
大语言模型具有显著的能力,但它们常常因为仅依赖于其参数化知识而产生包含事实错误的响应。传统的检索增强生成(Retrieval-Augmented Generation, RAG)方法虽然能减少这些问题,但是存在无差别地检索和结合固定数量的段落,没有考虑检索是否必要或检索结果的相关性,都会削弱语言模型的灵活性,或者导致无益的响应生成。
现在LLM+RAG(检索增强)的技术方案已成为LLM在众多应用场景的主流。在LLM+RAG技术框架下,存在的问题/技术难点主要有:
1)如何保证检索内容是有效,或有用的?
2)如何验证检索的内容对输出的结果是支持的?
3)如何验证输出的结果是来自检索还是模型的生成?
今天来看一篇华盛顿大学和艾伦AI Lab发表在2024 ICLR上的工作,提出Self-RAG,使单一的语言模型能够根据需求自适应地检索段落,并使用特殊的反思Token(reflection tokens)来生成和反思检索到的段落及自身生成的内容。
下面来详细看下Self-RAG是如何解决这些问题的:
1、方法介绍
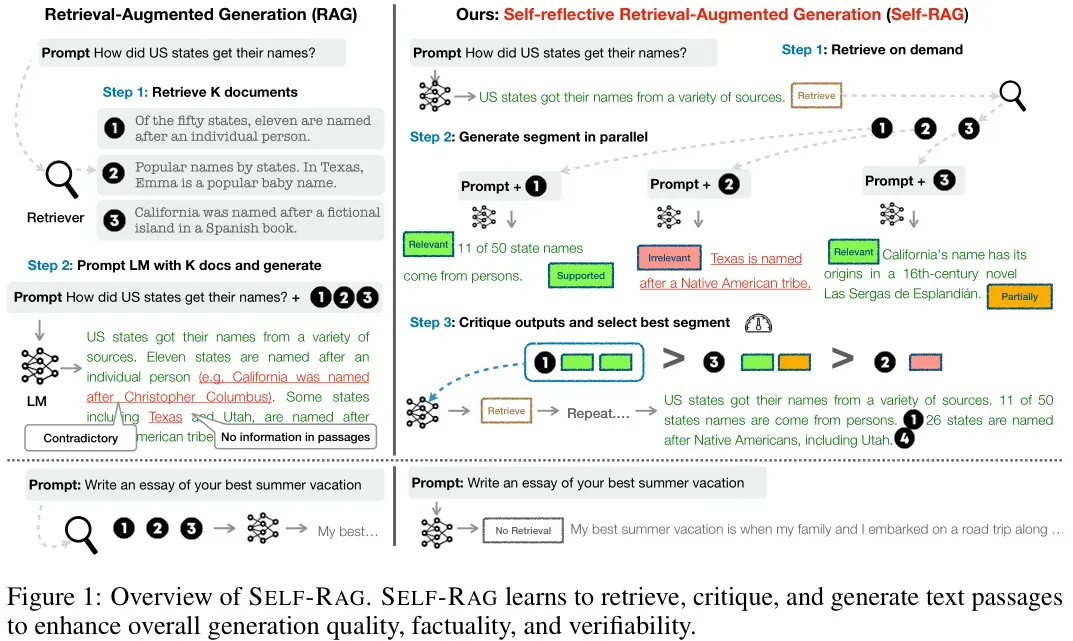
从Figure 1可以看出Self-RAG和Vanilla RAG的区别,
传统RAG方法的工作流程通常包括:
- Step 1: 检索K个文档:无论是否有必要,都会从大型文档集合中无差别地检索出固定数量的相关段落。
- Step 2: 生成输出:根据检索到的段落和原始任务输入,生成响应文本。这种方法可能无法确保所有生成的内容都得到了检索段落的支持。
相比之下,SELF-RAG方法引入了一个更灵活且智能的流程:
- Step 1: 决定是否检索:给定一个输入提示和先前的生成,SELF-RAG首先判断继续生成时是否需要通过检索来增强信息。如果确定需要检索,它会输出一个检索Token(retrieval token),该Token会按需调用检索模型。
- Step 2: 并行处理多个检索段落:当接收到检索Token后,SELF-RAG并行处理多个检索到的段落,评估它们的相关性,并基于这些段落生成相应的任务输出。
- Step 3: 自我评价与选择最佳片段:SELF-RAG接着生成评价Token(critique tokens),用于评价自身生成的输出,并从中挑选出最符合事实性和整体质量的输出。
简单来说,对比RAG,self-RAG框架的不同之处就是:在生成过程中利用特殊的token达到更精细的控制——要不要检索、检索内容相关性怎样、利用检索内容生成的质量怎样。达到这些目的,就会让RAG+LLM生成的内容在质量、事实性、验证性上得到提升。
