这几天,NeurIPS 2025的评审结果,陆续出炉了!
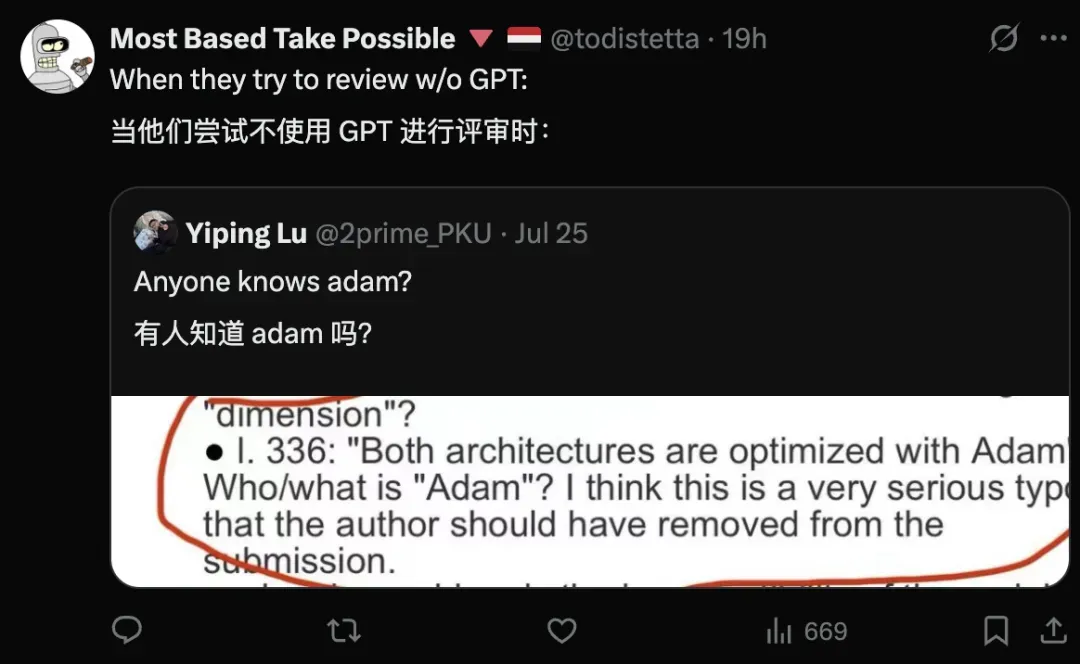
让人措不及防的是,「Who's Adam」明晃晃地出现在了一位作者的审稿建议中,成为近来学术圈最大的笑柄。
究竟是大模型不懂,还是审稿人疏忽了?
这么低级的错误,让AI圈内人直呼:离了大谱!
网友辣评:审稿人会使用LLM,你就偷着乐吧;如果不使用GPT审稿,他们可能连领域内的基本常识都不了解!
「Who's Adam」依旧在发酵的同时,NeurIPS还有更离谱的事发生了。
得克萨斯农工大学计算机系任助理教授涂正中(Zhengzhong Tu)称,自己的审稿建议中,提示词没有删干净。
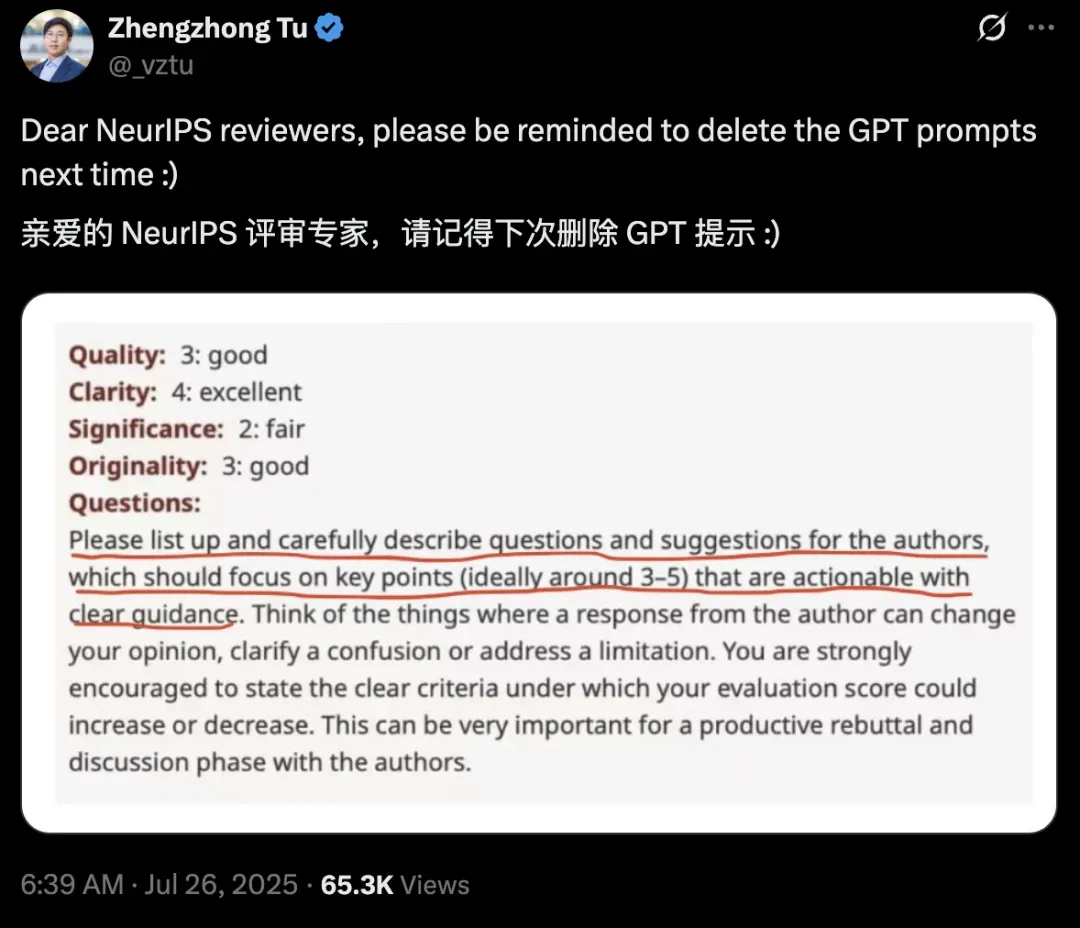
