
大家好,我是肆〇柒。你的女友是否曾对着满屏“短裙”无奈点击“不喜欢”,却无法告诉系统“我想要一条适合秋天的长裙”?这种推荐系统的“失语症”,正是阿里巴巴集团联合中国人民大学、中国科学院大学最新研究《Interactive Recommendation Agent with Active User Commands》试图解决的核心问题。他们提出的 RecBot 框架,首次让主流推荐流支持自然语言命令,真正让用户从“被动接受”走向“主动塑造”。
想象这样一个场景:正值深秋,你的女友在电商平台浏览女装,却看到满屏短裙推荐。她想告诉系统"这是秋天,需要长裙",却只能点击"不喜欢"。系统无法区分你是不喜欢短裙款式还是季节不匹配,下次可能推荐完全不同风格的商品。下图中,用户面对"全是短裙"的秋季推荐束手无策,只能反复点击"不喜欢",却无法表达真实需求——这种挫败感每天发生在数百万用户身上。

传统推荐
推荐系统长期面临用户意图理解不精准的挑战。传统推荐系统依赖"点赞/踩"等被动反馈机制,无法捕捉用户细微行为动机和真实意图,导致系统解读与用户期望之间存在持久鸿沟。本文基于最新研究成果,探讨IRF范式如何通过自然语言命令弥合这一鸿沟,实现用户可控的精准推荐,为企业带来可量化的业务价值。
推荐系统的精准度困境:三重维度的根本问题
用户表达的局限性
传统推荐系统中,用户被限制在"点击、点赞、不喜欢或观看时长"等隐式行为信号中表达偏好,这种设计缺陷导致用户无法充分传达复杂偏好背后的精细推理。下图展示了典型场景:当用户看到一件"颜色不错但图案不喜欢"的商品时,系统只能接收到笼统的负面反馈,而无法识别具体是图案问题导致不满。

传统推荐
这种表达限制迫使用户通过模糊信号表达复杂偏好,关键信息在传递过程中大量丢失。研究数据进一步揭示了这一问题的严重性:在实际生产环境中,约57%的用户命令为负向反馈,表明用户更倾向于指出不喜欢的内容而非表达偏好。然而,传统系统缺乏有效机制来捕捉和处理这些负向信号,无法识别哪些特定项目属性驱动用户 satisfaction 或 dissatisfaction。这种单向度的反馈机制使得推荐系统如同"盲人摸象",只能基于有限的碎片信息猜测用户真实意图。
算法解读的模糊性
面对用户模糊且不完整的反馈,推荐算法不得不采取"无差别偏好归因"策略,将所有项目特征视为对用户响应同等负责。这种做法不可避免地导致不准确的偏好建模,系统无法区分哪些特征真正驱动了用户满意度。例如,当用户点击一件红色连衣裙时,系统可能同时将颜色、款式、材质等所有特征都视为用户偏好,而无法确定是哪个特征起了决定性作用。
