
向自然语言处理的大模型应用,数据工程的核心任务是构建一套高效、可扩展、可控的数据流程,从源头到可用于模型训练、推理的高质量文本语料,全链路打通。
数据工程的整体目标
构建稳定的数据流转链路,从原始文本数据 → 清洗/标注/审核后的语料 → 符合模型输入格式的数据集
保证数据可用性、完整性、质量、结构统一性
支持多阶段使用场景:训练/微调、推理RAG、评估测试等
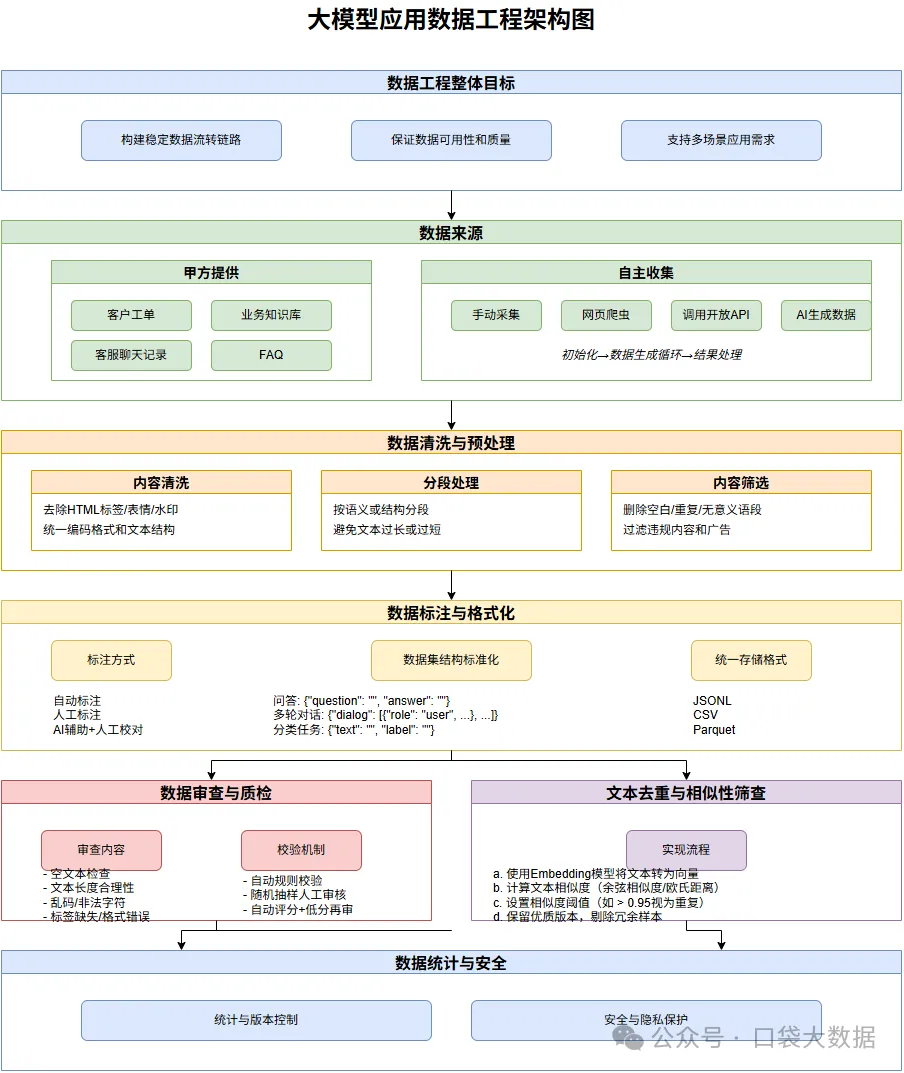
数据来源
最常见的形式是甲方提供,如客户工单、业务知识库、客服聊天记录、FAQ 等。
需尽早明确数据格式、内容范围、隐私边界。也需明确数据目标用途、是否可公开训练、是否需要脱敏。也可以自主收集,成本高、周期长,但更具通用性和自主性。数据收集有下面几种方式:
手动采集:(如论坛、PDF、博客文章等)
网页爬虫:需遵循 robots 协议与合法边界
调用开放接口:(如新闻、百科类 API)
AI 生成数据:(如大模型生成问答对,用于训练增强)
AI 生成数据示例
以微调训练金融科技领域问答模型为例,通过 AI 生成训练数据。
流程:
初始化
- 设置两种对话风格配置:
- 小白风格:通俗易懂的比喻解释,限制术语使用
- 资深风格:专业术语和技术细节,要求严谨准确
- 每种风格包含:
- 系统角色设定(system_prompt)
- 示例对话(examples)
- 温度参数(控制回答随机性)
数据生成循环
- 构建包含系统提示和示例的对话上下文
- 从预设问题列表中随机选取问题
- 调用 AI 接口获取风格化回答
- 结构化存储问答对(问题、回答、风格标签)
- 加入延迟防止 API 限流
结果处理
- 合并所有生成的问答数据
- 处理可能的异常情况(如中断请求)
- 将最终数据集保存为格式化的JSON文件
示例代码:
复制import json
import time
import random
from zhipuai import ZhipuAI
# 初始化模型
client = ZhipuAI(api_key="48b393b3474e43f3b7eafceb662db81a.xxxxxx")
style_config = {
"小白": {
"system_prompt": "你是一位区块链科普专家,需要用最简单易懂的方式向完全不了解技术的普通人解释区块链概念。要求:\n1. 使用生活化比喻(如'像大家一起记账本')\n2. 避免专业术语,必须使用时立即解释\n3. 回答控制在3句话以内\n4. 可适当使用🌐⛓️💡等表情符号",
"examples": [
{"role": "user", "content": "区块链到底是什么?"},
{"role": "assistant",
"content": "想象一群人在共同维护一个公开账本🌐,每笔交易都记录在所有人的本子上,想作弊就得改掉大部分人的记录,这几乎不可能⛓️!"},
{"role": "user", "content": "比特币为什么值钱?"},
{"role": "assistant", "content": "就像限量版球星卡💎,总量固定(2100万枚),越来越多人想要时价格就上涨啦!"}
],
"temperature": 0.2 # 低温度值保证回答稳定性
},
"资深": {
"system_prompt": "你是区块链核心技术研究员,需满足:\n1. 使用专业术语(如'椭圆曲线数字签名''梅克尔帕特里夏树')\n2. 包含技术实现细节\n3. 必要时给出公式/代码片段\n4. 引用最新论文成果(如2023 IEEE S&P会议)",
"examples": [
{"role": "user", "content": "请解释zk-SNARKs的工作原理"},
{"role": "assistant",
