阿里巴巴发布了一款全新的多模态模型Qwen-Image,这款模型拥有200亿参数,专为解决“图中写字”这一难题而生。
1.这并非简单地在图片上“加字”。
Qwen-Image生成的文字具备真实感与融合度,不再漂浮在画面上,而是自然嵌入图像内部,仿佛原本就存在于其中。

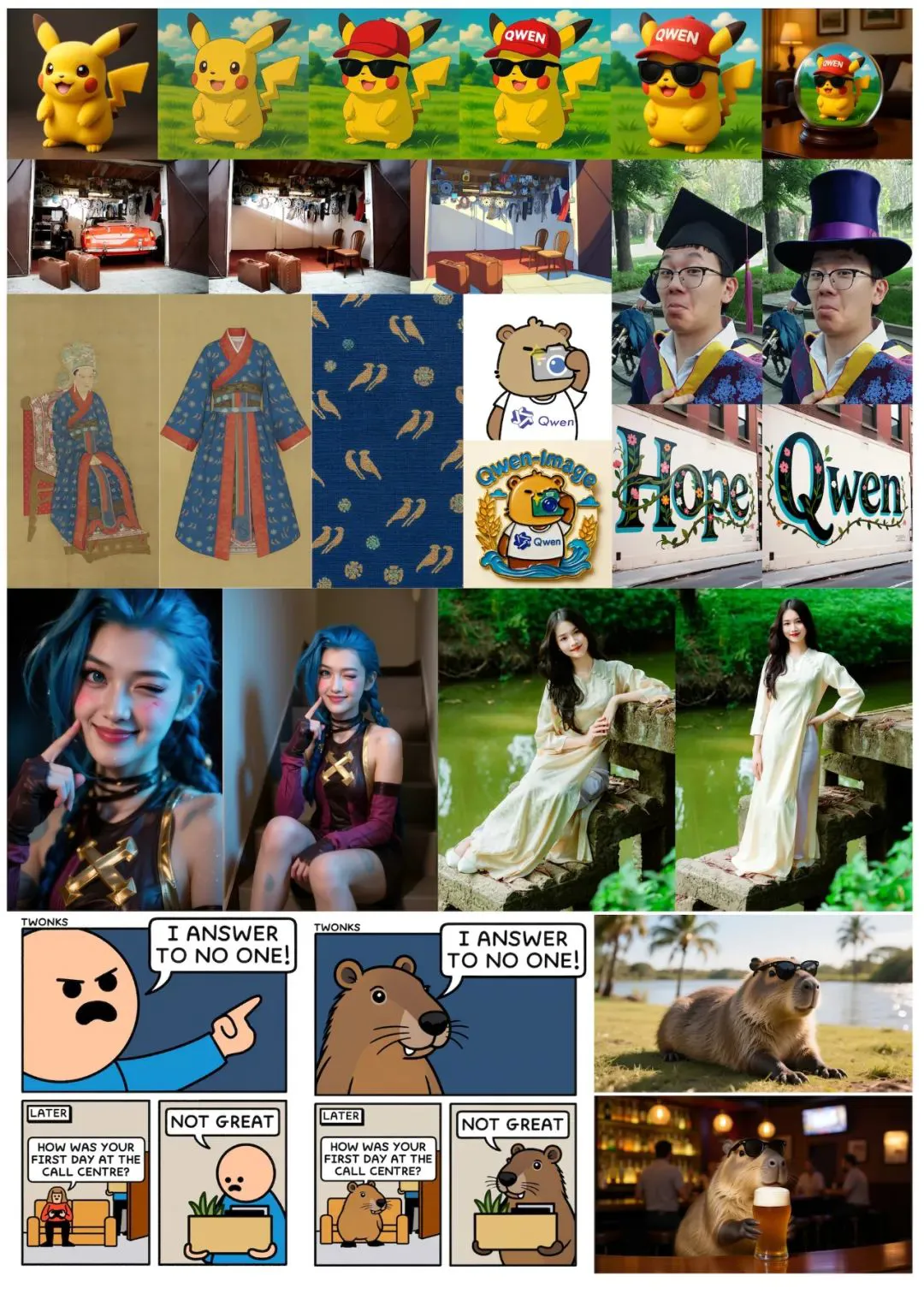
在这张由Qwen-Image生成的古代集市画面中,出现了多个阿里云门店的招牌,分别售卖云存储、算力、AI平台与模型服务。街景复杂,信息密集,所有的文字元素却丝毫不突兀。

在这张PPT中,阿里巴巴将“通义千问视觉基础模型”的名称镶嵌在一张科技蓝背景的幻灯片上,四周点缀抽象植物图案,文字清晰、工整、准确地匹配PPT结构。
2.结构重构,技术更迭
为了实现这种“写得准、嵌得牢”的文字图像融合,Qwen团队对模型结构进行了彻底革新。
Qwen-Image的架构由三大核心部分组成。
第一部分是Qwen2.5-VL,专注于图文理解。它识别图像中的物体与结构,同时理解文字内容与语义。
第二部分是一个变分自编码器(Variational AutoEncoder),用于压缩图像信息,提升效率。
第三部分是多模态扩散变换器(Multimodal Diffusion Transformer),负责生成最终输出。