这种不精确的建模方式进一步加剧了"过滤气泡"效应,系统不断推荐相似内容,缩小了内容多样性,形成恶性循环。更严重的是,现有交互式推荐方法主要关注正向用户需求,而忽视了负向反馈的关键价值。当系统无法准确理解用户"不要什么"时,推荐质量必然大打折扣,用户满意度随之下降。
系统性功能障碍
用户表达限制与算法解读模糊的相互作用,催生了一种"沟通僵局":当系统误解用户信号并推荐不相关内容时,用户只能通过更多模糊反馈进行纠正,而系统又可能继续错误解读这些反馈,形成恶性循环。这种双向沟通失效使得系统与用户之间无法有效传达或理解对方意图,最终导致用户体验下降、内容多样性降低和商业价值流失。
研究指出,这一问题需要"根本性范式转变而非渐进式改进"。传统被动反馈机制的局限性已经根深蒂固,仅靠优化现有算法无法解决用户意图与系统解读之间的根本性错位。必须重新思考人机交互模式,赋予用户更直接、更精细的控制权,才能真正弥合这一持久鸿沟。
这种系统性功能障碍揭示了传统推荐范式的根本局限——用户无法直接表达复杂意图,系统也无法准确解读模糊信号。要突破这一困境,必须重新思考人机交互模式,赋予用户更直接、更精细的控制权。这正是IRF范式的核心价值所在。
IRF范式的创新突破:从被动反馈到主动控制
IRF的核心价值主张
Interactive Recommendation Feed (IRF)范式提出了一个根本性创新:允许用户通过自然语言命令直接与推荐系统交互。下图展示了这一设计:用户可以输入"Good color, but prefer it plain"这样的指令,系统随即调整推荐策略,展示符合新要求的商品。这一设计将传统的单向信息流转变为双向对话,用户从被动接收者变为主动塑造者,能够"直接塑造内容消费体验而非被动接受算法决策"。
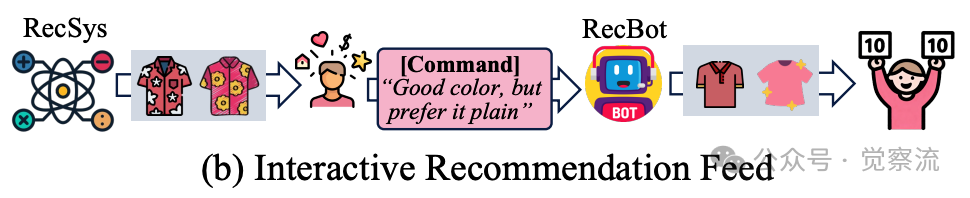
交互式推荐
IRF的独特价值在于其无缝集成设计。与需要独立对话窗口的对话式推荐系统(CRS)不同,IRF作为轻量级界面直接嵌入主流推荐流中(如YouTube、Taobao),用户无需中断自然浏览流程即可发出命令。这种设计既保持了现有推荐产品的用户体验连续性,又赋予了用户前所未有的控制权,实现了用户表达自由与系统响应能力的完美平衡。
IRF范式的核心突破在于将推荐系统从'猜测用户意图'转变为'协同探索偏好'。如上图所示,用户不再受限于被动反馈,而是能够通过自然语言直接塑造推荐策略。这一转变解决了三个问题:(1)用户表达自由度问题——57%的负向反馈得以精准传达;(2)算法解读模糊性问题——系统能区分"颜色不错但图案不喜欢"的精细意图;(3)系统性功能障碍问题——打破沟通僵局,实现真正的双向交互。
IRF与CRS的本质区别
