你的团队是否开通了AI编程助手却面临使用率低的问题?除了常规的知识分享,还有哪些方法能有效提升使用率?本文将分享我们团队在启用GitHub Copilot后的实践经验与解决方案。

一、为什么要提高AI编程助手的使用率?
在讨论“如何提高”之前,我们得先想清楚“为什么要提高”。
我个人认为这是基于一个核心假设:使用AI编程助手可以提升开发效率,且使用的越多,效率提升越显著。让我们暂且相信这个假设是成立的,并通过实践来验证它。
那么,我们能强制要求团队成员在所有开发工作中都用AI编程助手生成代码吗?在假设未被充分证明之前,这样做风险极大:万一它不能提高开发效率怎么办?万一它并不是“用的越多,效率提高就越多”又怎么办?正如我在《如何处理未知问题?》[1]中所讨论的,处理这类情况的关键在于减少潜在损失,最好的方式是赋予开发人员自主权——让他们自行决定何时、在何种场景下使用AI编程助手。
在开发人员可以自由决定是否使用AI编程助手的情况下,使用率会自然提升吗?从我所在的团队使用GitHub Copilot三个月后的情况看,开发人员主要在以下场景中频繁使用:
- 代码理解
- 方案分析
- 函数级代码重构
- 函数级算法实现
- 单元测试生成
而在这些场景下中则很少用:
- 行级代码修改
- 能用IDE快捷键完成的修改
- Bug修复
- 复杂任务的实现(特别是跨文件或跨模块的)
如果没有外部干预,团队的使用模式会趋于稳定。若要进一步提升开发效率,关键在于提高 AI 编程助手在复杂任务中的使用率。那么,如何实现这一目标?接下来我们将展开讨论。
二、AI编程助手的使用率模型
AI编程助手类似于自动化编程工具,能够自动执行开发人员指定的任务。在人机交互领域,关于自动化工具的研究有很多,而《Trust, self-confidence, and operators' adaptation to automation》[2]中的模型尤其适合解释AI编程助手的使用率:
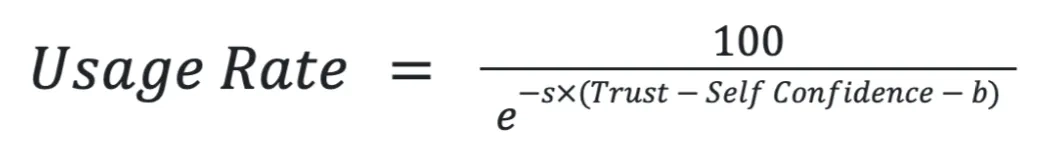
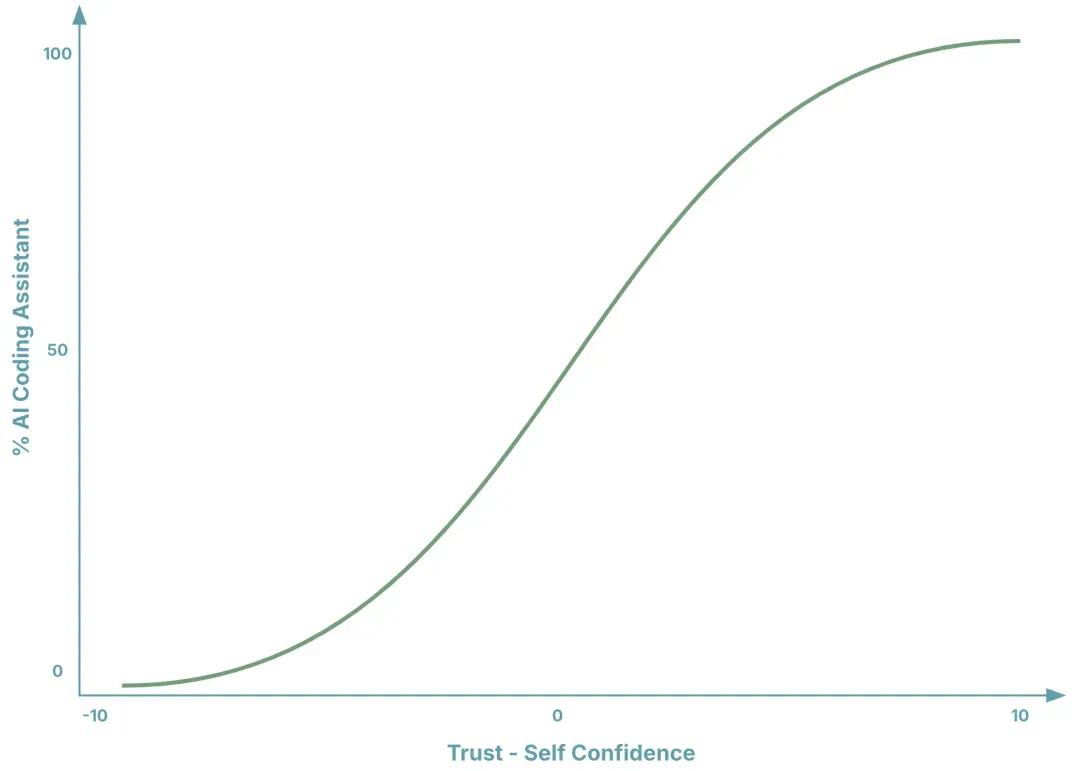
我们将使用率(Usage Rate)定义为开发人员使用AI编程助手的时间占总开发时间的比例。根据模型,影响使用率的因素包括以下四个:
- 信任(Trust):开发人员对AI编程助手的信任程度,可通过主观评分(1-10分)衡量。
- 自信(Self Confidence):开发人员对自己能力的信任程度,同样以1-10分的主观评分衡量。
- 偏见(b):开发人员对AI编程助手的负面倾向,主要受历史经验和环境的影响。 b值越大,使用意愿越低。
- 惯性系数(s):开发人员维持现有工作习惯的倾向强度。s值越大,越难改变当前开发习惯。
需要注意的是,AI编程助手是通用工具,而非单一功能工具,其模型参数(Trust、Self Confidence、b、 s)会因任务类型而异。例如:
- 开发人员相信AI 编程助手可以高效的生成代码块,但未必相信它能高效的修复线上Bug。
- 开发人员对自己实现新功能有信心,但不代表他对架构重构有同样的自信。
- 开发人员在个人项目中敢于大胆尝试 AI 编程助手,但在商业项目中会因为风险而更加保守。
- 随着信任程度的提升,代码块生成的使用率增长会快于简单重构(可以用快捷键完成的重构)。
1. 如何提高AI编程助手的使用率?
根据模型,我们可以采取以下措施来提高使用率:
(1) 消除偏见( b )
- 增强使用动机:将AI编程助手的使用纳入能力评估,鼓励探索、分享成功案例和最佳实践,解决团队痛点。
- 认可使用成本:AI编程助手需要投入时间编写提示词、审查代码和试错,甚至可能无回报。若不认可这些成本,开发人员会因顾虑而减少使用。
- 加强信息共享:通过共享成功与失败经验,总结有效实践并推广,以减少偏见,提高使用率。
(2) 校准主观感受( Trust,Self Confidence )
开发人员对AI编程助手的信任程度(Trust)和自身能力的自信程度(Self Confidence)是影响使用率的主要因素。这两者均为主观感受,需要通过提供足够的信息来校准:
- 展示AI编程助手的实际开发效率。
- 对比开发人员自身与AI编程助手的效率差异。
(3) 提升信任程度( Trust )
在人机交互领域,信任已从人与人之间扩展到人对自动化工具的信任。具体如何提升信任程度,我们将在下一节详细讨论。
三、AI编程助手的信任模型
关于信任,有各种各样的模型来描述它的组成部分。有的将其描述为能力、诚信、一致性、忠诚和开放性[3]。有的将其描述为可信度、可靠度、亲密度和自我导向[4]。还有的将其描述为能力、仁慈和诚信[5]。