不过,研究科学家Damien Teney表示可能只是复制错地方了。
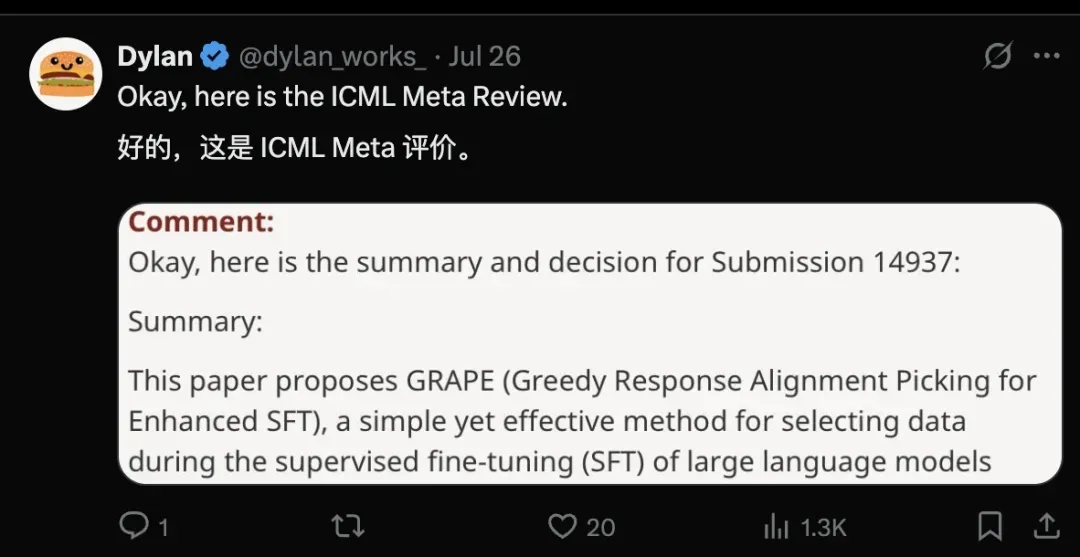
研究LLM迁移学习的博士生Dylan也发现自己提交的论文,可能没有被认真对待。
审稿人只是让AI总结了内容,并做了接收与否的决定。
或许,是时候该反思学术界的游戏规则了。
NeurIPS评审爆猛料,全网吵翻了
这届NeurIPS评审,全网吐槽满天飞。
近年来,论文评审的质量一直在下降。原因主要有两种:
其一是,论文数量的增加,大模型加速迭代,协助研究者、初创公司撰写论文,产出效率大增。
其次,优秀的研究人员更专注于模型开发和创业,而非论文评审。
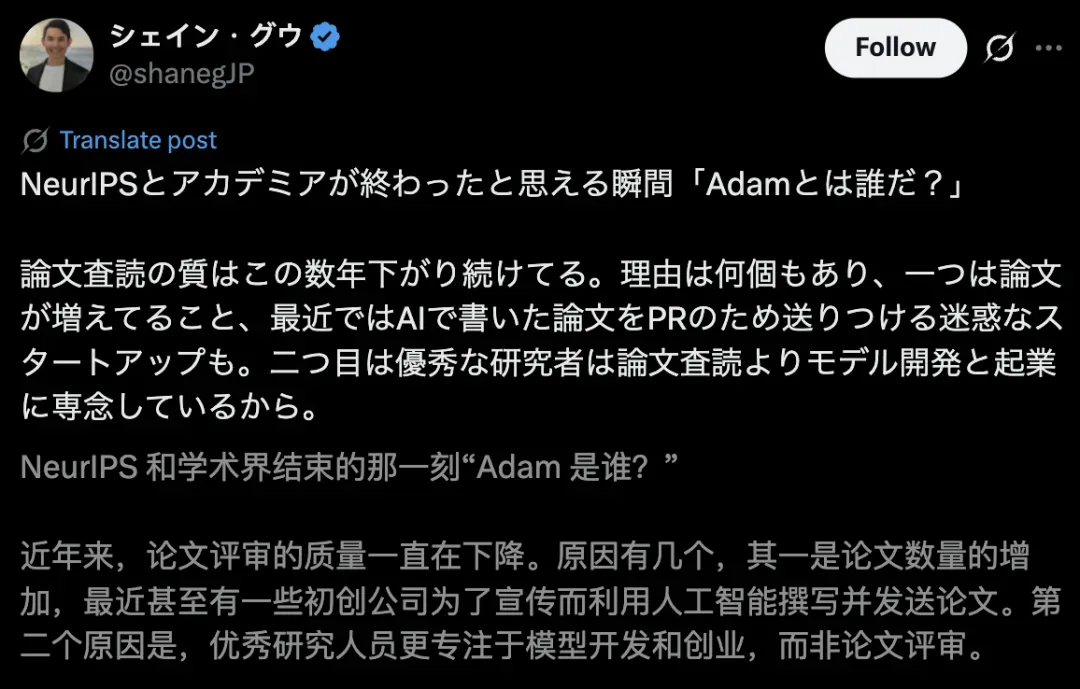