IRF与对话式推荐系统(CRS)在理念和实现上存在本质差异。根据素材3.5.2节的分析,CRS主要针对目标明确的搜索任务,用户拥有清晰的信息需求和明确的购买意图;而IRF则适用于开放式探索场景,用户偏好在交互过程中逐步形成和演变。
在偏好获取方式上,CRS采用结构化提问方式,通过预定义的对话模式提取用户偏好;而IRF采用反应式范式,用户基于系统呈现的具体推荐结果提供上下文锚定的反馈。这种差异使得IRF更适合日常浏览场景,用户无需主动发起对话,只需对当前推荐内容进行即时反馈即可引导系统调整。
从产品定位看,IRF不是独立的对话系统,而是现有推荐流的增强层。它不改变用户的基本浏览行为,而是为这一行为增加了自然语言交互维度,使推荐系统能够更准确地理解用户意图,同时保持用户体验的流畅性。
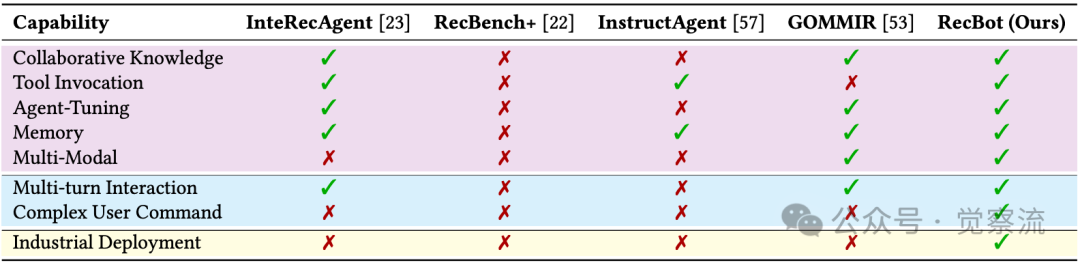
不同交互式推荐代理框架对比
上表进一步证实了RecBot的全面优势。与现有框架相比,RecBot在五个关键能力维度(协同知识、工具调用、代理调优、记忆管理、多模态处理)均表现出色,尤其在处理复杂用户命令和实现工业部署方面具有独特优势。这一全面能力使RecBot能够应对真实场景中多维度、多轮次的用户交互需求。
用户行为模式洞察
IRF范式的设计基于对用户行为的深刻洞察。实证数据显示,57%的用户命令为负向反馈,这一发现颠覆了传统推荐系统主要关注正向信号的设计思路。用户不仅表达"想要什么",更频繁地指出"不要什么",这种双向意图表达对精准推荐至关重要。
此外,用户偏好往往通过多轮交互逐步明确。初始反馈可能模糊或探索性,随着系统不断呈现相关内容,用户能够更精确地定义自己的需求。这种迭代式偏好澄清过程要求系统具备多轮交互能力,能够维护和更新用户偏好状态,同时处理可能的兴趣漂移。IRF范式正是基于这些行为模式洞察而设计,能够有效支持用户在探索过程中动态调整和细化偏好。
57%的负向反馈主导现象不仅揭示了用户行为模式,更指明了系统设计的关键方向:必须同等重视正向与负向信号的处理。要实现这一目标,需要构建能够精准解析自然语言命令、动态调整推荐策略的技术架构,这正是RecBot要解决的核心问题。
RecBot技术架构:从语言命令到精准推荐的转化机制
3.1 双代理架构设计
为实现IRF范式,研究团队开发了RecBot框架,采用双代理架构实现从自然语言命令到精准推荐的完整转化流程。下图清晰展示了这一架构,RecBot由Parser Agent和Planner Agent组成,形成一个闭环交互系统。
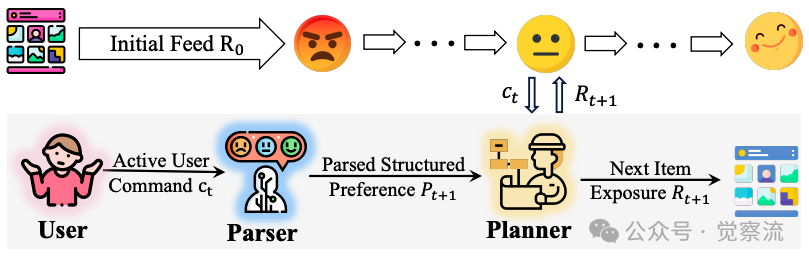
RecBot框架概述

动态内存整合策略
