
大家好,我是肆〇柒。今天这篇研究,是由Gradient(联合浙江大学、多伦多大学等顶尖学府)团队提出的创新性框架——SEDM。如果你正在为多智能体系统的“记忆过载”和“性能下滑”而头疼,那么这篇将记忆从“被动仓库”升级为“主动大脑”的研究,或许正是你要寻找的答案。
你是否经历过这样的困境?当你的多智能体系统连续运行三个月后,推理准确率从85%悄然滑落到68%,调试发现记忆库中70%的条目都是无用信息,而每次查询的Token消耗却增加了40%。更令人沮丧的是,随着系统运行时间延长,问题愈发严重——记忆越多,表现越差,形成一个难以打破的恶性循环。
这不是假设,而是长期多智能体系统(Multi-Agent System, MAS)开发者面临的现实挑战。当智能体在开放环境中持续交互,系统会积累海量轨迹数据和历史交互记录。这些信息本应是决策的宝贵资产,但现实却往往事与愿违——记忆库的无序膨胀不仅没有提升决策质量,反而导致检索效率下降、噪声干扰加剧,最终引发"信息过载"的恶性循环。这不仅影响模型性能,更直接关系到项目成本与交付时间——在实际业务场景中,这意味着每月可能多花费数万元的API调用费用,以及难以向客户解释的性能下滑。
当前主流的记忆管理方案主要依赖向量检索和分层存储结构,但这些方法在动态开放的MAS环境中面临根本性挑战。向量检索虽能基于语义相似度识别相关条目,却无法保证这些条目在实际任务中真正有用;分层结构则假设信息增长是线性的、稳定的,而现实中的记忆积累往往是噪声与价值混杂的非线性膨胀。这些局限导致三大核心问题:噪声积累严重损害检索质量,记忆规模扩大带来指数级增长的计算成本,以及跨任务场景下知识迁移能力薄弱。
面对这些挑战,SEDM(Scalable Self-Evolving Distributed Memory)提出了一场记忆架构的范式创新——它不再将记忆视为被动的信息仓库,而是构建为一个主动、可验证、自进化的智能组件。通过实证主义准入、证据驱动调度和保守抽象迁移三大设计原则,SEDM从根本上重构了记忆的生命周期管理,为长期多智能体协作提供了可持续的解决方案。更重要的是,SEDM不是简单地优化记忆存储,而是让记忆系统从"负担"变为"资产",使系统越用越聪明,而非越用越慢。
为什么现有方案失败?——揭开记忆管理的三大陷阱
要理解SEDM的创新价值,首先需要看清现有方案为何在长期MAS中失效。下图直观展示了三种记忆策略的本质差异:无记忆、固定记忆和SEDM。无记忆系统就像一个"金鱼脑"智能体,每次交互都从零开始,无法积累任何经验。在复杂任务中,这导致基础性能严重受限——如FEVER事实验证任务中,无记忆基线仅得57分,表明缺乏外部知识和先验记忆时推理能力极为有限。
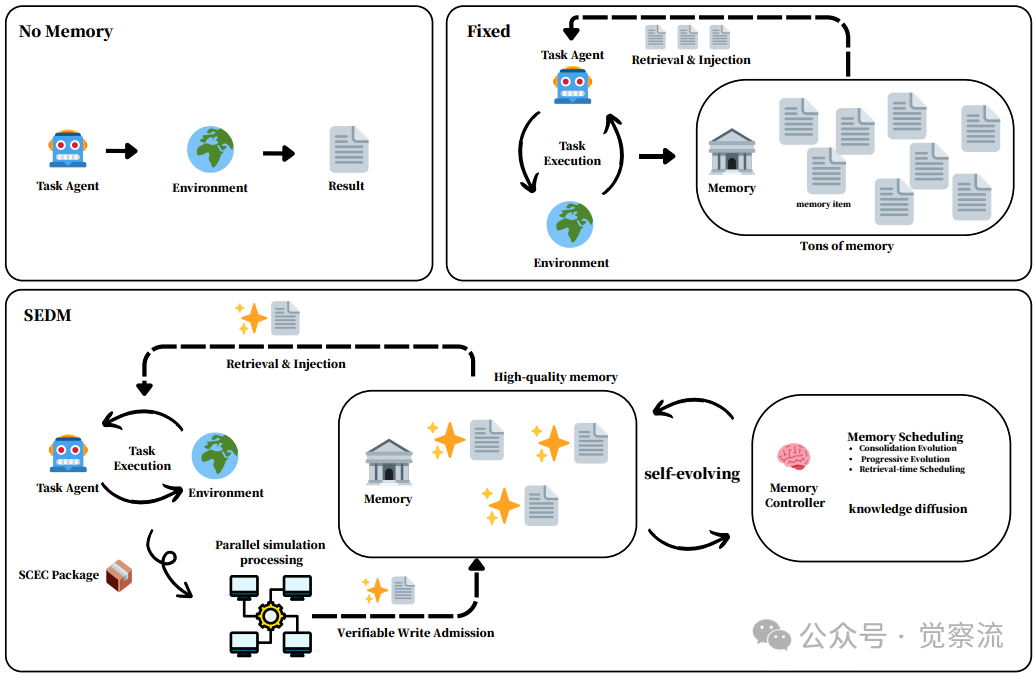
记忆策略对比图
