳,生成的色彩生动准确,与提示精确匹配 —— 例如最后一行中的绿色嘴唇和黄色太阳镜,或第二行中的紫色草地和小猫的色调。GPT-4o 的上色较为忠实,但常常缺乏丰富性或误判色调(例如第三行中的暗红色或不一致的紫色草地)。Gemini 2.0 Flash 比 GPT-4o 更加生动,但容易过度饱和或产生风格化效果,尤其是在人物特征上

Figure 33: 任务:阴影去除,旨在消除生硬阴影,同时保持场景、纹理和光照平衡的完整性。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 ShadowRefiner 进行比较,评估每种方法去除阴影和保留原始对象保真度及光照一致性方面的能力。观察结果:ShadowRefiner 始终实现最自然且有效的阴影去除。它在所有场景中产生均匀、扩散的光照 —— 例如,在复杂场景(如微型模型和狗肖像)中软化阴影而不扭曲纹理。Gemini 2.0 Flash 合理地去除了阴影,但偶尔会留下淡淡的痕迹或压平对比度,如在第二行和第四行中所见。GPT-4o 的阴影减少比 Gemini 2.0 Flash 更强,但有时会改变表面亮度或丢失细节保真度。ShadowRefiner 在消除生硬阴影的同时,最佳地保留了原始色彩色调和纹理

Figure 34: 任务:反射去除,旨在从透明或反光表面消除不需要的反射,同时保留原始内容和逼真的光照。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 DSIT 进行比较,评估其在去除反射的同时保持场景真实感、纹理保真度和光照一致性方面的能力。观察结果:在所有示例中,DSIT 展示了最有效且自然的反射去除效果。它通过窗户恢复室内可视性(例如床和汽车内部),同时保留光照和几何形状。Gemini 2.0 Flash 去除了一些反射,但常常留下褪色痕迹或使纹理变得暗淡,特别是在玻璃门和湿地上。GPT-4o 在保留背景细节方面比 Gemini 2.0 Flash 表现更好,但有时会改变色调和锐度。总体而言,DSIT 提供了最干净且最写实的结果,特别是对于玻璃和反光湿地板等透明表面

Figure 35: 任务:图像重新光照,旨在根据参考光照图或文本描述修改给定图像的光照,同时保留身份、纹理和空间一致性。设置:在两个子任务(基于参考图和基于文本的重新光照)上将 GPT-4o 与 Gemini 2.0 Flash 和 IC-Light 进行比较。评估重点关注光照真实性、方向性、阴影准确性和语义保留。观察结果:在两项任务中,IC-Light 实现了最真实且一致的重新光照 —— 准确地从参考图像应用霓虹灯效果,并根据文本提示生成锐利阴影和自然光。Gemini 2.0 Flash 良好地保留了内容,但产生的光照较为柔和,方向性不足。GPT-4o 提供的光照比 Gemini 2.0 Flash 更生动,但有时缺乏阴影准确性或背景连贯性

Figure 36: 任务:Canny 边缘图到图像生成。目标是根据 Canny 边缘图生成与提示对齐的图像。设置:每行展示输入的 Canny 边缘图和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 FLUX.1-Dev(搭配 ControlNet)的输出。观察结果:在结构保真度方面,GPT-4o 不如 FLUX.1-Dev,常常引入偏离输入边缘图的额外视觉细节。然而,从整体上看,它生成的结果在语义对齐和审美上更令人满意。与 Gemini 2.0 Flash 相比,GPT-4o 在结构保留和提示一致性方面显著胜出
在基于 canny 边缘图的图像生成任务中,GPT-4o 能够以给定的边缘图为依据,生成相应的图像内容。它能够较好地遵循边缘图的轮廓和结构信息,生成具有相应形状和细节的物体。例如,当给定一个汽车的 canny 边缘图时,GPT-4o 可以生成出汽车的整体外观,包括车身轮廓、车轮、车窗等主要部件,并且这些部件的位置和形状与边缘图的指示基本一致。
在基于深度图的图像生成任务中,图37 展示了 GPT-4o 的能力,它能够根据深度信息生成具有立体感的图像,使物体的远近关系和层次感得到较好的体现。例如,根据一幅场景的深度图,GPT-4o 可以生成出前景、中景和背景层次分明的图像,让观者能够直观地感受到场景的深度和空间感。

Figure 37: 任务:深度图到图像生成,旨在根据文本提示和给定深度图合成可控制且视觉上连贯的图像。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 FLUX.1-Dev(搭配 ControlNet)进行比较,重点关注可控性、文本提示对齐以及生成场景的视觉质量。观察结果:GPT-4o 生成的图像在视觉上吸引人且风格一致,与文本和深度线索的对齐较为合理 —— 例如具有丰富光照和艺术氛围的桥场景和石头废墟。然而,其可控性弱于 FLUX.1-Dev(搭配 ControlNet),后者展现出更精准的深度对齐和对象放置,如桥和红色枕头的精确布局。GPT-4o 倾向于风格化一致性,而 FLUX 则强调具有更锐利空间保真度的写实主义。Gemini 2.0 Flash 落后于两者,常出现深度错位、形状扭曲以及语义基础薄弱的问题
在基于草图的图像生成任务中,图38 展示了 GPT-4o 的能力,它能够将简单的线条草图转化为逼真的图像,为设计师和艺术家提供了一种快速将创意转化为视觉作品的工具。比如,将一幅手绘的人物草图生成为一张具有逼真肤质、服装纹理和背景细节的完整图像。