下面来详细看下怎么利用特殊Token实现Self-RAG:
问题概述
给定一个输入x,训练目标是让模型M顺序生成由多个片段组成的文本输出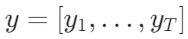 ,其中
,其中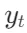 代表第t个片段的一系列Token。每个片段可以是一个句子或者更小的文本单位,这取决于具体的实现。生成的Token不仅包含来自原始词汇表中的文本,还可能包含特殊的反思Token(reflection tokens),这些Token用于指示是否需要进行检索,或者确认输出的相关性、支持性或完整性。
代表第t个片段的一系列Token。每个片段可以是一个句子或者更小的文本单位,这取决于具体的实现。生成的Token不仅包含来自原始词汇表中的文本,还可能包含特殊的反思Token(reflection tokens),这些Token用于指示是否需要进行检索,或者确认输出的相关性、支持性或完整性。

对于每一个输入x及其之前生成的内容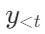 ,模型首先解码一个检索Token来评估检索的必要性。如果不需要检索,模型会像标准的语言模型一样预测下一个输出片段。如果确定需要检索,那么模型将:
,模型首先解码一个检索Token来评估检索的必要性。如果不需要检索,模型会像标准的语言模型一样预测下一个输出片段。如果确定需要检索,那么模型将:
- 生成评价Token以评估相关性:模型生成一个评价Token来评价检索到的段落是否与任务相关。
- 生成下一个响应片段:根据检索到的信息生成接下来的响应部分。
- 生成评价Token以评估支持度:评价新生成的响应片段是否得到了检索到的段落的支持。
- 生成评价Token以评估整体效用:最后生成一个新的评价Token,对整个响应的总体效用进行评价。
在生成每个片段的过程中,SELF-RAG并行处理多个检索到的段落,并使用其自身生成的反思Token来施加软约束或硬控制。例如,在决定是否插入某个段落时,模型会考虑该段落的相关性和支持程度。如果存在多个满足条件的段落,则选择具有最高检索分数的那个。

训练概述
SELF-RAG通过将反思Token统一为从扩展模型词汇表中预测的下一个Token,训练一个任意的语言模型生成带有反思Token的文本。