多轮交互对系统提出了记忆管理挑战:既要保持偏好一致性,又要避免计算开销过大。RecBot通过动态内存整合策略解决了这一难题,该策略基于三大更新原则运作:
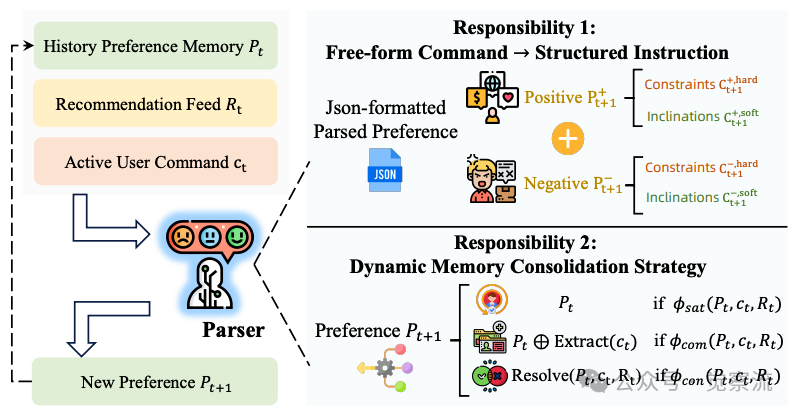
用户意图理解解析器示意图
上图直观展示了Parser的工作机制,它整合历史偏好记忆Pt、当前推荐流Rt和用户命令ct,生成新的偏好表示Pt+1。这一过程不仅实现自由形式命令到结构化指令的转换,还通过动态内存整合策略确保多轮交互中的一致性。

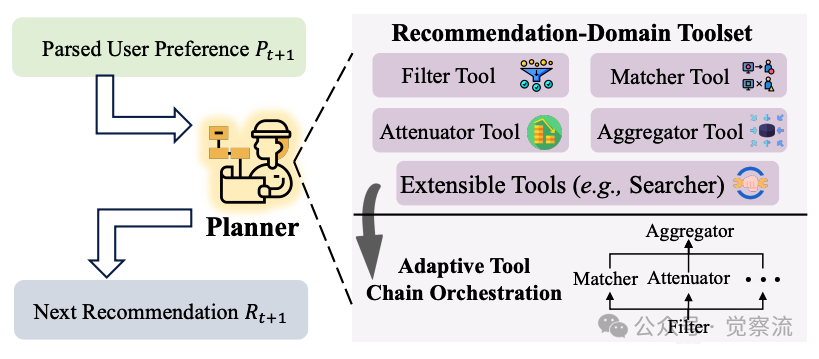
推荐领域工具集的自适应工具链编排
推荐领域工具集与自适应编排
RecBot的核心创新之一是构建了模块化、可扩展的推荐领域工具集,使Planner Agent能够灵活适应多样化的用户需求。
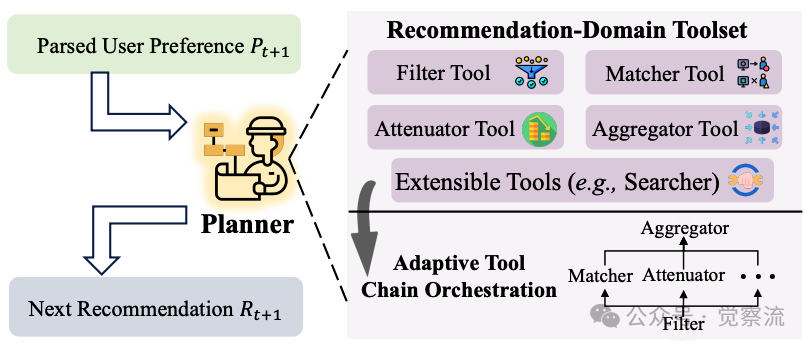
推荐领域工具集的自适应工具链编排
展示了这一工具集的动态编排机制,该工具集包括四个关键组件:

Planner Agent根据解析的用户偏好动态构建最优工具调用链。对于硬约束,优先调用Filter工具缩小候选空间;对于正向意图,激活Matcher计算相关性;对于负向反馈,则调用Attenuator进行惩罚评分。这种自适应编排确保系统能够高效、准确地响应各类用户命令,同时优化计算资源使用。
双向反馈机制的关键价值

这一双向建模方法源于对生产环境的实证观察:57%的用户命令为负向反馈。传统方法主要关注正向需求,而RecBot认识到负向反馈对精准推荐的同等重要性。例如,当用户说"不要花卉图案"时,系统能够准确识别并排除相关商品,而不是仅关注用户可能提到的正向特征。
硬约束与软倾向的区分进一步提升了推荐精度。硬约束(如"价格低于50美元")通过Filter工具严格执行,确保推荐结果符合用户底线要求;软倾向(如"偏好浪漫电影")则通过Matcher和Attenuator工具灵活处理,保持推荐多样性。这种精细化的偏好表达机制,使系统能够更准确地捕捉用户意图的细微差别。
实证效果:从离线实验到线上验证的全面评估
三种交互场景的离线表现
研究团队在Amazon、MovieLens和Taobao三个真实数据集上进行了全面评估,设计了三种递增复杂度的交互场景:
在单轮交互(SR)场景中,RecBot展现出显著优势。下表显示,在Taobao数据集上,RecBot-GPT实现了39.31%的通过率(Pass Rate),远超基线方法InteRecAgent的15.72%和GOMMIR的0.03%。Condition Satisfaction Rate(CSR@50)达到93.83%,表明系统能准确捕捉用户偏好细节。