Figure 38: 任务:草图到图像生成,要求将粗略的线条图转换为由文本提示引导的逼真且语义准确的图像。设置:评估 GPT-4o 与 Gemini 2.0 Flash 和 SDXL1.0(搭配 ControlNet)相比,在尊重提供的草图并反映所描述内容方面的表现。观察结果:GPT-4o 擅长生成与提示匹配的逼真场景,常常提供视觉上令人愉悦且基于上下文的输出 —— 例如长颈鹿的自然姿态和环境,或降落伞示例中的动态运动。然而,它倾向于软化或重新诠释草图线条,导致细微结构略有不符。相比之下,SDXL1.0(搭配 ControlNet)对输入草图的遵循更为严格,能够更准确地捕捉几何细节(例如扇叶和人物轮廓),尽管其纹理稍显合成。Gemini 2.0 Flash 对草图和提示的理解有限,常常生成不够逼真或结构偏离目标的图像
在基于姿态图的图像生成任务中,图39 展示了 GPT-4o 的能力,它能够根据人物的姿态信息生成相应的图像,确保人物的动作和姿势符合给定的姿态图。例如,根据一张人物舞蹈的姿态图,它能够生成出人物在该姿态下的完整形象,包括服装的飘动、肢体的伸展等细节,使图像生动而富有动感。

Figure 39: 任务:姿态到图像生成,旨在合成能反映人体姿态和描述性提示的逼真图像。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 SD3 Medium(搭配 ControlNet)进行基准测试,评估其在遵循姿态条件的同时生成语义准确且连贯图像的能力。观察结果:GPT-4o 在复杂场景中表现出色 —— 例如橄榄球示例,它能有效地将姿态、服装和背景与强烈的现实感、上下文和姿态准确性相整合。在诸如引体向上这类简单案例中,它偶尔会出现姿态偏移,特别是在四肢部分。总体而言,SD3 Medium(搭配 ControlNet)提供更好的姿态保真度,尽管其视觉质量可能不稳定。Gemini 2.0 Flash 在结构和连贯性方面表现不佳,常常生成解剖学上不正确或视觉效果欠佳的结果。总的来说,GPT-4o 在文本理解和生成质量之间取得了平衡,尤其是在详细的提示中
在基于蒙版的图像生成任务中,图40 展示了 GPT-4o 的能力,它能够根据蒙版指示的区域和形状生成相应的图像内容,填充到指定的区域内。比如,在一张背景图像中,根据蒙版生成一个特定形状的物体,使其自然地融入到背景中。

Figure 40: 任务:蒙版到图像生成,要求将语义分割图和文本提示转换为连贯且逼真的图像。设置:将 GPT-4o 与 Gemini 2.0 Flash 和 SD1.5(搭配 ControlNet)进行比较,重点关注其将蒙版的空间布局与提示的深层场景理解相结合的能力。观察结果:与之前的控制任务相比,此设置对模型在语义推理和构图理解方面提出了更高要求。GPT-4o 在这方面表现出色,生成的视觉场景与提示的意图一致 —— 例如宁静的教堂内部和访客如织的沉浸式水族馆环境。然而,在精细的空间控制方面,特别是对于热带鱼这类小型或形状紧凑的对象,SD1.5(搭配 ControlNet)在保持形状和定位方面表现更佳。Gemini 2.0 Flash 在保真度和对蒙版的遵循方面仍有困难,常常遗漏关键场景元素或生成过于简化的输出
与基于 ControlNet 的方法相比,GPT-4o 在空间控制任务中展现了相当的性能,在多数情况下能够生成符合要求的图像。它在处理语义丰富或上下文复杂的情况时,能够凭借其强大的基础模型理解能力,更好地保留图像的高层语义和视觉合理性。然而,GPT-4o 的强大生成先验有时也会导致它在需要精细几何对齐的任务中,如 canny-to-image 或 depth-to-image 任务中,更容易偏离输入的布局,相比传统扩散方法在低级结构引导场景中展现出更稳定的控制能力。ControlNet 在这些任务中通常能够更精准地贴合输入的边缘或深度信息,生成的图像在结构上更加准确和稳定,因此在对空间精度要求极高的应用场景中更具优势。而 Gemini 2.0 Flash 在所有评估的控制类型中,其输出通常无法准确匹配控制条件或文本提示,反映出其在多模态对齐和结构基础方面的局限性,生成的图像往往结构模糊、内容偏差较大,无法有效满足空间控制任务的要求。
相机控制任务表现:掌控摄影参数的艺术魔法
在相机控制任务中,GPT-4o 展现出了对摄影参数的一定掌控能力,能够根据文本指令对图像进行相机参数调整,模拟出不同的摄影效果。图41 展示了 GPT-4o 在光圈模糊参数控制任务中的表现,与 Gemini 2.0 Flash 相比,其生成的图像能够更好地模拟出不同光圈大小下的景深效果,主体清晰、背景虚化自然,更符合专业摄影的视觉效果。