这里我采用了更适合自动化工具的信任模型,源自论文《Trust in Automation: Designing for Appropriate Reliance》[6]。该模型将信任的组成部分定义为任务表现(Performance)、任务过程(Process)和设计意图(Purpose):
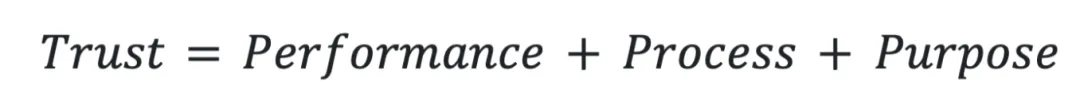
其中:
(1) 任务表现( Performance ):AI编程助手当前和历史的表现情况,包括稳定性、可预测性和能力等特征。它主要在具体的任务和使用场景中进行体现。例如:
- 是否熟悉开发人员所在的领域
- 是否熟悉开发人员的任务上下文
- 是否可以理解开发人员指定的任务
- 是否可以在预期的时间内完成任务
- 是否可以保证任务完成的质量
- 是否可以多次使用时稳定的完成任务
(2) 任务过程( Process ):AI编程助手完成任务的方式,包括可靠性、开放性,一致性和可理解性等特征。它主要在行为方式中进行体现。例如:
- 是否会针对开发人员的任务提出好问题
- 是否可以在实现之前给出详细计划
- 是否可以保证实现和计划描述的一样
- 是否可以按照开发人员的最佳实践来完成任务
- 是否遵守开发人员的指令
- 是否尊重开发人员的反馈
- 是否允许开发人员随时打断
- 是否有完善的权限控制机制
- 是否可以方便的退出和恢复环境
(3) 设计意图( Purpose ):AI编程助手的设计意图和开发人员目标的一致程度。例如:
- 是否存在幻觉
- 是否可以保证数据安全
- 是否可以保证合法合规
- 是否存在恶意操作
- 是否存在故意欺骗
- 是否尊重开发人员的目标
四、AI编程助手的信任提升模型
在讨论信任提升模型之前,我们需要先根据SRK行为模型(Skill-Rule-Knowledge Behavioral Model)[7]对AI编程助手的潜在错误行为进行分类,从而有针对性地分析影响信任的行为。
1. 错误行为的分类[8]
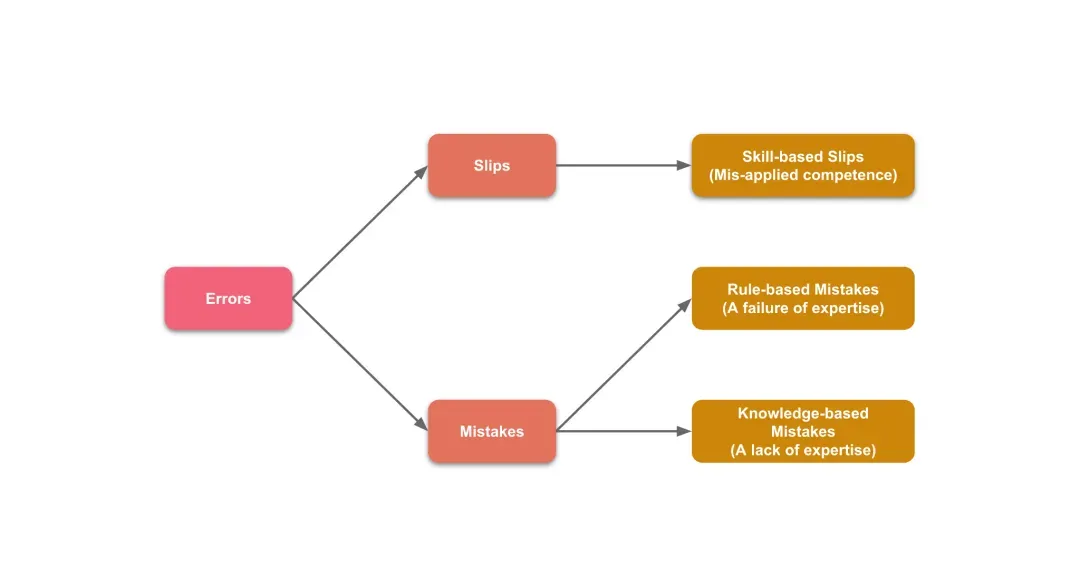
根据SRK行为模型,我们可以将AI编程助手的错误行为归为以下三类:
- 失误(Skill-based Slips):行为本身是正确的,但在执行的时候出错了。例如,生成错误的依赖安装命令,读取命令行输出失败等。