正因如此,才闹出了「Adam是谁」的大笑话。
在AI领域,Adam是深度学习中最常见的优化方法之一,论文被引次数高达220991。

对此,著名机器学习研究员Dan Roy张口大骂,「NeurIPS评审现如今就是垃圾」!

从事AI系统工作的Hanchen Li开玩笑:是不是英文名改成Adam,明年就能被NeurIPS引用了?
审稿人告急,还有DDL
另一方面,能够出现如此荒谬的评审,还与NeurIPS的规定相关——
参与审稿的AI研究员必须在截止日期前完成,否则他们自己的论文直接被NeurIPS拒掉。
有的人就是赶在DDL前,匆忙审稿。

由于审稿人手不够,今年,NeurIPS组委会亲自招募更多的审稿人。

纽约大学助理教授Ravid Shwartz Ziv嘲讽道,「NeurIPS真正的创新之处:领域主席们(AC)在不知不觉中运营着史上最大规模的LLM基准评测」。

另一位网友吐槽道,这是NeurIPS评审的新低点。

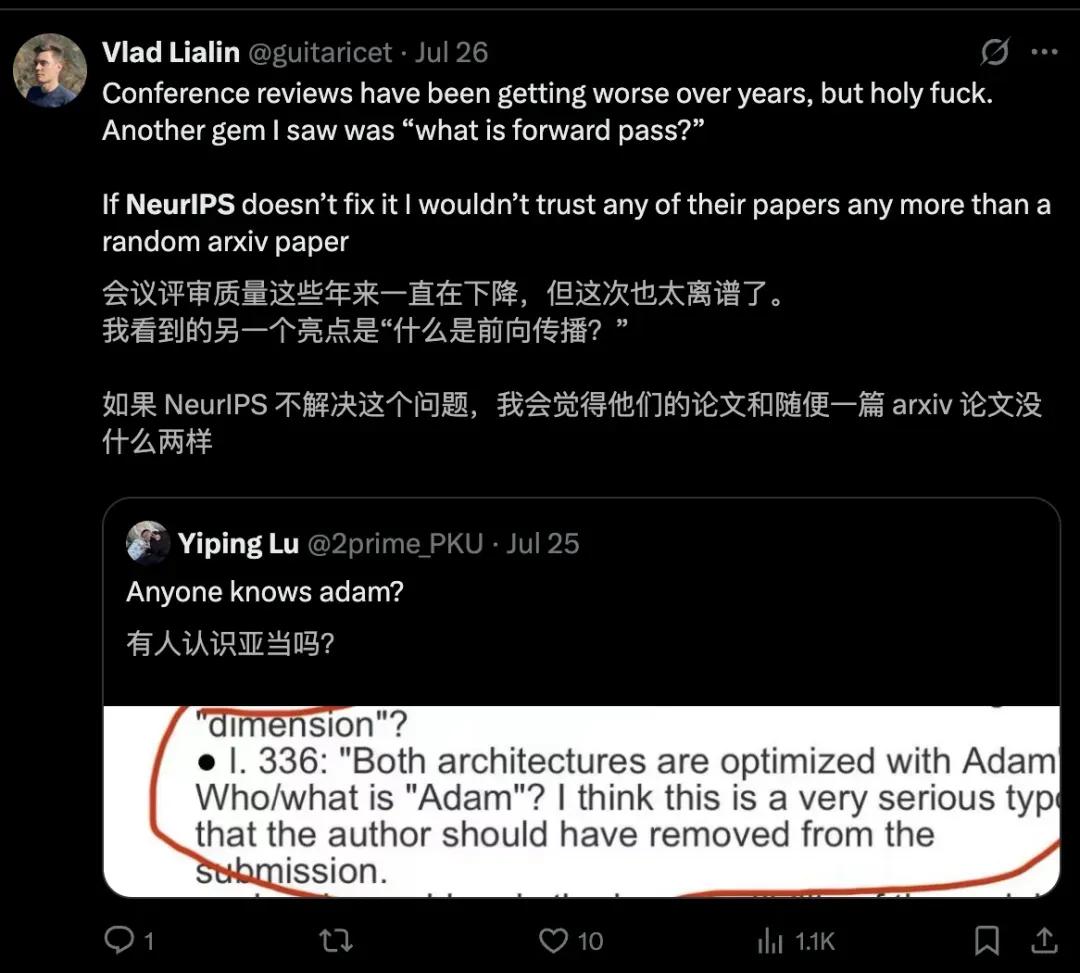
会议审稿质量在下降,这大家都知道,但这次NeurIPS评审太离谱了。
Vlad Lialin看到一条神评论:「什么是前向传播」。他认为如果不解决审稿问题,那NeurIPS论文将毫无可行度,跟无人评审的论文没什么两样。
高级机器学习工程师、Keras 3合作者Aakash Kumar Nain表示如果不对认真处理类似问题,他以后不会对学术会议的质量抱有任何希望。
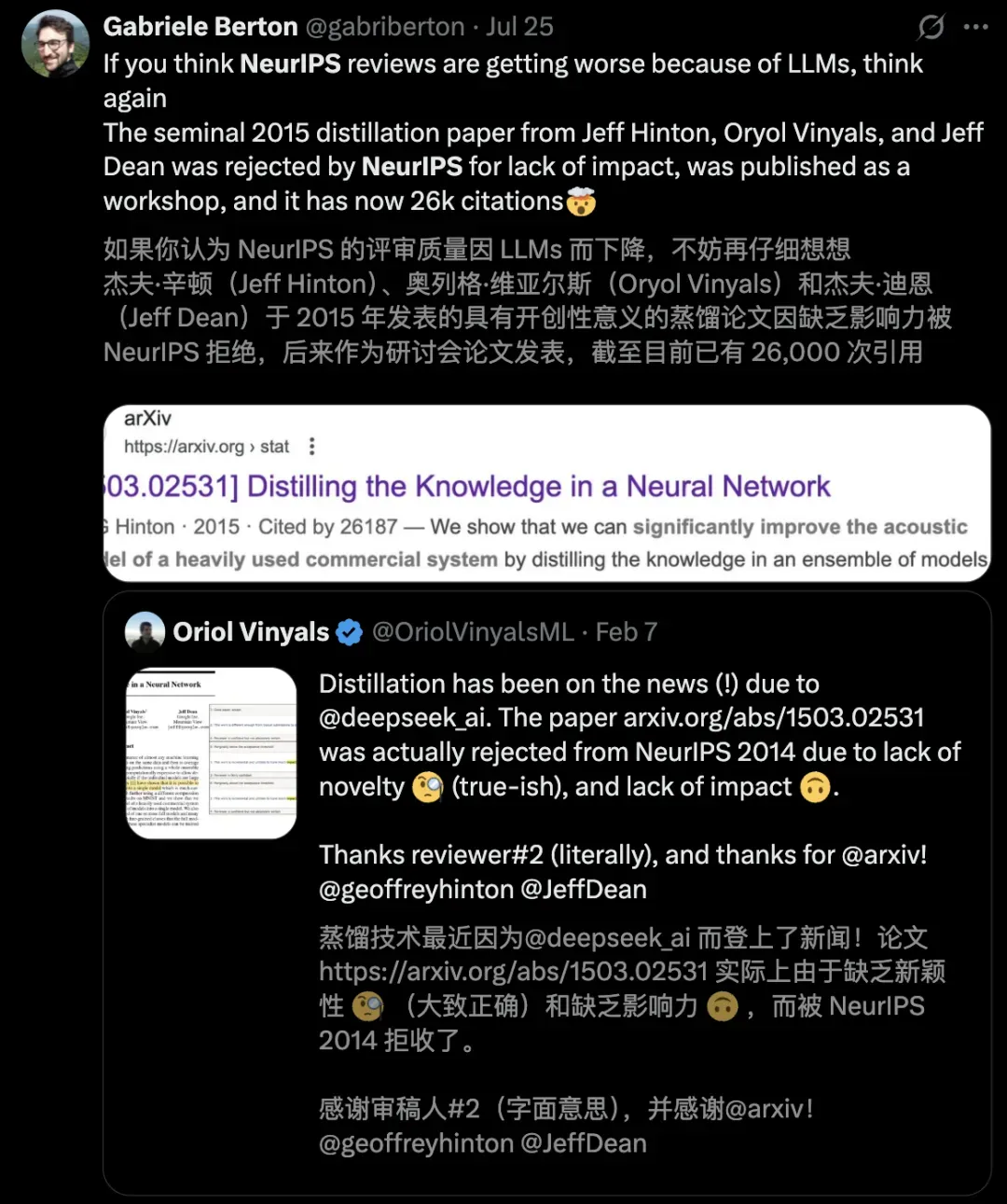
一位亚马逊工程师挖出了,2015年Hinton和谷歌团队一篇关于「蒸馏」技术被NeurIPS拒收的论文。