Figure 41: 任务:相机控制。目标是生成与特定摄影参数(如散景虚化、焦距、快门速度和色温)对齐的图像。设置:基于从 [118] 收集的文本提示,比较 GPT-4o、Gemini 2.0 Flash 和生成式摄影(GP)的输出。每行包含输入的文本指令和相应的输出。观察结果:GPT-4o 在控制散景虚化方面表现出色,生成的图像视觉效果佳且与参数对齐。然而,在处理焦距方面存在局限性,偶尔生成不一致或不够准确的输出。相比之下,Gemini 2.0 Flash 在这两方面均表现不佳,常常无法生成连贯的结果。总体而言,GPT-4o 在该任务中表现更佳,但仍需进一步优化以提升焦距控制能力
在光圈模糊参数控制方面,GPT-4o 能够较好地模拟出不同光圈大小下的景深效果。例如,当要求它生成具有浅景深、背景虚化明显的图像时,它能够生成出主体清晰、背景呈现出柔和模糊效果的图像,类似于使用大光圈拍摄的照片。这种对光圈模糊效果的模拟能够让图像更具艺术感和专业感,突出主体对象,营造出不同的视觉氛围。
在色温调整方面,图42 展示了 GPT-4o 的能力,它能够根据指令生成具有不同色温氛围的图像。比如,将一张普通照片调整为具有暖色调(高色温)或者冷色调(低色温)的效果,它能够准确地改变图像的整体色彩倾向,让图像呈现出相应的暖意或冷感。这在摄影和视觉创作中是非常实用的功能,可以帮助创作者快速营造出不同的情感和氛围。
 Figure 42: 任务:相机控制。目标是生成与特定摄影参数(如散景虚化、焦距、快门速度和色温)对齐的图像。设置:基于从 [118] 收集的文本提示,比较 GPT-4o、Gemini 2.0 Flash 和生成式摄影(GP)的输出。每行包含输入的文本指令和相应的输出。观察结果:GPT-4o 在控制色温方面表现出色,生成的结果连贯且视觉上准确。然而,它在快门速度方面存在困难,偶尔导致不一致或不真实的运动效果。相比之下,Gemini 2.0 Flash 无法稳定地处理这两个参数,生成的结果常常与期望设置不符。总体而言,GPT-4o 在此任务中优于 Gemini 2.0 Flash,但快门速度控制的精确性仍有待提高
Figure 42: 任务:相机控制。目标是生成与特定摄影参数(如散景虚化、焦距、快门速度和色温)对齐的图像。设置:基于从 [118] 收集的文本提示,比较 GPT-4o、Gemini 2.0 Flash 和生成式摄影(GP)的输出。每行包含输入的文本指令和相应的输出。观察结果:GPT-4o 在控制色温方面表现出色,生成的结果连贯且视觉上准确。然而,它在快门速度方面存在困难,偶尔导致不一致或不真实的运动效果。相比之下,Gemini 2.0 Flash 无法稳定地处理这两个参数,生成的结果常常与期望设置不符。总体而言,GPT-4o 在此任务中优于 Gemini 2.0 Flash,但快门速度控制的精确性仍有待提高
然而,GPT-4o 在调整焦距和快门速度方面还存在一定的局限性。在焦距调整任务中,它有时无法准确地模拟出不同焦距下图像的透视变化和景深差异,导致生成的图像在视觉效果上与预期的焦距参数不完全一致。例如,当要求模拟长焦距拍摄的效果(如远处的物体被拉近、背景虚化明显且具有一定的压缩感)时,GPT-4o 生成的图像可能在透视关系和景深层次上出现偏差,无法完全达到专业摄影中长焦距镜头所带来的视觉效果。在快门速度调整任务中,它在模拟运动物体的拖影效果或者冻结运动效果时也存在一定的困难。例如,当要求生成一幅快门速度较慢、运动物体带有明显拖影的图像时,GPT-4o 生成的图像可能在拖影的自然度和连贯性上不够理想,无法准确地呈现出由于快门速度变化而产生的运动模糊效果,甚至可能会出现一些不真实的视觉伪影,影响整体的摄影效果模拟质量。
与 Gemini 2.0 Flash 相比,GPT-4o 在相机控制任务中表现出了更强的能力。Gemini 2.0 Flash 在处理所有相机控制场景时,往往无法生成与指定摄影参数相匹配的合理图像,其输出结果在视觉语义一致性、参数准确性等方面存在明显缺陷,生成的图像常常结构混乱、内容偏差较大,难以满足相机控制任务的要求。而 GPT-4o 虽然在某些参数调整方面还有待提高,但已经能够在部分相机参数控制任务中生成较为满意的结果,展现出了一定的专业摄影模拟潜力。
 Figure 43: 任务:上下文视觉提示。目标是基于特定任务的示例图像和文本指令,对新的查询图像执行特定的视觉任务。设置:评估四个具有代表性的任务:电影镜头生成、光线追踪渲染、叠加掩码可视化和迷宫求解。每行包含示例图像、查询图像和相应的输出。观察结果:GPT-4o 在电影镜头生成和光线追踪方面表现出色,生成的输出连贯,但在视觉语义一致性方面有所欠缺。在叠加掩码可视化和迷宫求解任务上表现不佳,显示出在复杂任务集成方面的局限性。尽管在上下文视觉提示方面显示出潜力,但在更复杂且推理密集型的任务上仍需改进
Figure 43: 任务:上下文视觉提示。目标是基于特定任务的示例图像和文本指令,对新的查询图像执行特定的视觉任务。设置:评估四个具有代表性的任务:电影镜头生成、光线追踪渲染、叠加掩码可视化和迷宫求解。每行包含示例图像、查询图像和相应的输出。观察结果:GPT-4o 在电影镜头生成和光线追踪方面表现出色,生成的输出连贯,但在视觉语义一致性方面有所欠缺。在叠加掩码可视化和迷宫求解任务上表现不佳,显示出在复杂任务集成方面的局限性。尽管在上下文视觉提示方面显示出潜力,但在更复杂且推理密集型的任务上仍需改进
图像到 3D(Image-to-3D)任务表现:二维到三维的跨越之旅
从 2D 图像到 3D 模型的生成:解锁三维世界的神秘大门
在从 2D 图像到 3D 模型的生成任务中,GPT-4o 展现出了令人惊叹的能力。它能够根据输入的 2D 图像,生成相应的 3D 模型渲染图,生成的模型在结构、材质和线框等方面与输入图像具有较高的相似度。图44 展示了 GPT-4o 在这一任务中的表现,与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,其生成的 3D 模型渲染图在结构准确性、材质表现力和视觉效果等方面都更为出色。