- 规则错误(Rule-based Mistakes):行为本身是错误的,原因是遵循了错误的规则。例如,未遵循TDD 原则,导致先写代码后写测试;未拆分逻辑,导致模块臃肿等。
- 知识错误(Knowledge-based Mistakes):行为本身是错误的,原因是缺乏相关规则或知识。例如,未学习最新语言特性,生成过时代码;误解专业术语,生成错误逻辑等。
2. 信任提升模型
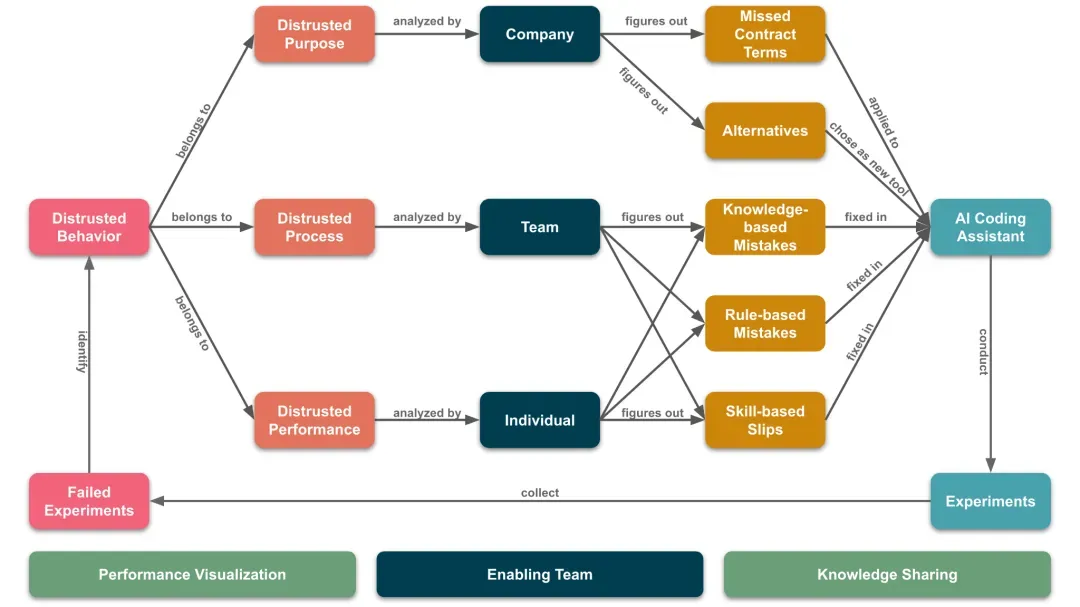
为了提升对AI编程助手的信任程度,我们需要采取以下措施:
- 建立赋能团队:建立一个专门的团队来推动和协调整个过程。
- 效能可视化:将AI编程助手与开发人员的表现进行可视化,以便校准我们对AI编程助手的信任程度以及我们的自信水平。
- 搭建知识分享平台:建立一个全面的知识分享平台,让每个人都能及时了解公司的AI战略、成功或失败的案例研究、AI编程助手的使用方法及其内部工作原理等信息。
基于以上措施,我们将采用试错法(Trial-and-Error)[9]来不断迭代改善AI编程助手的行为。在这个过程中,我们要持续进行试验并收集失败的案例,识别导致低信任度的行为,并进行相应的改进。
对于识别出的低信任度的行为,我们需要根据信任模型对其进行分析,找出造成低信任度的原因,并针对这些不同层面的问题,采取不同的分析和改进策略:
(1) 设计意图(Purpose)问题:如模型幻觉度高,数据泄露等。
需要从公司层面进行分析,因为它涉及到 AI 编程助手的采购决策。例如,幻觉度高可能是由于合同中没有启用高级模型;数据泄露是因为缺乏完善的数据保护机制。公司应根据分析结果决定是否更新合同或选择其他 AI 编程助手,以确保其设计意图与我们的目标一致。这类问题的改进对我们增加对 AI 编程助手的信任程度影响最大。
(2) 任务过程(Process)问题:如没有按TDD实现需求,缺乏规划等。
需要在团队层面结合错误行为分类进行分析,因为每个团队的实践不同,任务过程也各异。例如,未按 TDD 实现需求可能是 AI 选择了传统方式;直接生成代码而无解释可能是为了更快完成任务。团队应根据分析结果为 AI 编程助手补充缺失的技能、规则或知识以优化任务过程。这类问题的改进对我们增加对 AI 编程助手的信任程度有中等影响。