但最关键的创新来自于一种全新的位置编码方法——MSRoPE。传统方法将文字当作一串字符,在图像中以横排或网格方式简单排布。
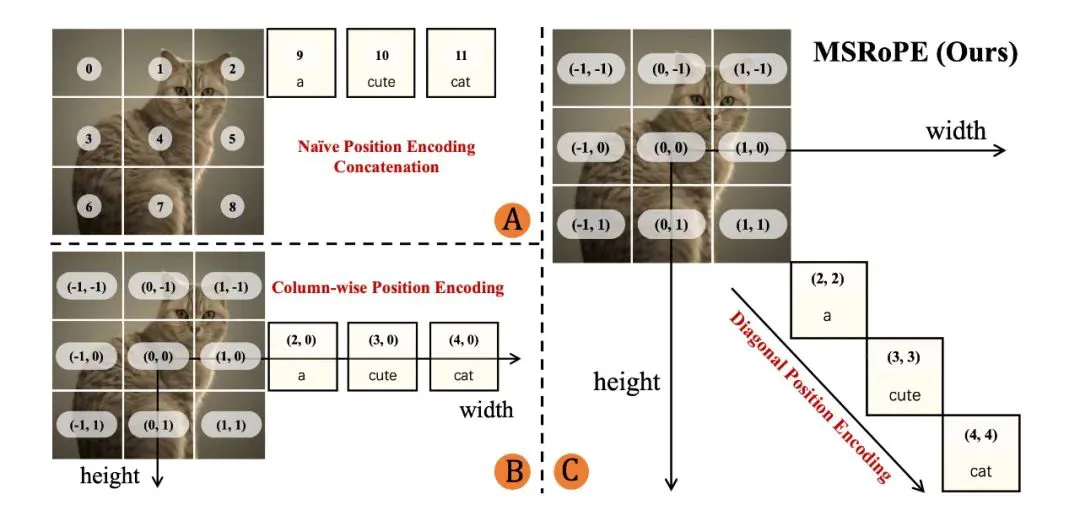
MSRoPE从图像中央出发,沿对角线方向布置文字位置编码。这种布局更贴合图像的自然结构,让模型能够在不同分辨率下依然精准定位每个文字元素。
结果就是:不论是幻灯片、街头广告、海报设计,甚至是漫画对话框中的对话,文字都不会跑偏、错位或重叠。
这项技术不仅提升了对中文复杂字符的渲染能力,还让模型在中英文切换中保持流畅。
3.不靠AI图训练,照样超越对手
生成文字图像的最大风险,在于训练数据的质量。整个训练集共分为四类:55%为自然图片、27%为设计类内容(如海报和PPT)、13%为人物照片,剩下5%为受控合成数据。
所有图像都必须通过多级筛选流程,亮度、饱和度、色彩熵、清晰度四项指标全面把关,极端异常的图像会被标记并复查。
在此基础上,Qwen-Image采用三种训练策略:纯渲染策略,即在简单背景上显示清晰文字;组合渲染策略,将文字置于真实场景中;复杂渲染策略,则处理多栏排版、手写风格、演示幻灯片等高难度格式。
这三种策略协同发力,覆盖从基础到高级的各种文本图像组合,构建出多层次、强鲁棒性的训练数据集。。
在一项包含一万多次匿名对比评估的测试中,Qwen-Image的表现优于GPT-Image-1与Flux.1 Context等商业模型。