Figure 44: 任务:图像到 3D 模型渲染。评估给定 2D 图像的 3D 建模能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Midjourney v6.1 的输出。观察结果:与其他两个模型相比,GPT-4o 能够生成形状、纹理一致且线框合理的更好的 3D 模型渲染效果
例如,当给定一张汽车的 2D 图像时,GPT-4o 可以生成出该汽车的 3D 模型,模型的外观形状、车门、车窗、车轮等主要部件的位置和比例与原图基本一致,并且能够呈现出相应的材质质感,如金属车身的反光效果、车窗玻璃的透明感等。与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,GPT-4o 能够更好地捕捉 2D 图像中的三维信息,将其转化为更加逼真和完整的 3D 模型。这一能力为 3D 建模领域带来了新的可能性,尤其是在快速原型制作、虚拟场景构建等方面具有广阔的应用前景。
2D UV 映射到 3D 渲染:纹理映射的奇幻之旅
在 2D UV 映射到 3D 渲染任务中,GPT-4o 能够根据给定的 2D UV 映射图生成相应的 3D 渲染图像。图45 展示了 GPT-4o 在这一任务中的表现,与 Gemini 2.0 Flash 和 Midjourney v6.1 相比,其生成的 3D 渲染图像在纹理映射和视觉效果方面更具优势。

Figure 45: 任务:2D UV 图到 3D 渲染。评估 3D 感知和空间理解能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Midjourney v6.1 的输出。观察结果:与其他两个模型相比,GPT-4o 能够基于 2D 地图生成更好的 3D 渲染效果。然而,这三种模型之间在结构和图案上的一致性问题仍然存在
例如,对于一张带有纹理图案的 UV 映射图,GPT-4o 可以将其生成为一个具有相应纹理的 3D 物体,如带有花纹的陶瓷花瓶、带有木质纹理的桌子等,纹理在 3D 模型表面的分布自然、均匀,与模型的形状和结构相匹配。然而,在某些情况下,GPT-4o 生成的 3D 渲染图像仍然存在一些问题,如图案和结构的不一致。这可能是由于 UV 映射图的复杂性或者模型对纹理映射的理解不够精确所导致的。与其他基线模型相比,GPT-4o 在这一任务中展现了更强的纹理映射能力和 3D 理解能力,能够生成出更高质量的 3D 渲染图像,但在处理一些高精度、复杂纹理的 UV 映射任务时,仍有提升的空间。
新视图合成:多重视角,探索物体的完整形态
在新视图合成任务中,GPT-4o 能够根据输入的图像生成新的视图,保持与原始图像在结构和风格上的一致性。图46 展示了 GPT-4o 在这一任务中的表现,与 Gemini 2.0 Flash 相比,其生成的新视图在结构和风格一致性保持方面更为优秀。

Figure 46: 任务:新视图合成。评估 3D 感知和空间理解能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Midjourney v6.1 的输出。观察结果:对于艺术绘画和不对称物体,GPT-4o 能够生成风格和结构更为一致的新颖视图
对于具有艺术风格的物体,如一幅油画风格的图像,GPT-4o 可以生成出从不同角度观察该物体的新视图,新视图中的物体形状、颜色、笔触等元素与原图保持高度一致,仿佛是从不同角度拍摄的同一幅油画。对于具有不对称几何形状的物体,如一个造型奇特的雕塑,GPT-4o 也能够较好地保持物体的规模和尺寸,生成从其他视角看到的合理视图,让观者能够更加全面地了解物体的三维形态。与 Gemini 2.0 Flash 相比,GPT-4o 在新视图合成任务中表现出更好的结构和风格一致性保持能力,能够更准确地捕捉原始图像的三维信息和风格特征,生成更加真实可靠的新视图。
图像到 X(Image-to-X)任务表现:解锁图像的多元奥秘
图像分割:精准拆解,洞察图像的组成
在图像分割任务中,GPT-4o 展现出了对图像内容的一定理解和分割能力。图47 至图49 分别展示了 GPT-4o 在参考分割、语义分割和全景分割任务中的表现,与专业分割模型相比,其生成的分割结果在整体质量和细节准确性方面还有待提高,但在多模态生成模型中已属较为优秀。

Figure 47: 任务:图像到 X:指称表达分割。评估定位和分组能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Sa2VA 的输出。观察结果:这些示例表明,当前的 GPT-4o 在像素级定位能力方面较弱

Figure 48: 任务:图像到 X:语义分割。评估形状和分组能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Deeplab-V3 + 的输出。观察结果:与 Gemini-2.0 相比,GPT-4o 的掩码质量较好。然而,在标准语义分割格式方面仍有较大差距

Figure 49: 任务:图像到 X:全景分割。评估形状和分组能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 K-Net 的输出。观察结果:GPT-4o 能够理解全景分割任务,而 Gemini 2.0 Flash 在第一和第三种情况下无法完成该任务
在参考分割任务中,它能够根据文本提示对图像中的特定区域进行分割。例如,当给定一张包含草地和天空的风景照片,并要求分割出草地部分时,GPT-4o 可以大致勾勒出草地的区域,将其从背景中分离出来。然而,与专门的分割模型相比,其分割的精度和边界清晰度还有待提高,生成的分割结果可能存在一定的模糊和不准确区域。
在语义分割任务中,GPT-4o 能够对图像中的不同语义区域进行分类并生成相应的分割掩码。比如,在一张城市街道的图像中,它可以区分出道路、建筑物、行人、车辆等不同语义区域,并为其生成不同颜色的掩码。但是,与 Deeplab-V3+ 这样专业的语义分割模型相比,GPT-4o 生成的分割掩码在细节和形状准确性方面还存在差距,可能会出现将不同类别物体的边界混淆或者分割区域不完整的情况。
在全景分割任务中,GPT-4o 能够同时处理图像中的前景实例分割和背景语义分割,生成带有实例 ID 的分割掩码。例如,在一张体育比赛的图像中,它可以识别出不同的运动员(作为前景实例)和场地背景(作为语义区域),并分别为它们生成独特的掩码和 ID。然而,在空间定位和实例区分方面,GPT-4o 的表现还不够理想,可能会出现将不同运动员的部分区域错误地分割到同一掩码中的情况,或者对背景区域的语义理解不够准确。与 K-Net 这类专业的全景分割模型相比,GPT-4o 生成的全景分割结果在整体质量和细节准确性方面还有较大的提升空间。
边缘检测与图像抠图:勾勒轮廓,分离主体与背景
在边缘检测任务中,GPT-4o 能够识别出图像中物体的边缘,生成相应的边缘图。图50 展示了 GPT-4o 在这一任务中的表现,与专门的边缘检测模型 EMDB 相比,其生成的边缘图在细节和连续性方面还有所欠缺,可能会出现边缘断裂、虚化或者过度检测的情况。

Figure 50: 任务:图像到 X:边缘检测。评估形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 EDMB 的输出。观察结果:发现 GPT-4o 和 Gemini 2.0 Flash 均能检测前景和背景物体的边缘
在图像抠图任务中,图51 展示了 GPT-4o 的表现,它能够生成前景物体的 alpha 透明蒙版,实现前景与背景的分离。与专业的图像抠图模型(如 Matting Anything)相比,其生成的蒙版在边缘细节和透明度准确性方面还有所不足,可能会出现蒙版边缘模糊、透明度不准确或者前景物体细节丢失的问题。这表明在涉及精细抠图的图像处理任务中,专业的图像抠图模型依然具有不可替代的优势。

Figure 51: 任务:图像到 X:图像抠图。评估分组和形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Matting Anything 的输出。观察结果:与 Gemini 相比,GPT-4o 能够处理简单案例,如第三行所示。然而,鉴于图像抠图对细节(精细且对齐)的严格要求,整体质量不佳
显著目标检测、镜面检测、阴影检测等:捕捉图像的隐藏细节
在显著目标检测任务中,GPT-4o 能够根据文本提示检测出图像中最显著的物体。图52 展示了 GPT-4o 在这一任务中的表现,与专门的显著目标检测模型(如 BiRefNet)相比,其检测精度和边界准确性还有所不足,可能会出现将非显著物体误判为显著物体或者检测结果过于粗略的情况。

Figure 52: 任务:图像到 X:显著目标检测。评估分组和形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 BiRefNet 的输出。观察结果:在所有示例中,与 Gemini 相比,GPT-4o 能够根据文本提示检测相关显著目标,而 Gemini 无法实现此功能
在镜面检测任务中,图53 展示了 GPT-4o 的表现,它对简单场景中的镜面反射有一定的检测能力。然而,在复杂场景中,它的表现不如专业的镜面检测模型(如 VMD)理想,可能会出现误检或者漏检的情况。

Figure 53: 任务:图像到 X:镜子检测。评估分组和形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 VMD 的输出。观察结果:对于简单案例,发现 GPT-4o 能够进行镜子检测,如第一个示例所示。对于复杂场景,其表现不如专家模型 VMD
在阴影检测任务中,图54 展示了 GPT-4o 的能力,它能够检测出图像中的阴影区域。然而,在复杂场景中,它可能会将物体及其阴影同时检测为一个整体区域,导致检测结果不准确。