固定记忆系统则像一个"永不丢弃的档案管理员",将所有交互记录无差别地存储起来。这种方法看似全面,却很快陷入"信息过载"陷阱:随着记忆库膨胀,检索质量呈指数级下降,低价值信息稀释高质量信息的贡献,导致下游任务性能明显下滑。在FEVER任务中,G-Memory虽然将分数提高到62分,但这是以大幅增加Prompt Tokens为代价的——从2.46M激增至3.62M,增长47%,直接导致推理成本飙升。
上图还清晰揭示了问题的根源:传统记忆系统缺乏质量控制机制。它们要么完全不存储记忆(无记忆),要么盲目存储所有记忆(固定记忆),却无法区分哪些记忆真正有用。这就像一个图书馆只按时间顺序排列书籍,而不考虑哪些书籍真正有价值、哪些已经过时。当系统运行时间延长,这一缺陷被急剧放大——记忆越多,检索质量越差,形成"越多越差"的恶性循环。
SEDM则采取了截然不同的思路:它将记忆视为一个需要持续验证和优化的动态组件,而非简单的存储仓库。通过三个关键机制——可验证写入准入、自调度记忆控制器和跨域知识扩散,SEDM实现了记忆的"垂直演化",使系统能够从具体经验中提炼出更高层次的洞察,同时保持对低质量信息的严格过滤。
核心突破:SEDM如何让记忆"越用越聪明"
SEDM的创新不是零散的技术点,而是一个完整的记忆生命周期管理框架。下图展示了这一框架的全貌,我们可以跟随一个记忆项的完整旅程,理解SEDM如何实现"记忆即服务"的创新思考。
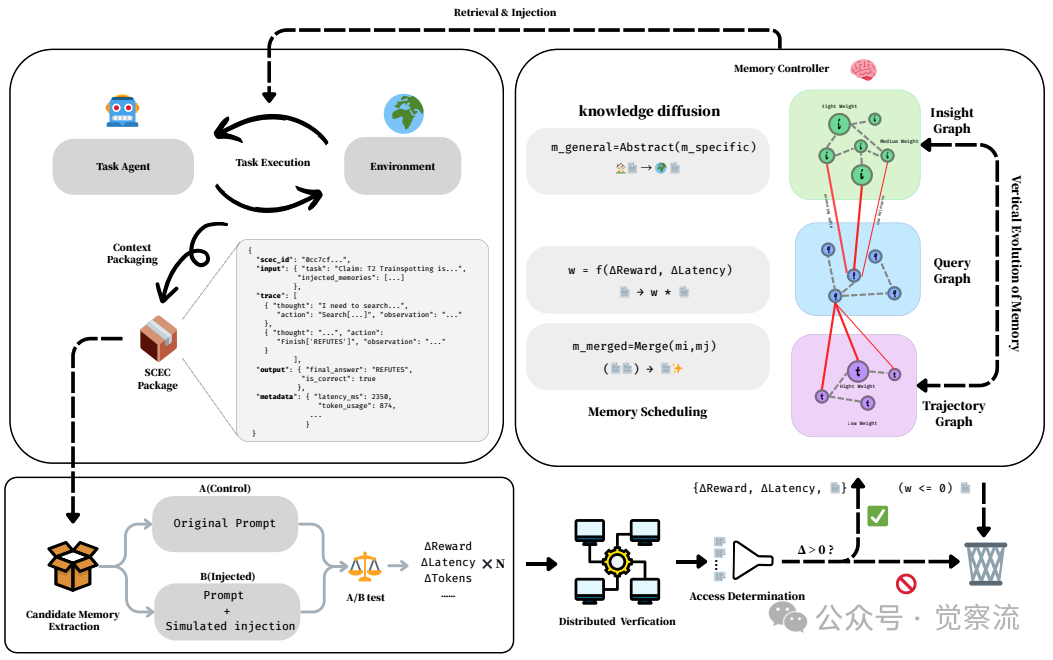
SEDM架构详解图
1. 生成:从任务执行到候选记忆
当智能体完成一个任务后,系统会将其封装为Self-Contained Execution Context(SCEC,自包含执行上下文)。SCEC是什么?简单点讲,它是一个记忆的"质检站"。它包含了任务执行所需的全部要素:输入、输出、工具摘要、随机种子和配置哈希值。关键在于:
- 它能脱离原始环境重放(就像独立的Docker容器)
- 确保结果可重现(不同模型版本也能得到相同结果)
- 只保留必要信息(避免存储冗余数据)
上图左侧展示了SCEC的具体结构示例:
复制这一结构不仅记录了任务执行的完整上下文,还特别标注了"决定性推理或校正步骤"——这些步骤将被提取为候选记忆项。
关键价值:SCEC使记忆验证摆脱了对原始环境的依赖。想象一下,当你的多智能体系统分布在不同服务器上,传统方法需要重建整个环境才能验证记忆价值,而SEDM只需通过SCEC就能在任意计算节点并行验证,效率提升数十倍。
2. 验证:实证主义准入——"只有经过验证的记忆才值得记住"
SEDM区别于传统记忆系统的核心创新,在于将"是否值得记住"这一问题转化为可通过实验验证的客观决策。这是通过SCEC内部的A/B测试实现的。
从每个SCEC中,系统提取一个候选记忆项m,表示为简洁、可独立注入的片段。为了评估其效用,系统在同一个SCEC内进行配对A/B测试:

关键价值:这一机制解决了记忆噪声问题。传统系统无法区分"语义相关"和"实际有用",而SEDM通过A/B测试直接测量记忆的边际效用。在实际应用中,这意味着你的系统不会存储那些"听起来相关但实际无用"的信息,从源头上控制噪声积累。
一个例子:当智能体验证"《猜火车2》是否由丹尼·博伊尔执导"时,一条候选记忆是"丹尼·博伊尔执导了《猜火车》"。通过A/B测试发现,这条记忆能将验证准确率从75%提升到90%,同时减少搜索次数,因此获得正向评分并被接受。而另一条记忆"《猜火车》于1996年上映"虽然语义相关,但对验证导演无直接帮助,评分低于阈值,被拒绝存储。
3. 存储:自调度记忆控制器——记忆的"智能管家"
如果说SCEC机制为记忆写入提供了质量保障,那么自调度记忆控制器则负责记忆的"生命周期管理",确保记忆库始终保持精简高效的状态。这一控制器包含两大核心功能:检索时调度和内存的"新陈代谢"。

关键价值:在实际业务场景中,这意味着你的系统能够稳定地提供高质量记忆,而不受LLM重排序带来的波动影响。特别是在高并发场景下,这一机制可以显著降低延迟并提高服务稳定性。
内存的"新陈代谢"机制则更为巧妙,它通过三个关键过程维持记忆库的健康状态:

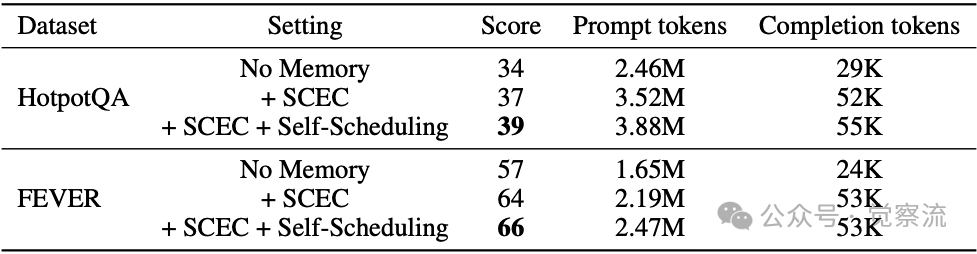
关键价值:在长期运行的系统中,这一机制确保记忆库不会无限膨胀。例如,在HotpotQA任务中,仅引入SCEC机制导致Prompt Tokens激增43%(2.46M→3.52M),而加入自调度控制器后,Token增幅收窄至10%(3.52M→3.88M),证明控制器能高效筛选高价值记忆。
4. 使用:跨域知识扩散——知识的"一带一路"
SEDM的真正突破在于其跨域知识迁移能力,这使记忆系统不再局限于单一任务,而是能够实现知识在不同领域间的安全扩散。这一能力的核心在于"抽象-迁移-验证"的闭环工作流程。
抽象过程通过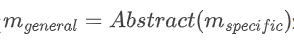 将特定领域的记忆转化为通用形式。这一过程是"规则驱动且最小化"的:将实体和领域特定术语替换为类型化占位符,保留可操作的任务-动作结构,同时去除非必要细节。例如,"搜索'2023年诺贝尔物理学奖得主'"可能被抽象为"搜索'[YEAR]年[AWARD]得主'",其中[YEAR]和[AWARD]是类型化占位符。
将特定领域的记忆转化为通用形式。这一过程是"规则驱动且最小化"的:将实体和领域特定术语替换为类型化占位符,保留可操作的任务-动作结构,同时去除非必要细节。例如,"搜索'2023年诺贝尔物理学奖得主'"可能被抽象为"搜索'[YEAR]年[AWARD]得主'",其中[YEAR]和[AWARD]是类型化占位符。

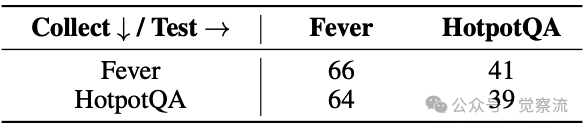
关键价值:这一机制使知识能够安全地跨任务迁移。在实际应用中,这意味着你在事实验证任务中积累的经验,可能成为解决复杂推理任务的金钥匙。正如实验数据所示,FEVER→HotpotQA的迁移得分达41分,甚至超过了HotpotQA原生的39分。
实证说话:数据不会说谎
SEDM的理论优势在实证中得到了充分验证。在FEVER事实验证和HotpotQA多跳推理两个基准测试上的结果,清晰展示了其在性能与效率方面的双重优势。