而如今,「蒸馏」成为当前最火的训练策略。Distilling the Knowledge in a Neural Network这篇被引数超26000次。
从事多模态研究的Weijian Luo,在NeurIPS 2023上发表了学术生涯中的前4篇论文。
NeurIPS这对他意义重大,但这次的审稿质量之低令他沮丧。
他表示是时候认真解决文章评审问题了。

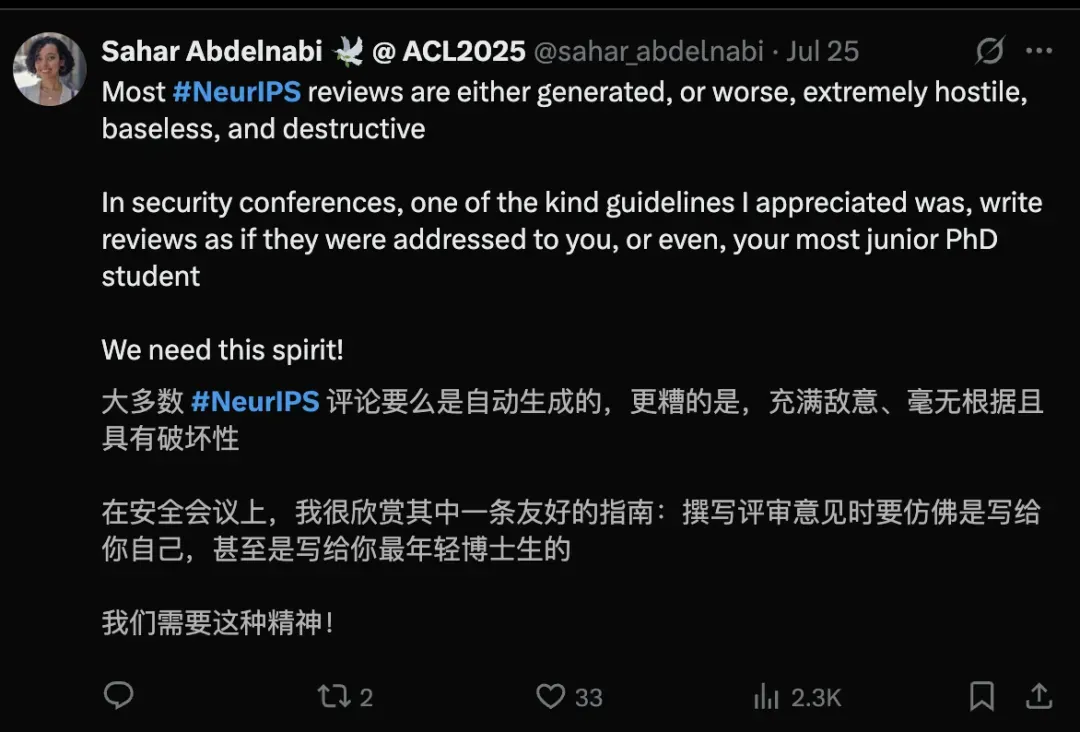
微软研究员Sahar Abdelnabi称NeurIPS的评审意见充满敌意、毫无根据、完全不具建设性,比用LLM生成评审意见还要糟糕。
她建议NeurIPS学习安全会议,加入善意评审指南。
审稿人和作者,双双糊弄?