Figure 54: 任务:图像到 X:阴影检测。评估分组和形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 SDDNet 的输出。观察结果:对于更复杂的示例,两种模型均使用一个掩码输出检测物体及其阴影,如最后两行所示,导致误报预测
图55 展示了 GPT-4o 在伪装目标检测任务中的表现,尽管能够处理简单场景,但在复杂场景中仍存在对齐问题。

Figure 55: 任务:图像到 X:伪装目标检测。评估分组和形状分析能力。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 BiRefNet 的输出。观察结果:对于简单案例,GPT-4o 和 Gemini 2.0 Flash 均能检测和分割伪装动物。然而,同样的错位问题依然存在
深度估计与表面法线估计:探寻图像的立体信息
在深度估计任务中,GPT-4o 能够生成图像的深度图,对场景中不同物体的距离关系进行大致的预测。图56 展示了 GPT-4o 在这一任务中的表现,与专业的深度估计模型(如 Depth-Anything)相比,其生成的深度图在细节和精度方面还有较大的提升空间,尤其是在处理复杂场景中的深度层次和物体边界时,可能会出现深度预测不准确或者模糊的情况。

Figure 56: 任务:图像到 X:深度估计。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Depth-Anything 的输出。观察结果:将 Depth-Anything 生成的深度图转换为与 GPT-4o 类似的可视化图。此评估表明,GPT-4o 具备区分图像中不同部分深度关系的能力,但其对背景的理解不足
在表面法线估计任务中,图57 展示了 GPT-4o 的能力,它能够生成图像的表面法线图,对物体表面的方向进行预测。然而,其生成的表面法线图在细节和准确性方面还有所欠缺,可能会出现法线方向偏差或者某些区域法线估计不合理的现象。
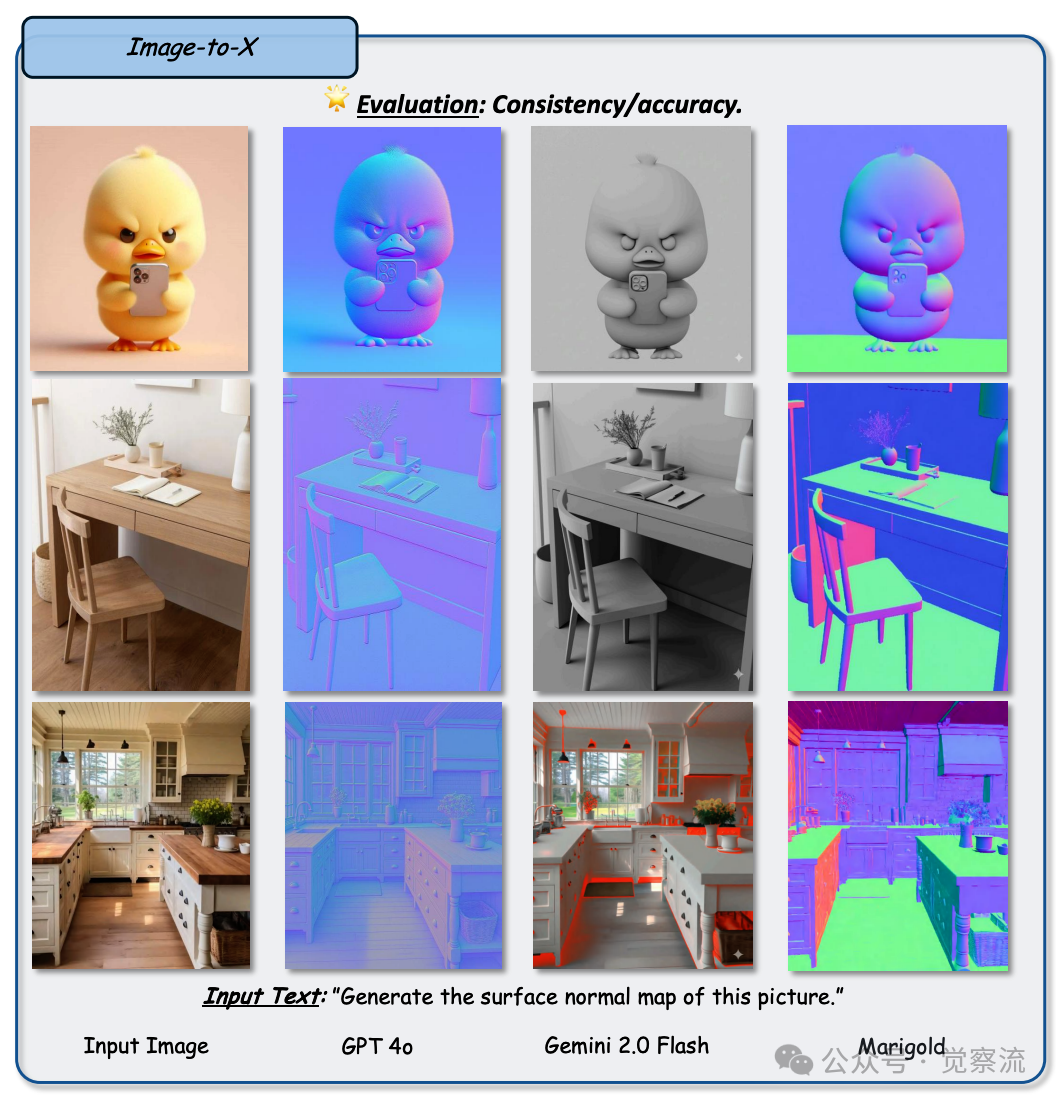
Figure 57: 任务:图像到 X:法线估计。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 Marigold 的输出。观察结果:此评估表明,GPT-4o 具备生成表面法线可视化图的能力,但对细节的理解仍显不足
布局检测与文本检测:解读文档与文本的几何密码
在布局检测任务中,图58 展示了 GPT-4o 的表现,它尝试对文档图像中的结构组件进行识别,如标题、段落、表格、图片等。然而,与专业的布局检测模型(如 LayoutLMV3)相比,其生成的布局检测结果常常会生成出不存在的布局元素,导致输出结果与原始文档的布局结构不符,这使得其生成的布局检测结果在实际应用中难以直接使用。