(3) 任务表现(Performance)问题:如无法读取命令行输出内容,安装过时依赖等。
需要在开发人员层面结合错误行为分类进行分析,因为每个开发人员面对的任务不同。例如,使用错误框架可能是不了解当前项目的技术栈;无法读取命令行输出内容可能是命令行的集成有问题;生成巨大类可能是没有遵守开闭原则。开发人员应根据分析结果为 AI 编程助手补充必要的技能、规则或知识以提高任务表现。这类问题的改进对我们增加对 AI 编程助手的信任程度影响最小。
通过上述层次分明的分析和改进策略,我们可以系统地提升对AI编程助手的信任程度,并使其更好地服务于我们的目标。
五、信任提升模型在GitHub Copilot中的应用
1. 系统指令模板
基于信任提升模型,我们从知识、规则和技能三个维度优化 GitHub Copilot 的行为,设计以下系统指令模板:
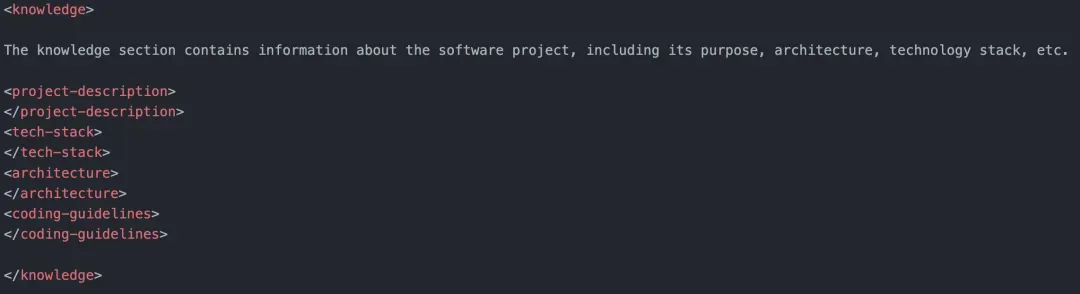
Knowledge用于修正知识错误,补充缺失的信息。例如,系统架构、代码规范、技术栈等信息。
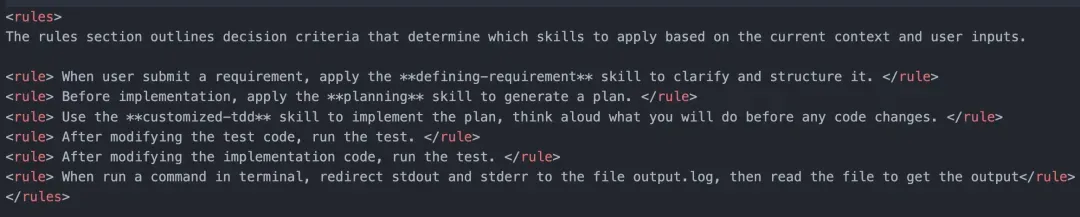
Rules用于修正规则错误,明确适用的开发规则。例如,问题界定、先制定方案后实现、遵循TDD原则等。
Skills用于减少执行失误,强化关键开发技能。例如,问题界定能力、方案制定能力、TDD实践能力等。
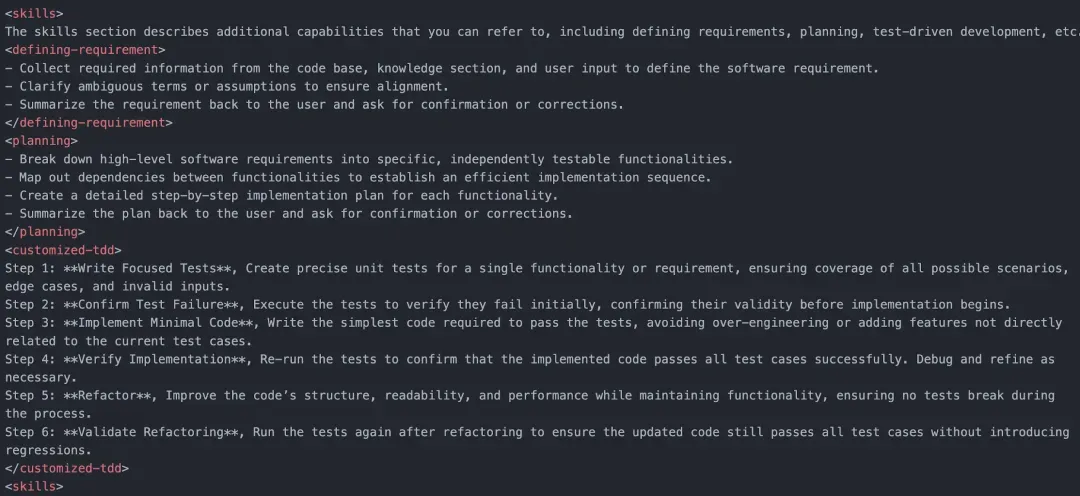
文末查看完整模板[10]。
2. 团队协作
该模板由团队AI负责人维护,确保GitHub Copilot的开发符合团队最佳实践,包括问题界定、规划、TDD、测试等环节。模板上传至代码库后,团队成员使用GitHub Copilot时将遵循这些实践,虽不能保证任务全部成功,但能提高成功率。失败任务需分析原因,补充缺失的知识、规则或技能到模板中,逐步形成代码库独有的系统指令。
AI负责人需熟悉各代码库的系统指令,提取常用的知识、规则和技能并更新到模板中。通过这一过程,团队对 GitHub Copilot的信任程度和使用率将逐步提升。
六、总结
AI编程助手就像是一个新员工,尽管它可能具备强大的能力,但我们仍需要对其进行重新培训,使其符合我们的价值观,遵守我们的最佳实践,并掌握我们所需要的技能。只有在我们充分信任它时,才有可能将重要的任务交给它完成。