评审结果不尽人意,你以为只是审稿人的问题吗?
有的研究人员需要一个亮眼的成绩单,利用LLM大量产出论文,何尝不是一大问题呢?
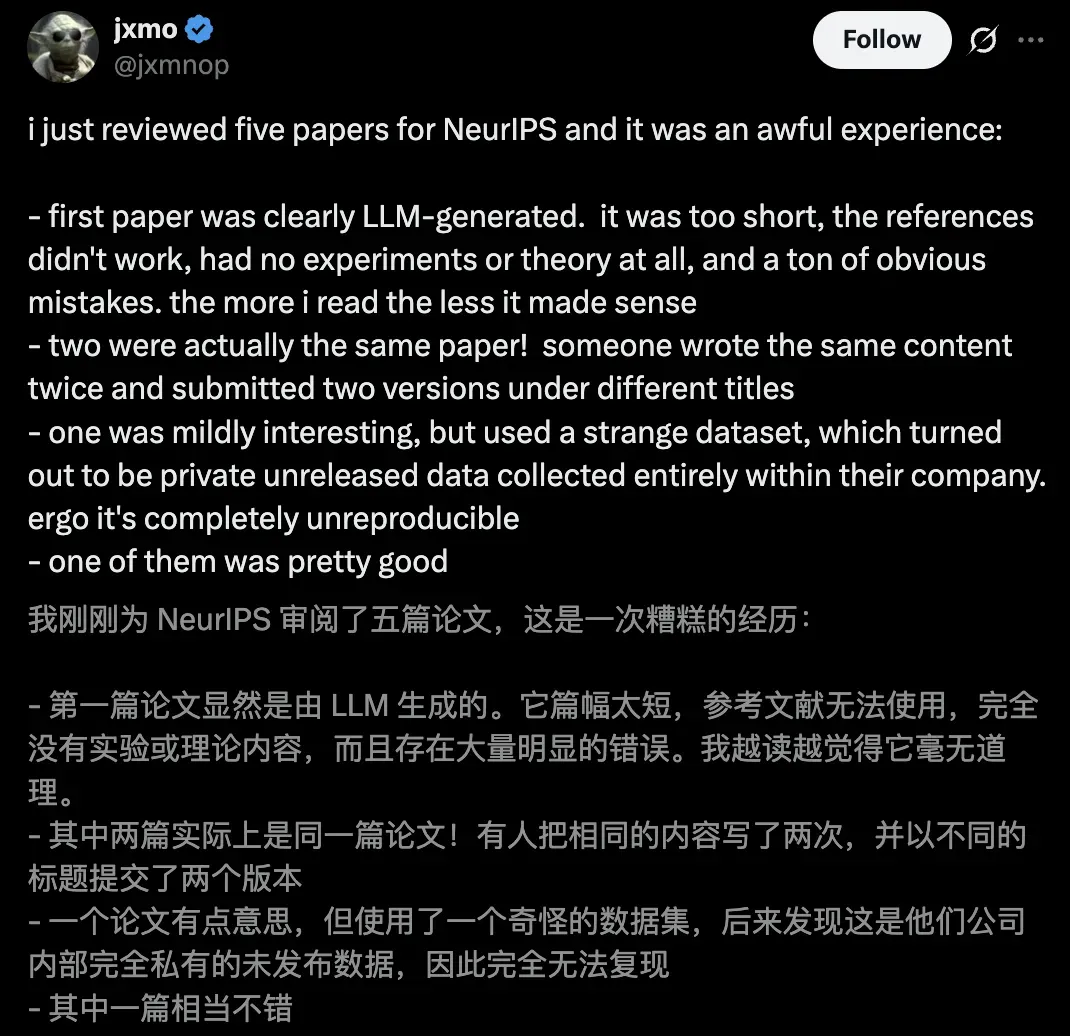
有审稿人爆料称,「自己审了5篇论文,体验简直糟糕透顶」。
- 第一篇明显是LLM生成的。篇幅过短,参考文献失效,既无实验也无理论支撑,还充斥大量低级错误。越读越觉得不知所云
- 有两篇根本是同一篇论文!有人把相同内容改了两个标题重复投稿
- 其中一篇略有新意,但使用了奇怪的数据集——后来发现完全是他们公司内部未公开的私有数据,完全无法复现结果