Figure 58: 任务:图像到 X:布局检测。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 LayoutLMV3 的输出。观察结果:结果显示,GPT-4o 和 Gemini 生成的文档虽然不同,但检测到的布局正确
在文本检测任务中,图59 展示了 GPT-4o 的表现,它能够检测出图像中的文本区域,并生成相应的绿色框标注。然而,与专业的文本检测模型(如 CRAFT)相比,其在文本检测的准确性和鲁棒性方面还有较大的差距,专业模型能够更精准地识别出各种复杂条件下的文本区域,满足高精度文本检测的需求。

Figure 59: 任务:图像到 X:文本检测。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 CRAFT 的输出。观察结果:结果显示,GPT-4o 经常生成不存在的文本
目标跟踪:锁定目标,捕捉动态视觉轨迹
在目标跟踪任务中,GPT-4o 展现出一定的目标定位和跟踪能力。图60 至图63 分别展示了 GPT-4o 在不同场景下的目标跟踪表现,与专业的目标跟踪模型(如 SAM-2)相比,其在跟踪过程中存在问题,如无法保持对目标的一致性跟踪,容易出现目标漂移或者丢失的情况。此外,在密集场景下,如人群聚集、交通拥堵等情况,它的跟踪能力会受到明显的影响,可能会出现目标混淆或者错误关联的现象。

Figure 60: 任务:图像到 X:目标跟踪、匹配和视频分析(1/4)。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 SAM-2 的输出。观察结果:此评估表明,GPT-4o 具备跟踪目标的能力,但与输入图像相比,无法生成一致的图像

Figure 61: 任务:图像到 X:目标跟踪、匹配和视频分析(2/4)。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 SAM-2 的输出。观察结果:此评估表明,GPT-4o 具备跟踪目标的能力,但与输入图像相比,无法生成一致的图像

Figure 62: 任务:图像到 X:目标跟踪、匹配和视频分析(3/4)。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 SAM-2 的输出。观察结果:此评估表明,GPT-4o 具备跟踪目标的能力,但与输入图像相比,无法生成一致的图像

Figure 63: 任务:图像到 X:目标跟踪、匹配和视频分析(4/4)。设置:每行展示输入图像和文本提示,以及来自 GPT-4o、Gemini 2.0 Flash 和 SAM-2 的输出。观察结果:此评估表明,GPT-4o 具备跟踪目标的能力,但与输入图像相比,无法生成一致的图像
局限性分析:剖析 GPT-4o 的短板与瓶颈
不一致性生成现象:精准把控的挑战
尽管 GPT-4o 在图像生成方面展现了诸多优势,但它也存在一些局限性。其中,不一致性生成现象是一个较为突出的问题。图50 至图53 展示了 GPT-4o 在不同任务中出现的不一致性生成案例,这些问题在需要精确图像编辑或组合准确性要求较高的任务中尤为明显。
在生成图像时,GPT-4o 有时会偏离输入图像的精确语义提示,导致生成的图像在物体数量、空间布局、特定形状或指定颜色等方面出现不一致的情况。这种问题在处理复杂文本提示或者进行精细图像编辑任务时较为常见,例如在要求对一张照片进行局部修改,如更改人物的服装颜色或者添加一个特定数量的装饰物时,GPT-4o 可能会错误地改变其他部分的颜色或者添加错误数量的装饰物。这就好比是一位画家在作画时,虽然有着明确的创作意图,但在实际操作过程中,手却不听使唤,导致画面细节与构思不符。这种不一致性可能与 GPT-4o 采用的独特生成范式有关,它在追求生成图像的多样性和丰富性的同时,可能在一定程度上牺牲了对输入语义细节的精准把控。相比之下,一些扩散模型或基于掩码生成的架构(如 MaskGIT)在一致性生成方面表现得更为出色,它们能够更严格地遵循输入语义提示,生成与之高度一致的图像。
幻觉问题:虚假内容生成的困扰
GPT-4o 还容易出现幻觉问题,即生成不符合逻辑、语义不一致或者与事实不符的内容。图54 至图57 展示了 GPT-4o 在不同任务中出现的幻觉现象案例,这些问题在处理复杂或未明确指定的文本提示时尤为常见。
这种幻觉现象主要表现在它可能会凭空虚构不存在的物体或地理特征,如在生成的图像中出现虚构的岛屿、建筑或者地标等。此外,它还可能错误地表示实体之间的关系,例如在一张描述人物与宠物互动的图像中,将人物与宠物的动作和情感关系处理得不合常理。当提示信息不完整或者含糊不清时,GPT-4o 可能更多地依赖于自身的内部先验知识来进行图像生成,而不是基于准确的世界知识,这就像是在黑暗中摸索前行,当缺乏足够的信息指引时,容易凭借以往的经验和想象来填补空白,但这些填补的内容未必符合现实情况。幻觉问题对于那些需要精确性的重要应用场景(如教育、医学插图、科学可视化等)构成了显著的障碍,可能会导致误导性的信息传播和错误的决策依据。
数据偏差问题:文化与语言多样性的局限
数据偏差问题是 GPT-4o 另一个需要解决的局限性。图58 至图61 展示了 GPT-4o 在生成包含特定文化元素和非拉丁文本文本时出现的数据偏差问题案例,这些问题不仅影响了模型的性能,也带来了伦理方面的挑战。
尽管它在文本和视觉模态之间的对齐方面表现出色,但在生成一些具有文化代表性元素(如传统服饰、建筑、艺术风格等)的图像时,GPT-4o 经常会生成出西式风格的内容,而不是所要求的文化特定元素。例如,当要求生成一个中国将军佩戴的传统皇冠时,它可能会生成一个具有西方风格的皇冠形象。

Figure 4: 任务:组分式文本生成图像。评估图像 - 文本对齐在复杂构图上的表现。设置:每行展示一个文本提示以及来自 GPT-4o、Gemini 2.0 Flash 和 FLUX.1-Pro 的生成输出。观察结果:GPT-4o 在生成与文化相关的元素以及保持边界连贯性方面存在困难(见第 2 和第 3 行),与 Gemini 2.0 Flash 和 FLUX 的表现类似
图4 进一步展示了 GPT-4o 在生成文化相关元素时的局限性,尤其是在边界连续性方面,与 Gemini 2.0 Flash 和 FLUX.1-Pro 相比,GPT-4o 仍需改进。
对于非拉丁文本文本的渲染,GPT-4o 也存在较大的问题,生成的字符往往不完整、变形严重,或者被替换为类似拉丁文的近似符号。这主要是由于在模型的训练过程中,对于多样化文本文本尤其是非拉丁文本文本的曝光有限,以及在像素空间中准确呈现复杂排版和精细字形的难度较大所导致的。这一现象反映了 AI 系统中的一个更广泛的挑战 —— 数据偏差。用于开发像 GPT-4o 这样的模型的训练数据可能过度代表了某些语言、文化和书写系统,从而导致了在不同语言群体之间的性能差异。这种偏差不仅是一个技术上的局限性,也是一个伦理问题,因为它可能导致在 AI 应用中对未充分代表的语言和文化的排斥。
总结
GPT-4o 的架构设计和工作原理体现了自回归模型和扩散模型的有机结合,以及对多模态融合技术的深入探索。这种创新的设计使得 GPT-4o 在图像生成领域展现出了卓越的能力,为多模态生成模型的发展提供了新的方向和思路。
GPT-4o 在图像生成领域的整体表现
GPT-4o 作为一款多模态生成模型,在图像生成领域展现出了卓越的能力。它不仅在文本到图像、图像到图像、图像到 3D、图像到 X 等多种任务中取得了令人瞩目的成绩,而且在对齐视觉与语言方面表现出色,为统一视觉 - 语言生成模型的发展树立了新的标杆。其强大的文本渲染能力、空间推理能力、图像变形能力等优势,使其在多个应用场景中具有广泛的潜力和价值。从创意设计、艺术创作到虚拟现实构建、图像修复等领域,GPT-4o 都能够为创作者提供强大的工具和灵感来源,极大地拓展了人类视觉表达和创作的边界。
然而,GPT-4o 并非完美,它面临着不一致性生成、幻觉现象以及数据偏差等挑战。这些问题不仅制约了它在某些高精度、高可靠性和文化多样性的应用场景中的进一步发展,也提醒我们必须关注模型的局限性和潜在风险。
对未来统一视觉 - 语言生成模型发展的启示
GPT-4o 为我们未来统一视觉 - 语言生成模型的发展提供了宝贵的启示。它强调了模型架构的重要性,但同时也提醒我们,架构并非万能,训练数据、模型规模和优化策略同样是决定模型成败的关键因素。
GPT-4o 的成功让我们看到了多模态融合的巨大潜力,但如何更好地平衡不同模态之间的信息交流和融合深度,避免出现模态间的偏差和不一致性,将是未来研究的重点方向之一。此外,针对幻觉问题和数据偏差问题的研究和解决方案的探索也至关重要,这需要开发更有效的数据筛选和增强方法,以及更精准的模型约束和引导机制,以确保生成内容的真实性和公平性。
最后,GPT-4o 的实践表明,随着模型规模和训练数据的不断扩大,模型的能力也在不断提高。这预示着未来通过进一步的规模扩展和优化,我们或许能够打造出更加智能、更加通用的视觉 - 语言生成模型,使其在更广泛的领域和更复杂的任务中发挥作用。