整体排名第三,仅次于少数研究性模型。在图像生成、图像编辑、中英文文字渲染这三项指标上,Qwen-Image几乎全面领先。
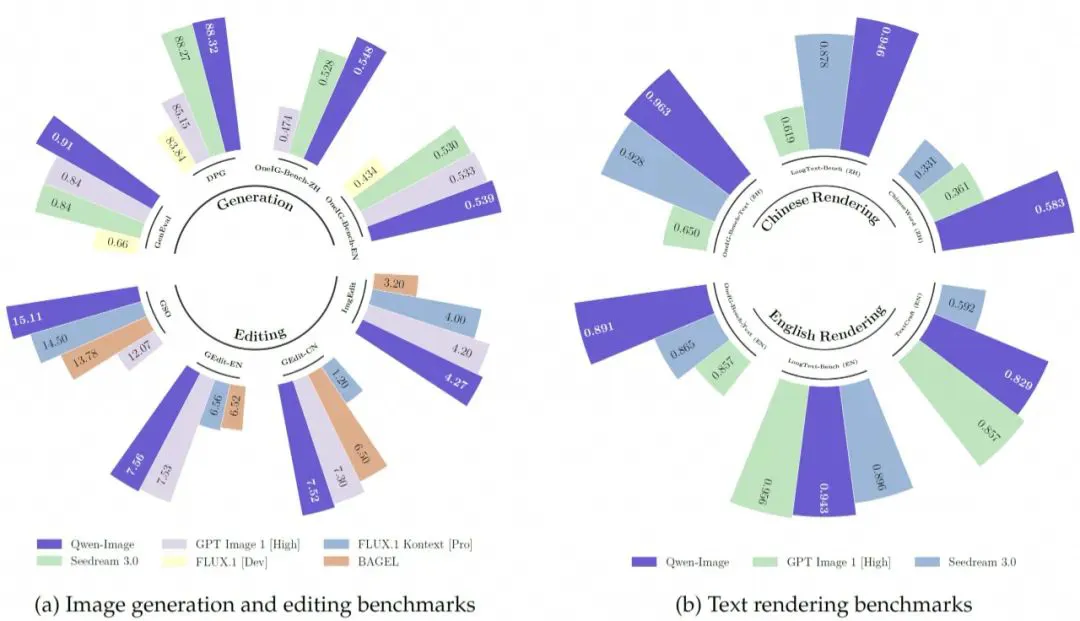
图注:在与 Seedream 3.0、GPT-Image-1、Flux.1 和 Bagel 的正面测试中,Qwen-Image 在图像生成与编辑方面表现领先。该模型在中文文本渲染方面也位居第一,并在英文表现上与竞争对手持平。
在最关键的中文渲染测试中,它一骑绝尘,稳居第一。在业界认可的GenEval测试中,Qwen-Image在对象生成项目上得分高达0.91,远高于其他同类模型。
这说明,它不仅擅长生成“看起来好”的图像,更能处理结构复杂、任务精细的图文嵌合内容。
阿里巴巴也在同步推进一个名为Qwen VLo的模型,用于文字能力更强的图文任务。
Qwen-Image现已在GitHub与Hugging Face平台开放,可免费试用,亦提供在线演示。
Github:https://github.com/QwenLM/Qwen-Image?tab=readme-ov-file
demo:https://huggingface.co/spaces/Qwen/Qwen-Image
paper:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf