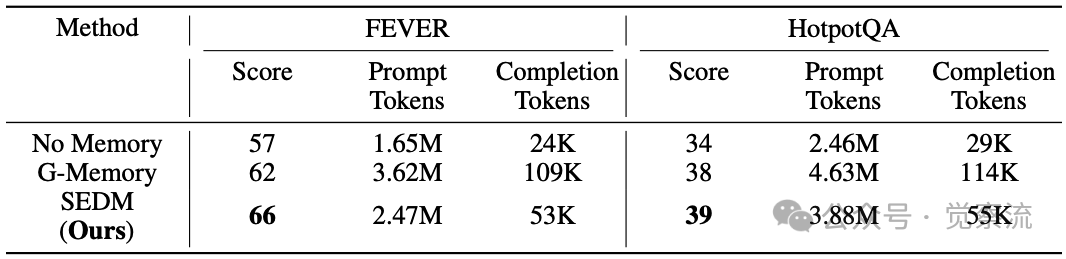
SEDM与基线方法对比
上表展示了SEDM与基线方法的详细对比。在FEVER数据集上,无记忆基线仅得57分,G-Memory将分数提高到62分,而SEDM实现了最高的66分,同时消耗的Tokens远少于G-Memory。
关键收获:SEDM在FEVER上仅用2.47M Prompt Tokens就达到66分,而G-Memory需要3.62M Tokens才能得到62分。这意味着SEDM每百万Tokens带来26.7分的效率,比G-Memory的17.1分高出56%!这直接转化为项目成本的大幅降低——在实际业务中,这意味着每月可能节省数万元的API调用费用。
在HotpotQA数据集上,趋势与FEVER类似。无记忆基线仅得34分,G-Memory将分数提高到38分,而SEDM进一步将性能提升至39分,同时减少了计算开销。
关键收获:SEDM在HotpotQA上将Prompt Tokens从G-Memory的4.63M减少到3.88M(减少16%),而准确率却从38分提升到39分。这意味着你的系统不仅更快,而且更准。
SEDM组件消融研究
上表的消融研究进一步揭示了各组件的贡献。在HotpotQA上,仅引入SCEC机制导致Prompt Tokens激增43%(2.46M→3.52M),证明仅靠准入机制无法控制规模膨胀;而加入自调度机制后,Token增幅收窄至10%(3.52M→3.88M),证实控制器能高效筛选高价值记忆。
关键收获:在实际项目中,这意味着添加SCEC机制会使API调用成本增加43%,但加入自调度控制器后,成本增幅降至10%,同时准确率继续提升。这直接解决了"性能与成本"的权衡难题。
在FEVER上,Completion Tokens在引入自调度后保持53K不变,说明控制器成功避免了因过多记忆注入而导致的回答冗长问题。
关键收获:Completion Tokens直接关系到LLM调用费用,保持稳定意味着即使记忆库扩大,你的回答成本也不会增加,这对成本敏感型应用至关重要。
SEDM跨域评估结果
上表的跨域迁移实验带来了更令人惊喜的发现:当将FEVER上收集的记忆应用于HotpotQA任务时,得分达到41分,甚至超过了HotpotQA原生的39分。
关键收获:这说明从基础事实验证中提炼的知识,能够有效支撑复杂的多跳推理任务——就像掌握了扎实的数学基础后,解决应用题变得更容易。在实际业务中,这意味着你在一个领域积累的经验,可能成为解决另一个领域难题的金钥匙。
相反,HotpotQA→FEVER的迁移仅得64分(低于原生66分),反映出"多跳推理知识对于事实验证的直接可重用性较低"。这一不对称性揭示了知识迁移的方向性规律——从基础事实到复杂推理的知识迁移效果优于反向迁移。
这对我们意味着什么?——SEDM的实践启示
SEDM框架的成功实践提炼出三大可复用的设计范式:实证主义准入、证据驱动调度和保守抽象迁移。这些范式共同构建了一个可验证、自优化、可迁移的记忆系统,从根本上解决了长期MAS的记忆管理难题。
1. 记忆不应是静态存储,而应是动态演化的智能组件
SEDM的核心启示是:记忆系统需要内置质量控制机制,而非简单扩大存储容量。在实际项目中,这意味着:
- 在记忆写入阶段,通过SCEC机制进行A/B测试,确保只有经过验证的记忆才能进入记忆库
- 在记忆使用阶段,利用历史效用权重替代临时重排序,避免"越多越差"的规模陷阱
- 在长期运行中,通过语义合并和冲突检测,保持记忆库的精简高效
实践建议:如果你正在开发长期运行的多智能体系统,应该首先关注记忆准入机制。实施SCEC验证可能增加初期开发成本,但会显著降低长期维护成本。根据实验数据,SEDM在FEVER上减少了32%的Prompt Tokens,这意味着每月可能节省数万元的API调用费用。
2. 跨任务知识迁移需要严格的验证闭环
SEDM的跨域知识扩散机制揭示了一个关键洞见:知识迁移不是"拿来主义",而是"安全迁移"。在实际应用中,这意味着:
- 抽象过程应保持最小化,仅替换实体为类型化占位符,保留任务-动作结构
- 跨域迁移必须经过目标领域的实证验证,避免"水土不服"
- 知识迁移存在方向性——从基础事实到复杂推理的迁移效果优于反向迁移
实践建议:如果你的系统需要处理多个相关任务,应该优先考虑从简单任务向复杂任务的知识迁移。例如,先在事实验证任务中积累高质量记忆,再将这些记忆安全迁移到多跳推理任务中。实验数据显示,FEVER→HotpotQA的迁移得分达41分,比原生HotpotQA高2分,这直接转化为用户体验的提升。
3. 构建可持续的长期MAS需要"记忆即服务"架构
SEDM框架为构建真正可持续演化的长期多智能体系统提供了坚实基础。随着更多任务领域的接入和验证,这种"记忆即服务"的架构有望成为下一代智能体基础设施的核心组件。
实践建议:在设计多智能体系统时,应将记忆系统视为独立的服务组件,而非简单的存储模块。这包括:
- 为记忆系统设计独立的验证和调度机制
- 建立记忆的版本控制和回滚能力
- 支持跨任务的知识迁移和验证
从"记忆"到"智慧积累"
SEDM不仅解决了当前多智能体系统的记忆瓶颈,也为AI系统从"记忆"走向真正的"智慧积累"铺平了道路。在追求长期可持续协作的AI未来,这种将记忆视为主动、可验证、自进化组件的理念,或将重新定义我们对智能体认知架构的理解。
最令人振奋的是,SEDM的三大设计范式——实证主义准入、证据驱动调度和保守抽象迁移——不仅适用于记忆管理,还可扩展到其他AI系统组件。通过将"可验证性"和"自优化"原则嵌入系统设计,我们有望构建出真正可持续演化的智能体系统,使AI不仅能完成任务,更能从经验中学习和成长。
想想看,当你的多智能体系统运行一年后,不仅没有因为记忆膨胀而性能下降,反而越用越聪明——这就是SEDM带来的革命。随着更多任务领域的接入和验证,这种"记忆即服务"的架构有望成为下一代智能体基础设施的核心组件,推动AI系统从"记忆"走向真正的"智慧积累"。


