近日,一款名为RAGFlow的开源RAG(检索增强生成)引擎引发了业界广泛关注。这款基于深度文档理解的企业级AI工具,以其强大的多模态数据处理能力和高效的工作流程,为企业处理复杂文档和实现精准问答提供了全新解决方案。
RAGFlow:深度文档理解的先锋
RAGFlow是一款完全开源的RAG引擎,专注于深度文档理解,旨在帮助企业和个人从海量非结构化数据中提取有价值的信息。不同于传统基于关键词的检索方式,RAGFlow结合大型语言模型(LLM)与先进的文档解析技术,支持从复杂格式的文档(如Word、Excel、PDF、图片、网页等)中提取知识,并提供带有明确引用的精准问答功能。
其核心优势在于“高质量输入,高质量输出”,通过智能模板分块和可视化文本处理,用户可直观干预数据处理过程,确保检索结果的准确性和可追溯性。RAGFlow的GitHub仓库已获得超过55,000颗星,显示出社区对其的高度认可。
核心功能:多模态与深度研究的完美结合
RAGFlow通过一系列创新功能,为企业级RAG工作流程树立了新标杆:
多模态数据支持:支持处理文本、图片、扫描件、结构化数据及网页等多种数据类型,适用于法律、医疗、金融等需要处理复杂文档的行业。
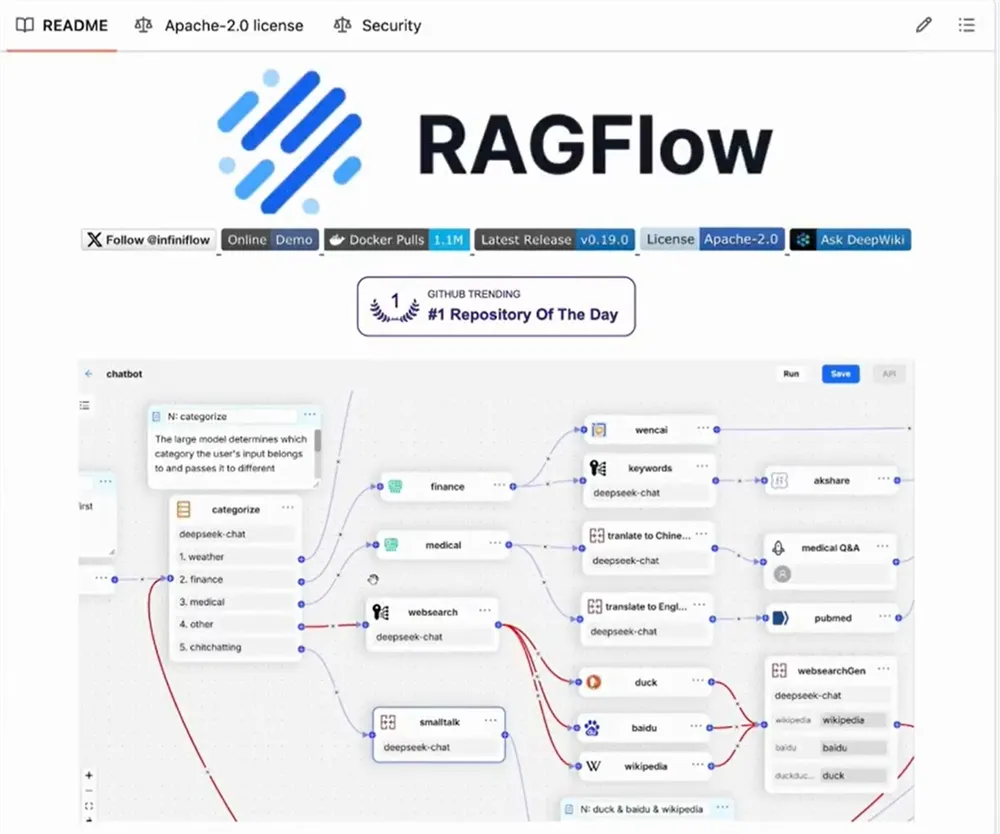
智能分块与可视化:提供多种模板化分块选项,并支持可视化文本分块,允许用户直观调整数据处理方式,减少AI幻觉(hallucination)。
网络搜索与深度研究:结合外部搜索工具(如Tavily),RAGFlow支持类似“深度研究”的推理能力,可为任意大型语言模型提供实时外部知识补充。
高效部署与集成:通过Docker提供轻量版(2GB)和完整版(9GB)镜像,支持CPU和GPU加速,并通过直观的API接口实现与企业系统的无缝整合。
知识图谱与SQL支持:支持知识图谱提取、关键词提取及文本转SQL功能,进一步提升数据检索和应用的灵活性。
技术亮点:企业级效率的保障
RAGFlow通过多项技术创新解决了传统RAG系统的局限性:
深度文档理解:利用高级文档布局分析模型(如DeepDoc),从复杂格式的非结构化数据中提取关键信息,堪称“数据海洋中的探针”。
多重召回与重排序:采用全文搜索与向量搜索结合的混合检索技术,并通过PageRank评分优化检索结果的准确性。
本地化部署:100%开源,支持本地部署,数据存储默认使用Elasticsearch,近期还新增了对Infinity存储引擎的支持(Linux/arm64除外),确保数据安全与隐私保护。
灵活配置:支持多种大型语言模型(如Deepseek-R1、DeepSeek-V3)及嵌入模型(如bce-embedding-base_v1),用户可根据需求自由选择。
应用场景:从个人到企业的全面赋能
RAGFlow的灵活性和强大功能使其在多个领域展现出广泛应用潜力:
企业知识管理:帮助企业从海量文档中快速提取关键信息,优化内部搜索和决策支持系统。
客户服务自动化:通过精准问答和引用支持,提升客户服务效率,减少人工干预。
学术与法律研究:支持复杂文档的深度解析和知识图谱构建,助力研究人员快速定位关键信息。
多模态内容处理:在医疗、金融等领域,RAGFlow可处理扫描件、图片等非文本数据,拓展了AI的应用边界。
挑战与未来:RAG2.0的进化之路
尽管RAGFlow在技术上取得了显著突破,其仍需面对一些挑战。例如,多模态数据处理对硬件要求较高,可能增加中小企业的部署成本。此外,如何进一步优化知识图谱的提取效率和模型的幻觉抑制能力,也是未来发展的关键方向。
AIbase分析认为,RAGFlow代表了RAG技术向“2.0时代”的迈进。其开源特性降低了技术门槛,使中小型企业和开发者能够快速定制AI解决方案。未来,随着社区贡献的增加和功能的持续迭代,RAGFlow有望成为企业AI工作流程的标配工具。
社区与生态:开源力量的崛起
作为一款100%开源的项目,RAGFlow通过GitHub平台吸引了全球开发者的广泛参与。其官方Demo(demo.ragflow.io)已开放试用,展示了对复杂文档的处理能力。近期更新包括支持本地LLM部署(如Ollama、Xinference)、代码执行组件以及法律文档专用的布局识别模型,显示出其快速迭代的活力。
结语
RAGFlow以其深度文档理解、多模态支持和开源优势,正在重新定义企业级RAG工作流程的未来。从智能问答到深度研究,这款引擎为企业和开发者提供了高效、可靠的AI解决方案。
项目地址:https://github.com/infiniflow/ragflow