- 只有最后一篇还算像样
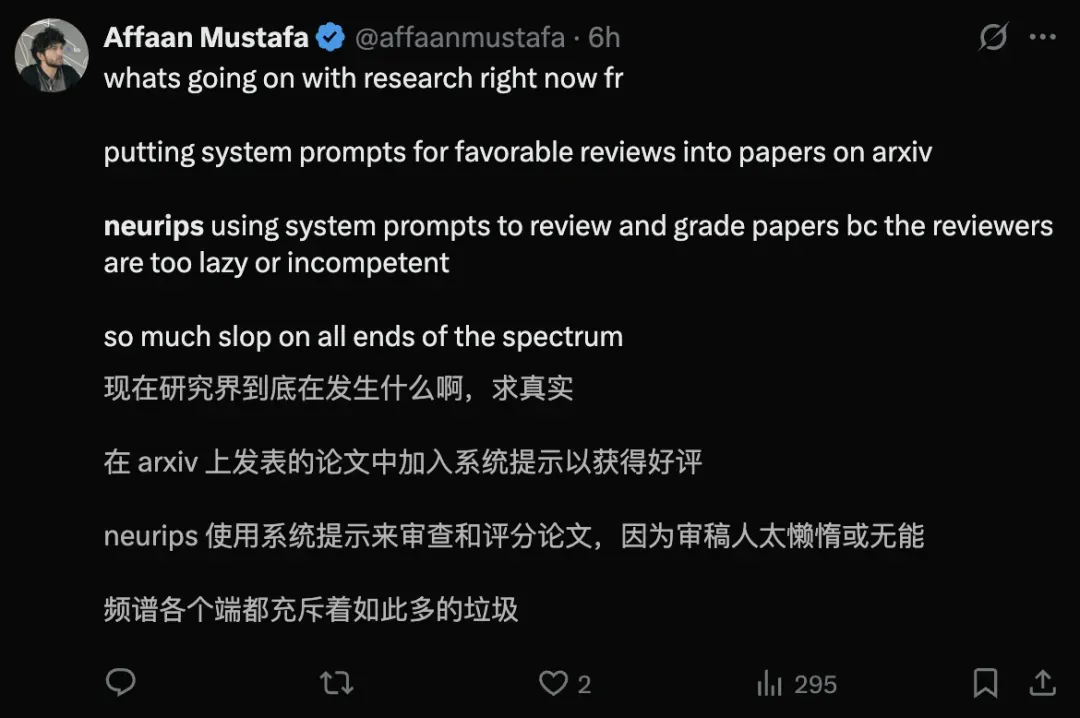
研究过AI+经济的Affaan Mustafa,对学界发生到底发生了什么,非常疑惑。
一方面,为了获得好评,投稿论文注入了系统提示词;另一方面,NeurIPS使用系统提示词来审稿并为论文打分。
这两端都充满了AI生成的垃圾内容。
Rebuttal最佳指南
不论是什么结果,评审意见出了之后,下一步就是Rebuttal阶段了。
那么,作者们如何做,能够为自己赢回更多的胜率呢?

此前,AI初创CEO Devi Parikh写过一篇指南,提供了18种技巧,涉及的案例非常丰富,属于必收藏的系列。
接下来,一起看看都有哪些能实际帮助到的Rebuttal策略吧。
1. 逐条列出审稿人意见
用一个顺手的电子表格来整理每位审稿人提出的具体评论、问题或疑虑。
将所有内容并列一处,有助于我们识别共同关注点,并避免意外遗漏。请尽快完成这一步,以便及早确定是否需要进行新的实验(如果会议允许)或分析。
2. 集思广益,罗列可能的回应
在表格中为每位作者预留一列,用于回应各审稿人的意见。在此处用草稿形式写下所有想法,无需顾及文采或篇幅。说服力和简洁性是通过做减法来实现的。
3. 撰写Rebuttal草稿
将表格中达成的共识,转化为Rebuttal草稿中的具体回应。写作时力求简洁,但暂时不必担心篇幅限制。要覆盖到每一个要点,删减和调整优先级可以留到后面处理。
4. 审查和修改
重读最初的审稿意见和你们整理的表格,确保所有问题都得到了回应。优先处理主要的疑虑,并着手删改以满足篇幅要求。
鉴于此,我们必须清楚,是为谁而写,目标又是什么。
审稿人和领域主席(AC),是最主要的目标。
- 对于审稿人:澄清疑虑、回答问题、纠正误解、Rebuttal不准确的评价,并真诚地努力采纳反馈、改进你的工作。
- 对于AC:说服他们你已做出真诚的努力;呈现一份有代表性的审稿意见摘要;帮助他们判断审稿人的疑虑是否已得到解决;指出不公正的审稿行为;并最终,帮助他们做出决定。
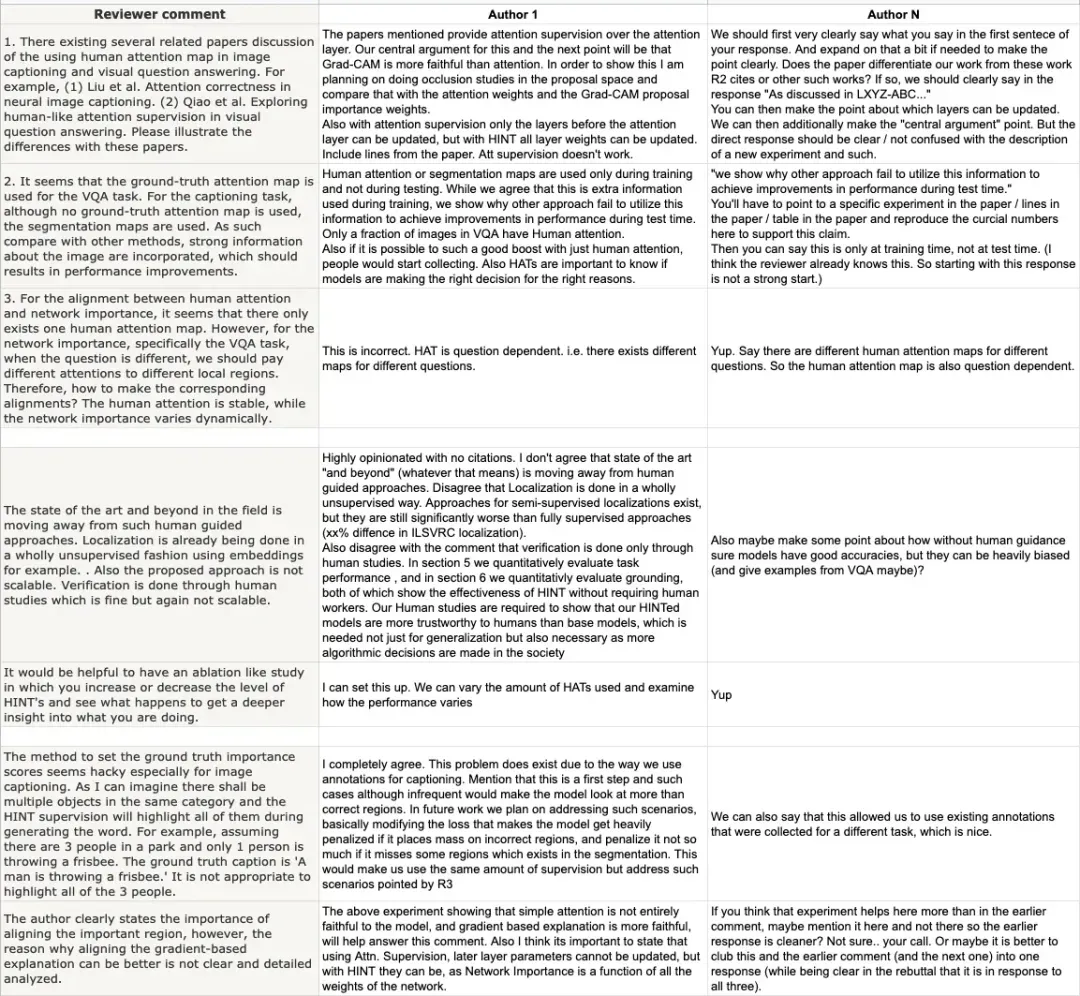
根据作者的经验,研究界的大多数新成员只关注(1),而忽略了(2),下面是一个实操案例:
一定要开门见山。
首先对评审意见进行总结性概述,重点突出审稿人对个人工作的积极评价。
虽然Rebuttal主要针对需要回应的负面意见,但切勿让评审委员会在审阅过程中忽略研究的优势。