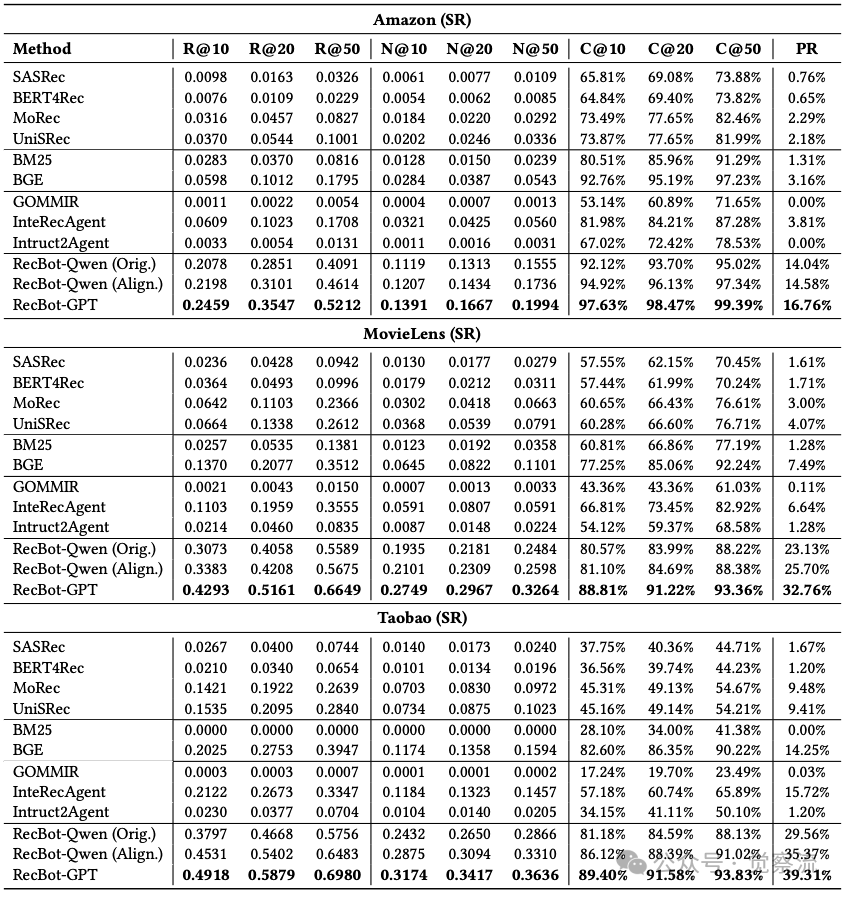
Single-Round(SR)交互场景性能比较
在多轮交互(MR)场景中,RecBot的优势更加明显。下表显示,在Taobao MR场景中,RecBot-Qwen(Align.)实现38.47%的通过率,平均仅需4.3827轮交互即可满足用户需求——这一效率比InteRecAgent(18.42%通过率,5.0791轮)高出109%。这意味着什么?假设你每周网购3次,每次节省1.4轮交互,一年就是218轮——相当于少点击"不喜欢"按钮218次。这不是微小改进,而是用户体验的根本提升。
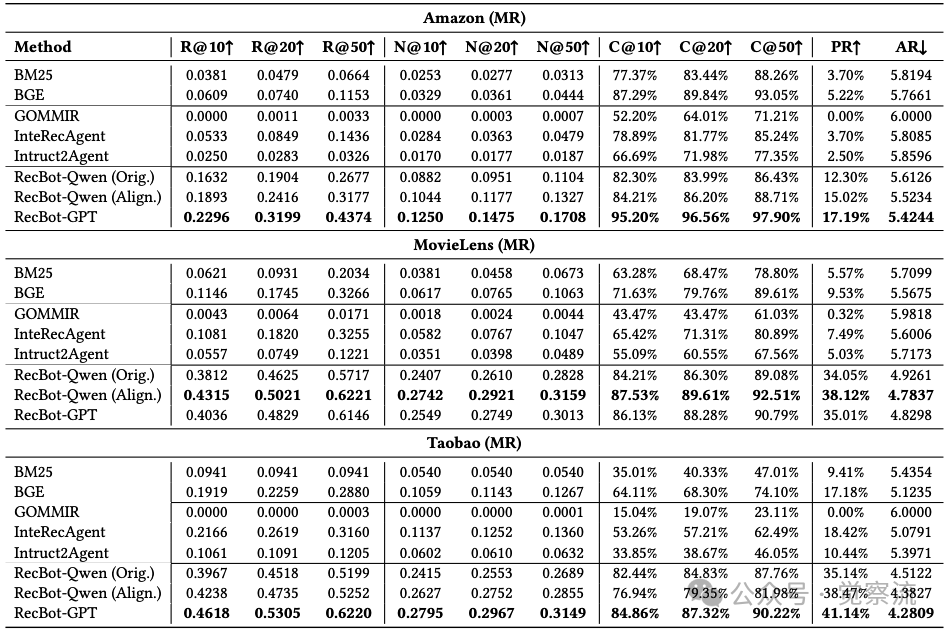 Multi-Round(MR)交互场景性能比较
Multi-Round(MR)交互场景性能比较
在最具挑战性的多轮交互与兴趣漂移(MRID)场景中,RecBot同样表现出色。下表显示,在MovieLens MRID数据集上,RecBot-Qwen(Align.)实现**33.51%**的通过率,显著优于其他方法。这一结果证明了系统处理用户兴趣动态变化的能力,对实际应用场景具有重要价值。
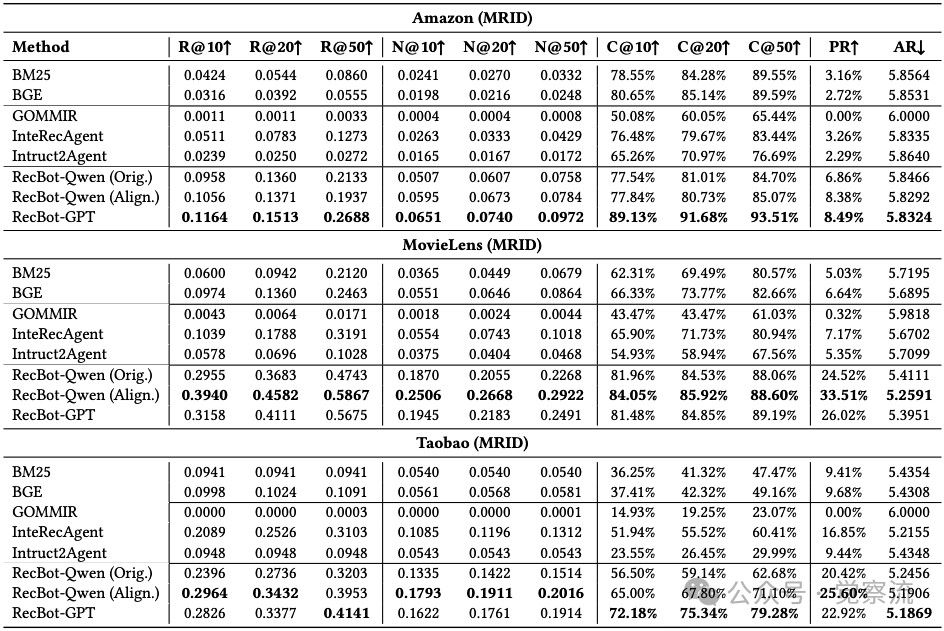
Multi-Round with Interest Drift(MRID)场景性能比较
知识蒸馏的突破性发现
研究团队采用模拟增强知识蒸馏方法实现轻量级部署,意外发现了一个突破性现象:经过知识蒸馏的学生模型能够超越教师模型。如素材4.2.1节所述,在MovieLens MRID场景中,RecBot-Qwen(Align.)实现了0.3940的Recall@10和33.51%的通过率,而其GPT-4.1教师模型仅为0.3158和26.02%。
这一发现具有重要的理论和实践意义。理论上,它验证了"专注知识转移可以 unlock 小型模型的潜在能力";实践上,它为轻量级部署提供了可行性保障,使高性能推荐系统能够在资源受限的环境中高效运行。这一现象与先前研究一致,表明经过针对性优化的小型模型可以在特定任务上超越通用大型模型。
RecBot-Qwen(Align.)超越GPT-4.1教师模型的现象不仅具有工程价值,更揭示了重要理论洞见:在特定任务上,经过针对性优化的小型模型可以超越通用大型模型。这一发现与创作素材4.2.2节的消融研究一致——Full RecBot(包含完整工具集)在Amazon MR场景中仅需5.42轮交互即可达到17.19%的通过率,而简化版本V1需要5.92轮且通过率仅为6.86%。这表明,针对推荐任务的模块化设计和知识转移比单纯依赖模型规模更为关键。