"content": "zk-SNARKs依赖QAP(二次算术程序)将计算转化为多项式关系:\n1) Setup生成CRS(公共参考串)\n2) Prover构造π=(A,B,C)满足A*B=C+H*Z\n3) Verifier通过双线性配对验证e(A,B)=e(C,g)⋅e(H,g^z)\n参考:Groth16方案优化后验证仅需3个配对运算。"},
{"role": "user", "content": "分析EIP-4844对L2的影响"},
{"role": "assistant",
"content": "Proto-danksharding通过引入blob携带交易(每个blob≈125KB),使Rollups数据可用性成本降低10-100倍。实测显示:\n- Optimism交易费从$0.3→$0.007\n- zkSync证明生成时间减少40%"}
],
"temperature": 0.5 # 中等温度值允许一定创造性
}
}
def generate_style_data(style_name, num_samples=50):
config = style_config[style_name]
data = []
# 构建对话上下文 = 系统提示 + 示例对话
messages = [
{"role": "system", "content": config["system_prompt"]},
*config["examples"]
]
# 预定义的用户问题集(可扩展)
user_inputs = [
"比特币和区块链是什么关系?",
"智能合约真的安全吗?",
"普通人怎么参与DeFi?",
"解释一下零知识证明",
"为什么NFT能卖那么贵?",
"区块链能防止数据造假吗?"
]
for _ in range(num_samples):
try:
# 随机选择问题
user_msg = random.choice(user_inputs)
# 当前对话 = 历史上下文 + 新问题
current_messages = messages + [
{"role": "user", "content": user_msg}
]
# 调用API(修正模型名称)
response = client.chat.completions.create(
model="glm-4-plus",
messages=current_messages,
temperature=config["temperature"],
max_tokens=150
)
# 获取回复内容
reply = response.choices[0].message.content
data.append({
"user": user_msg,
"assistant": reply,
"style": style_name
})
print("获取最新回复内容: ", data[-1])
time.sleep(0.5) # 限流
except Exception as e:
print(f"生成失败:{str(e)}")
return data
if __name__ == '__main__':
all_data = []
try:
print("开始生成小白风格数据...")
gentle_data = generate_style_data("小白", 10)
all_data.extend(gentle_data)
print("开始生成资深风格数据...")
gentle_data = generate_style_data("资深", 10)
all_data.extend(gentle_data)
except KeyboardInterrupt:
print("\n用户中断,保存已生成数据...")
