由上海人工智能实验室发布的“万卷·丝路2.0”多语言多模态语料库正式开源。该语料库在原有的阿拉伯语、俄语、韩语、越南语、泰语等5个语种基础上,新增了塞尔维亚语、匈牙利语、捷克语3个稀缺语料数据,涵盖文本、图片、音频、视频四大模态,数据总量超过1150万条,音视频时长超过2.6万小时,成为小语种多模态领域的重要资源。
“万卷·丝路2.0”具有多语言、大规模、多模态、高质量的特点。它不仅扩充了语种数量,还全面升级了数据模态和总量,新增了图片 - 文本、音频 - 文本、视频 - 文本、特色指令微调(SFT)四大模态数据,覆盖多模态研究全链路。数据经过成熟生产管线及安全加固,结合过滤算法与当地专家人工精细化标注质检,成为覆盖多模态、多领域的高质量数据集,适配文化旅游、商业贸易、科技教育等不同场景。
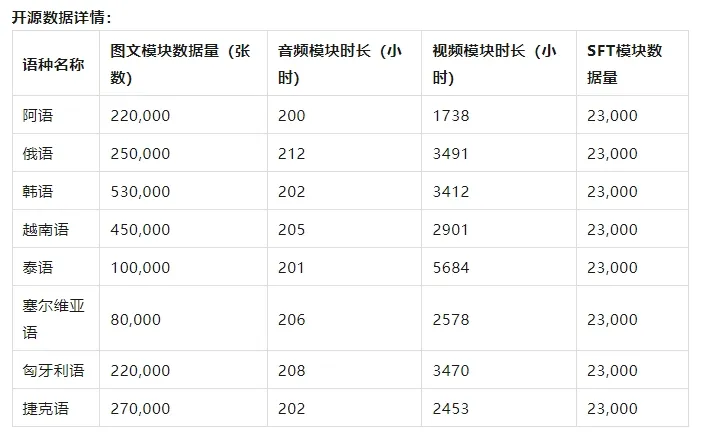
此次开源的内容包括:图片 - 文本累计开源超过200万条;音频 - 文本开源超过1600小时;视频 - 文本开源超过2.5万小时;SFT 数据开源18万条。开源数据覆盖了多种语种,为开发者提供了丰富的多模态数据资源。
“万卷·丝路2.0”展现出显著的模型赋能效应。基于7B 参数基础模型训练时,模型综合性能跃升52.3%;在700亿参数的大模型训练中,仍保持12.8% 的性能增益。该数据集使轻量化模型在多语言处理领域展现出超越大模型的卓越表现,为多语言模型的微调提供了有力支持。
数据集地址:
https://www.modelscope.cn/collections/wanjuansilu-20-a3d1a96dad6042
一键微调框架:
https://github.com/modelscope/ms-swift