三个月线上A/B测试结果
RecBot已在大型电商平台首页完成为期三个月的线上A/B测试,结果令人印象深刻。下图显示,RecBot在关键指标上持续优于基线系统,所有指标变化趋势保持稳定。
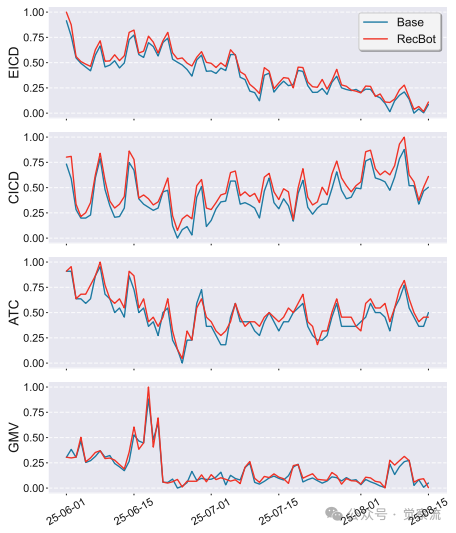
三个月A/B测试期间的在线性能曲线

RecBot相比基线模型的在线平均性能提升
上表清晰总结了系统在用户体验和商业价值两方面的全面提升:
- 负面反馈频率(NFF)降低0.71%,表明系统更准确地识别了用户偏好,减少了不相关推荐。这意味着每天有数百万用户不再需要反复点击"不喜欢"——系统终于能听懂你说"颜色不错但图案不喜欢",并据此调整推荐。
- 曝光品类多样性(EICD)提升0.88%,点击品类多样性(CICD)提升1.44%,有效缓解了信息茧房效应。你看到的推荐不再局限于历史点击,而是更丰富多元。
- 页面浏览量(PV)提升0.56%,加购率(ATC)提升1.28%,商品交易总额(GMV)提升1.40%,为企业带来可观的商业价值。

RecBot用户命令履行性能评估
尤为值得关注的是用户命令履行率。上表显示,RecBot实现了88.9%的命令履行成功率,通过人工评估和LLM-Judge双重验证,证明了系统能够准确理解和执行用户自然语言命令。LLM-Judge评估结果为87.5%,与人工评估的一致性达到96.5%,验证了自动化评估方法的可靠性。
用户群体细分效果分析
研究团队进一步分析了RecBot在不同用户群体中的表现。下图显示,系统在历史负向反馈频率为20-50的用户群体中效果最佳,NFF降低3.3%。这一发现表明,IRF范式特别适合那些有明确偏好但难以通过传统机制表达的用户。
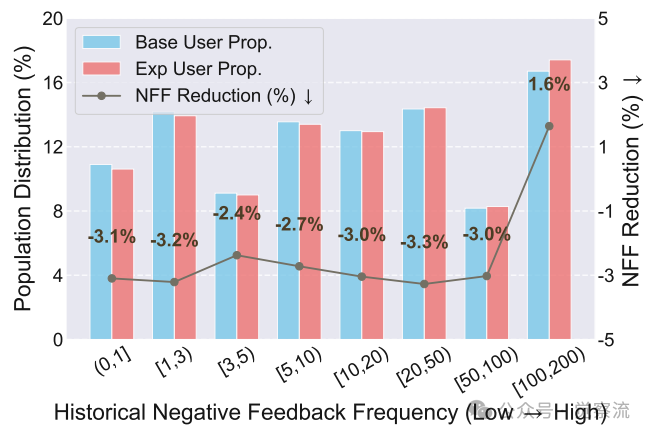
按历史负面反馈频率划分的用户群体性能改进
对于历史负向反馈频率较低的用户(0-4),系统仍能实现2.4%-2.7%的NFF降低,证明IRF对各类用户均有价值。然而,对于历史负向反馈频率极高(100-200)的用户群体,NFF反而上升1.6%。这一现象表明,这些高度不满的用户可能面临更深层次的问题,仅靠推荐算法改进难以解决,需要更全面的产品和算法设计。
实施细节与案例验证
多代理优化的轻量级部署

从模拟轨迹中提取的训练样本用于监督微调,优化Parser和Planner代理。统一的训练目标通过最小化目标序列的负对数似然实现,使模型能够处理多样化的推理模式,同时保持功能模块化与部署轻量化的平衡。
用户命令理解准确率保障
RecBot的命令理解能力通过严格评估得到验证。研究团队对约18万次在线交互实例进行了详细评估,采用人工专家标注和LLM-Judge双重方法。如

RecBot用户命令履行性能评估
所示,RecBot实现了88.9%的命令履行成功率,而LLM-Judge评估结果为87.5%,与人工评估的一致性达到96.5%。
这一高准确率证明了RecBot能够准确解析和响应用户自然语言命令。同时,LLM-Judge方法的高一致性验证了自动化评估的可靠性,为大规模商业部署提供了有效的监控手段。这种双重验证机制确保了系统在实际应用中的稳定性和可靠性。
生产环境案例解析
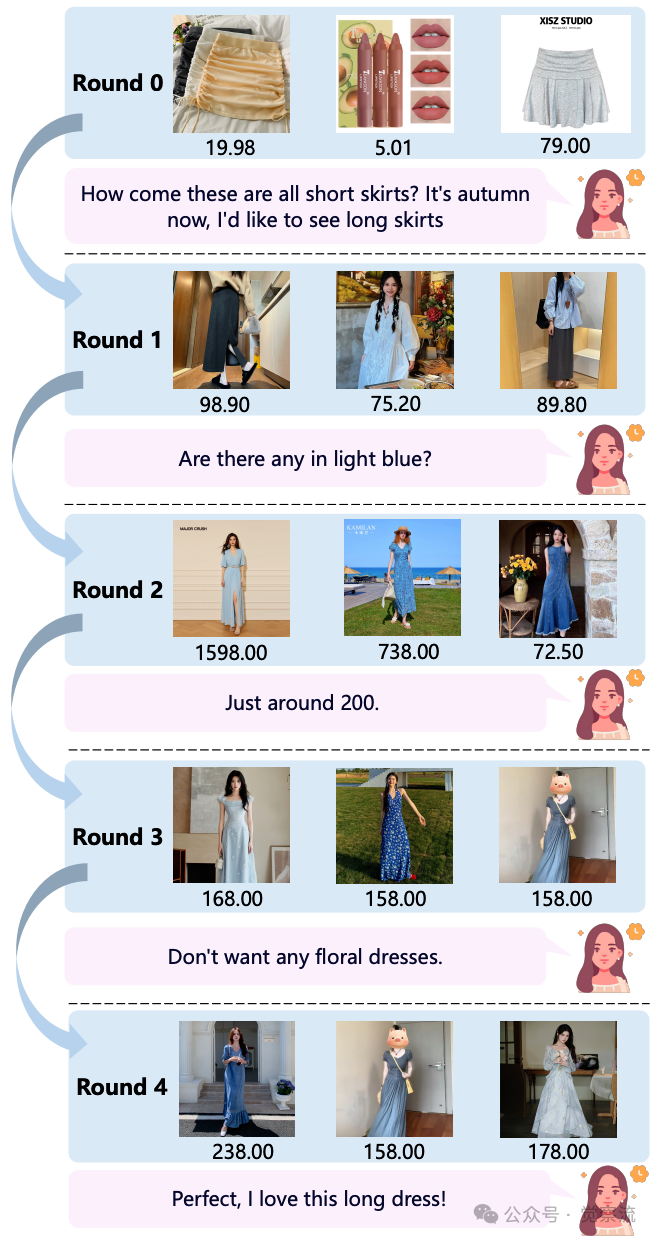
生产平台上RecBot的案例研究
上图展示了一个典型的多轮交互案例,生动说明了RecBot的工作流程:

这一案例展示了RecBot的核心能力:准确解析用户命令、有效整合多轮偏好、动态调整推荐策略。系统不仅满足了每个新要求,还保持了历史偏好的一致性,最终在四轮交互内达成用户满意,体现了自然语言命令在精准推荐中的巨大价值。
基于实证的研究方向
在线学习机制开发
研究团队明确指出,未来工作将"专注于开发通过在线用户反馈持续进化的在线学习机制"。当前RecBot主要基于预定义的交互模式工作,而未来系统将能够从实时用户反馈中不断学习和优化,实现更动态的适应能力。
这种在线学习机制将使系统能够捕捉用户偏好的细微变化,及时调整推荐策略。例如,当用户反复对某类商品表示不满时,系统能够自动识别并调整相关参数,而无需等待定期模型更新。这种持续进化能力将显著提升推荐系统的长期性能和用户满意度。
个性化推理能力增强
研究指出,未来将增强个性化推理能力,使系统能够更深入地理解用户意图。这包括开发更精细的意图解析模型,能够识别用户语言中的隐含需求和情感倾向;以及构建更丰富的用户画像,将短期交互与长期行为模式有机结合。
例如,系统可能识别出用户说"不要太贵的"实际上意味着"价格在200-300元之间",而非字面意义上的"低价"。这种深度理解能力将使推荐更加精准,减少用户反复调整的需要,提升整体交互效率。
智能交互式推荐系统演进
研究团队计划向更智能的交互式推荐系统发展,具备主动预测和解释能力。未来的系统不仅能响应用户命令,还能预判用户需求,提供解释性推荐。
例如,当用户搜索"适合秋季的长裙"时,系统可能主动建议"考虑到您之前喜欢的浅蓝色,这里有一些类似风格的秋季长裙",并解释推荐理由。这种主动性将使推荐系统从被动响应工具转变为智能购物助手,提供更自然、更人性化的交互体验。
交互式推荐生态重塑
IRF范式从根本上"重新思考人机关系",使用户能够"主动塑造内容消费体验"。这一转变不仅影响推荐算法,还将重塑整个推荐生态系统。用户控制权的提升将推动平台设计更加透明和可解释,算法决策过程将更加开放,用户能够理解并影响推荐结果。