finally:
with open("style_chat_data.json", "w", encoding="utf-8") as f:
json.dump(all_data, f, ensure_ascii=False, indent=2)
print(f"数据已保存,有效样本数:{len(all_data)}") |
数据清洗与预处理
原始数据往往杂乱无章,需系统清洗处理。
- 内容清洗
- 去除 HTML 标签、表情、特殊符号、水印等无效信息
- 统一编码格式,规范文本结构(如换行、缩进)
- 分段处理
- 按语义或结构分段,确保模型输入粒度适当
- 避免文本过长或过短,提升模型效果
- 内容筛选
- 删除空白内容、重复内容、无意义语段
import jsonfrom typing import List, Dictdef is_meaningless(text: str) -> bool: """检查是否是无意义内容""" # 空白或超短内容 if len(text.strip()) < 5: return True # 常见无意义模式 meaningless_phrases = [ "我不知道", "无法回答", "这个问题", "请重新提问" ] return any(phrase in text for phrase in meaningless_phrases)def simple_clean(data: List[Dict]) -> List[Dict]: """基础清洗流程""" seen = set() # 用于去重 cleaned_data = [] for item in data: text = item["assistant"].strip() # 检查空白/重复/无意义 if (not text or text in seen or is_meaningless(text)): continue seen.add(text) cleaned_data.append({ "user": item["user"], "assistant": text, "style": item["style"] }) return cleaned_dataif __name__ == '__main__': # 加载原始数据 with open('style_chat_data.json', 'r', encoding='utf-8') as f: raw_data = json.load(f) # 执行清洗 cleaned_data = simple_clean(raw_data) # 保存结果 with open('cleaned_data.json', 'w', encoding='utf-8') as f: json.dump(cleaned_data, f, ensure_ascii=False, indent=2) # 打印简单报告 print(f"原始数据量: {len(raw_data)}") print(f"清洗后保留: {len(cleaned_data)}") print(f"过滤数量: {len(raw_data) - len(cleaned_data)}") |
过滤掉违法违规、广告类内容,保障数据合规
数据标注与格式化
根据用途,对数据进行结构化和标注。
标注方式
- 自动标注:适合结构化文本、已有知识图谱辅助生成
- 人工标注:适用于对话意图、情感分类、多轮对话标记等复杂任务
- AI 辅助+人工校对:效率与质量的平衡方式
数据集结构标准化
- 根据目标任务结构设计
- 问答:{"question": "", "answer": ""}
- 多轮对话:{"dialog": [{"role": "user", "content": ""}, {"role": "assistant", "content": ""}, ...]}
- 分类任务:{"text": "", "label": ""}统一存储格式
- JSONL
- CSV
- Parquet
数据审查与质检
保证数据质量,避免模型效果被低质样本污染。
审查内容
- 是否存在空文本?
- 文本长度是否合理?
- 是否出现乱码、非法字符?
- 是否有标签缺失、格式错误?
常规校验机制
- 自动规则校验(正则、长度范围)
- 随机抽样人工审核
- 自动评分 + 低分样本再审
文本去重与相似性筛查
消除重复文本,避免模型过拟合。
实现思路:
- 使用 Embedding 模型,将文本转为向量表示
- 计算文本对之间的相似度(如余弦相似度或欧氏距离)
- 设置合理相似度阈值(如 > 0.95 即视为重复)
- 保留更优版本文本,剔除相似冗余样本
复制import json
from sentence_transformers import SentenceTransformer
import numpy as np
def deduplicate_data(data_list, threshold=0.9):
"""
语义去重:对 assistant 回复去重
:param data_list: List[dict], 每个 dict 包含 user / assistant / style
:param threshold: float, 相似度阈值
:return: 去重后的 List[dict]
"""
model = SentenceTransformer("/root/autodl-tmp/models/thomas/text2vec-base-chinese")
replies = [item["assistant"] for item in data_list]
embeddings = model.encode(replies)
kept = []
seen = set()
for i, emb_i in enumerate(embeddings):
if i in seen:
continue
keep = True
for j, emb_j in enumerate(embeddings):
if j == i or j in seen:
continue
sim = np.dot(emb_i, emb_j) / (np.linalg.norm(emb_i) * np.linalg.norm(emb_j))
print(f"sim({i}, {j}) = {sim:.4f}")
if sim > threshold:
seen.add(j)
kept.append(data_list[i])
return kept
if __name__ == '__main__':
with open("style_chat_data.json", "r", encoding="utf-8") as f:
all_data = json.loads(f.read())
cleaned_data = deduplicate_data(all_data, 0.5) |
数据统计与版本控制
- 记录每轮数据处理中的:样本数量、保留比例、清洗率、标注覆盖率等
- 建立数据集版本控制机制(如 v1、v2、实验版、正式版)
- 便于溯源、复现、对比实验效果
数据安全与隐私保护
尤其是面向企业应用时,必须落实数据安全要求。
- 敏感字段脱敏(如姓名、电话、身份证、公司信息等)
- 权限分级,控制访问范围
- 明确数据使用范围(训练 or 部署 or 产品化)
- 加入审计与日志记录
参考文献:https://gcn0rm30wzh6.feishu.cn/docx/MsqhdNNkQotaNfxULM5csoqYnec
写在最后
2025年的今天,AI创新已经喷井,几乎每天都有新的技术出现。作为亲历三次AI浪潮的技术人,我坚信AI不是替代人类,而是让我们从重复工作中解放出来,专注于更有创造性的事情,关注我们公众号口袋大数据,一起探索大模型落地的无限可能!
另外目前我正在做两个开源项目,一个本地知识库还有一个是小红书的智能发布工具,如果有需求的话可以加入下面的群聊中交流。
EasyRAG是我开源的一个本地知识库项目,未来我会再里面分享使用EasyRAG做各种场景的问答或者文档生成的最佳实践文档