这种以用户为中心的范式有望解决推荐系统长期面临的信任问题,建立更健康的人机协作关系。当用户感受到对推荐结果的控制权时,他们更可能信任系统并进行深度互动,形成良性循环。最终,这将推动推荐系统从"猜测用户意图"向"协同探索偏好"的范式转变,实现真正意义上的用户可控推荐。
基于在线测试中发现的"历史负向反馈频率100-200的用户群体NFF上升1.6%"现象(如下图所示),未来工作将特别关注高度不满用户的在线学习机制开发。这些用户可能面临更深层次的问题,需要系统从"响应命令"向"主动预测"演进,这正是论文结论部分指出的"向更智能的交互式推荐系统发展"的方向。
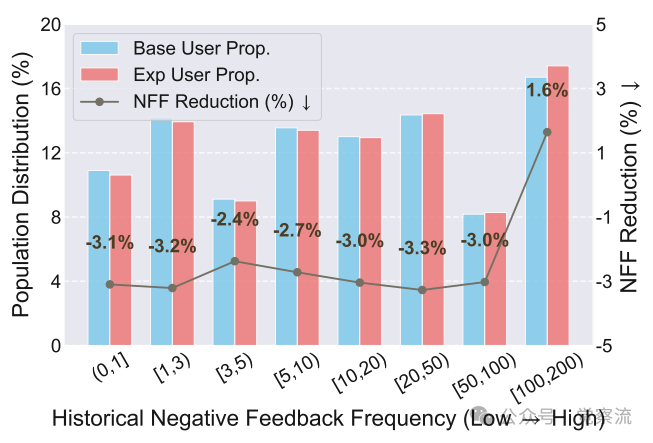
按历史负面反馈频率划分的用户群体性能改进
总结
推荐系统的发展经历了三个阶段:被动猜测(传统系统)→ 有限对话(CRS)→ 主动控制(IRF)。IRF不是简单的功能添加,而是人机关系的根本重构。下表显示,RecBot在"多轮交互"和"复杂用户命令"处理上全面领先,因为它真正理解用户说"浅蓝色不错,但不要花卉图案"时,既想保留颜色偏好又想排除特定样式。这种理解能力让推荐从"盲人摸象"变为"精准导航"。
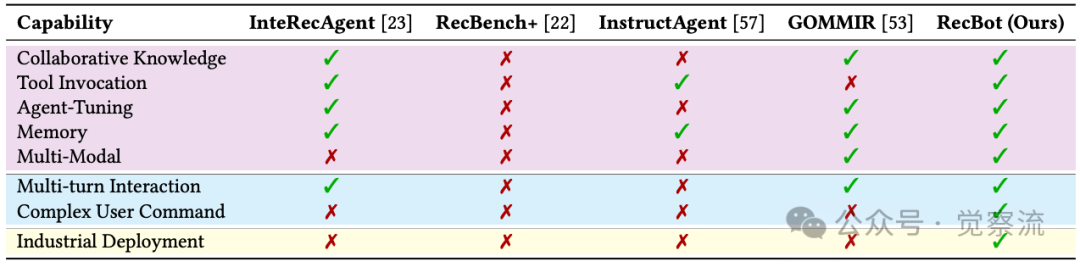
不同交互式推荐代理框架对比
在传统推荐系统中,用户平均需要5.8轮交互才能找到满意商品(下表);而使用RecBot,仅需4.38轮。这意味着什么?假设你每周网购3次,每次节省1.4轮交互,一年就是218轮——相当于少点击"不喜欢"按钮218次。这不是微小改进,而是用户体验的根本提升。
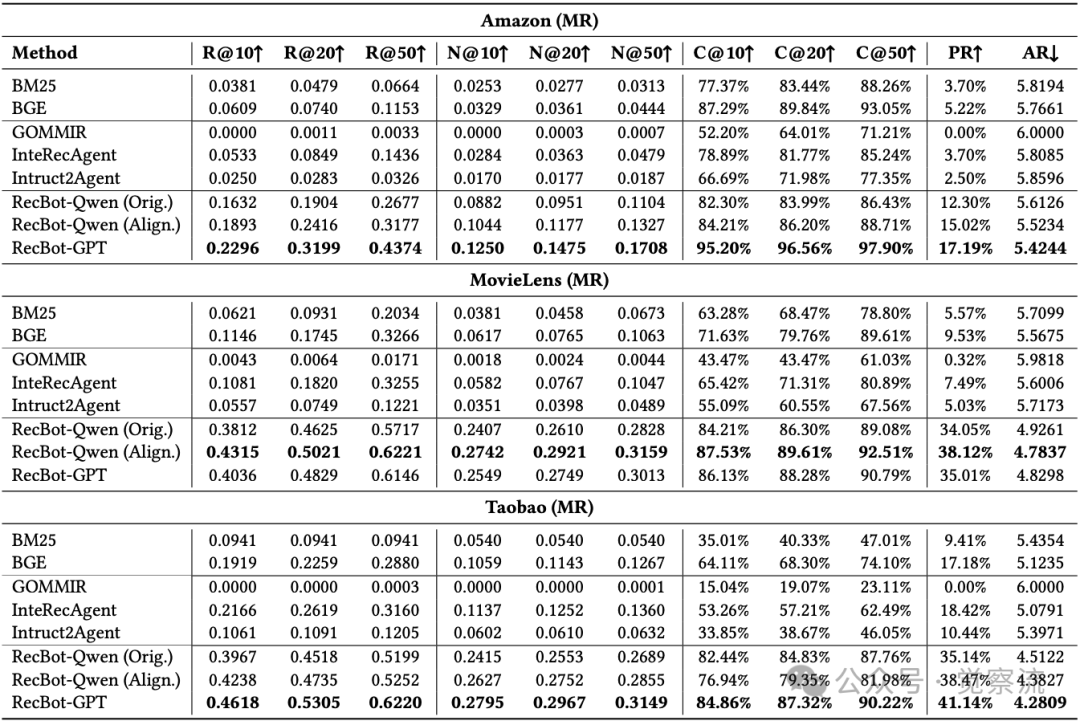
Multi-Round(MR)交互场景性能比较
IRF范式通过自然语言命令架起了沟通桥梁,使用户能够直接表达复杂偏好,系统则能精确响应这些指令。RecBot框架实现了这一理念,通过双代理架构、动态内存整合和推荐领域工具集,将语言命令转化为精准推荐行动。
实证研究表明,这一方法不仅在离线实验中显著优于现有方法,更在三个月线上测试中带来可量化的用户体验和商业价值提升。尤为关键的是,它赋予用户对推荐策略的直接控制权,实现了真正以用户为中心的推荐体验。
随着在线学习机制、个性化推理能力和主动预测能力的不断发展,交互式推荐系统将从被动响应工具演变为智能协作伙伴。这一转变不仅将解决推荐系统的精准度困境,更将重塑人机交互模式,为数字内容消费带来革命性变化。在信息过载的时代,让用户真正掌控推荐体验,或许正是构建更健康、更可持续数字生态的关键一步。