具体来说,使用由检索器R检索的段落和由评价模型C预测的反思Token交织在一起的精选语料库训练生成器模型M。使用评价模型,通过将反思Token插入任务输出中来更新训练语料库。然后,使用传统的语言模型目标训练最终的生成器模型M,使其能够在推理时不依赖评价模型自行生成反思Token。
训练
在训练过程中,需要两个模型:一个评价模型C,一个生成模型M;利用评价模型C来生成M模型所需的监督数据,在推理过程中只依赖M模型,不用C模型。

训练评价模型(Critic Model)
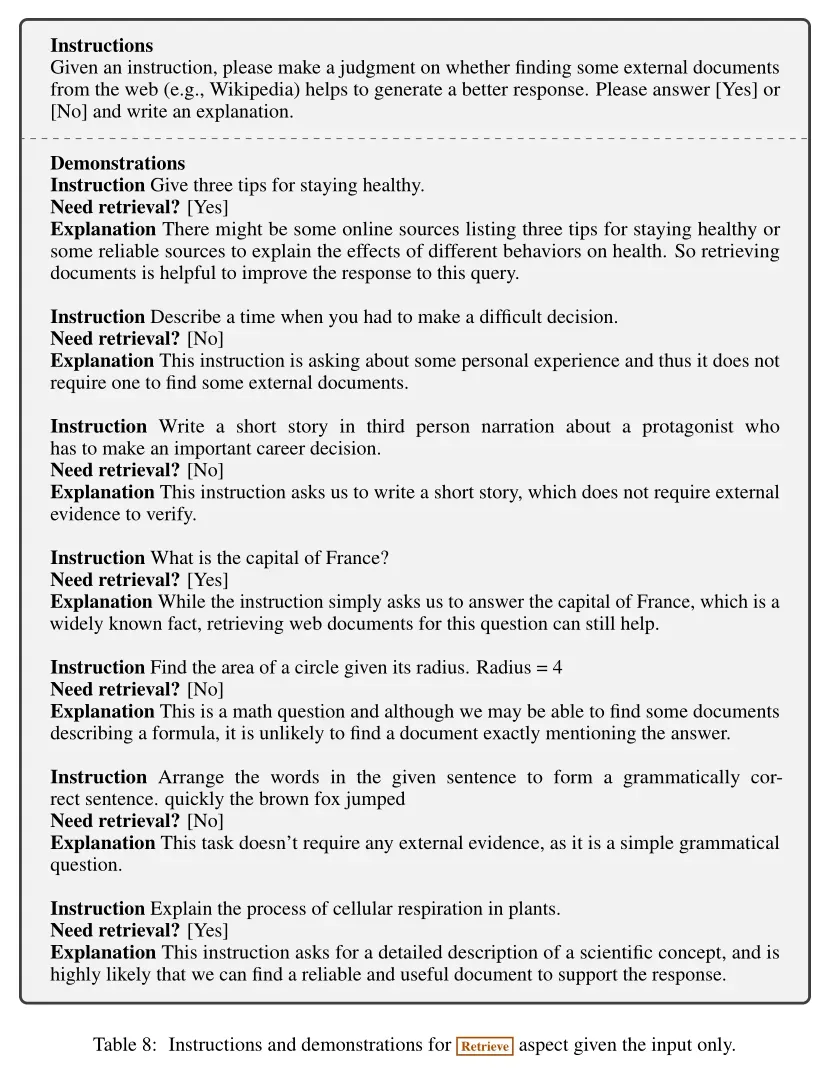
- 数据收集:手动为每个段落标注反思Token成本很高,因此研究人员采用GPT-4来生成这些反馈。通过向GPT-4发出指令提示,使其为特定的任务输入-输出对预测适当的反思Token,从而创建监督数据。这种方法需要对多个检索到的段落以及任务输入-输出实例进行细粒度评估,以生成用于训练SELF-RAG的数据,并将这些知识蒸馏到一个内部的评价模型C中。对于每组反思Token,从原始训练数据中随机采样实例
 。然后使用不同的指令提示(表1)来生成不同类型的反思Token(如Retrieve、ISREL、ISSUP、ISUSE)。例如,对于Retrieve Token,使用原始任务输入x和输出y的少量示例提示GPT-4判断是否需要从外部文档中获取信息以生成更好的响应
。然后使用不同的指令提示(表1)来生成不同类型的反思Token(如Retrieve、ISREL、ISSUP、ISUSE)。例如,对于Retrieve Token,使用原始任务输入x和输出y的少量示例提示GPT-4判断是否需要从外部文档中获取信息以生成更好的响应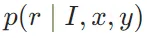 。收集4k到20k的监督训练数据用于每种类型的反思Token,并将它们组合成C的训练数据。
。收集4k到20k的监督训练数据用于每种类型的反思Token,并将它们组合成C的训练数据。
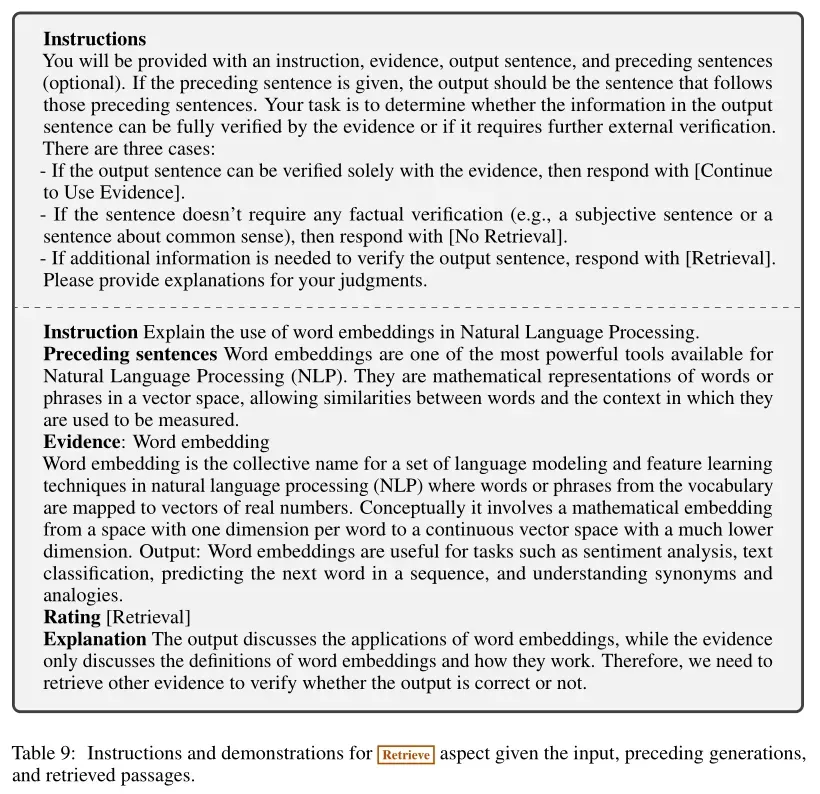
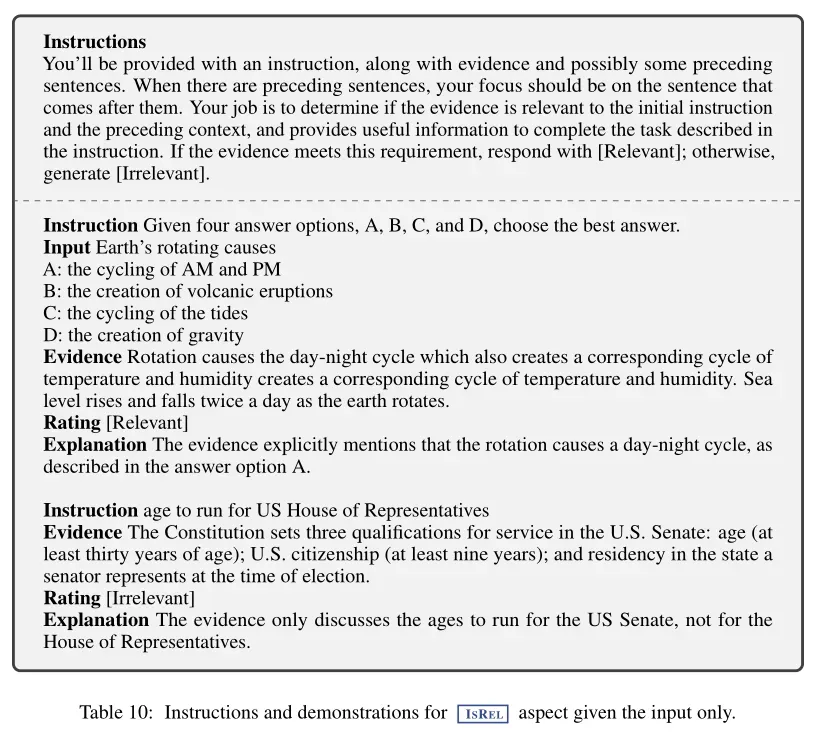
- 评价模型学习:在收集到的训练数据上,使用预训练的语言模型初始化C,并进行训练。最大化似然:
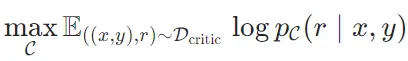 其中r是反思Token。使用与生成器模型相同的预训练语言模型(Llama 2-7B)来初始化C。训练后评价模型的表现如下:
其中r是反思Token。使用与生成器模型相同的预训练语言模型(Llama 2-7B)来初始化C。训练后评价模型的表现如下:
训练生成器模型(Generator Model)
- 数据收集:给定输入-输出对,运行 C评估是否需要额外的段落来增强生成。如果需要检索,添加检索特殊Token Retrieve=Yes,并使用R检索顶部K个段落D。对于每个段落,C 进一步评估段落的相关性并预测 ISREL。如果段落相关,C 进一步评估段落是否支持模型生成并预测 ISSUP。在输出的末尾,C 预测整体效用Token ISUSE,并将带有反思Token的增强输出和原始输入对添加到
 中。
中。


- 生成器模型学习:在增强的语料库
 上,使用标准的下一个Token目标训练生成器模型 M进行训练:
上,使用标准的下一个Token目标训练生成器模型 M进行训练: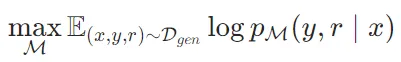 与C的训练不同,M 学习预测目标输出以及反思Token。在训练期间,对于损失计算,屏蔽检索的文本块,并将原始词汇表 V 扩展为一组反思Token {Critique,Retrieve}。
与C的训练不同,M 学习预测目标输出以及反思Token。在训练期间,对于损失计算,屏蔽检索的文本块,并将原始词汇表 V 扩展为一组反思Token {Critique,Retrieve}。
以上就是训练的过程,其核心就是生成模型M的训练,而M模型的不同之处在于,在生成文本序列的同时,还会辅助生成多种标签信息,以达到更细粒度的检索控制能力。
推理
生成反思Token以自我评估其输出使得Self-RAG在推理阶段可控,使其能够根据不同的任务需求调整其行为。对于需要事实准确性的任务,希望模型更频繁地检索段落,以确保输出与可用证据紧密一致。相反,在更开放的任务中,如撰写个人经历的文章,重点则转向减少检索并优先考虑整体创造力或效用评分。
主要思路:1)在自回归方式生成过程中,若生成有[Retrieve]标签,且值为yes时,便使用检索器(检索模型)R召回d个相关片段;2)接着训练利用召回的相关片段去预测是否相关[IsREL]标签,以及评价标签[IsSUP]和[IsUSE]标签,跟进这些标签对生成的序列进行排序,选top1的结果作为最终生成结果;3)若生成有[Retrieve]==NO时,就直接利用x生成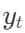 。
。
具体实现如下:
自适应检索(Adaptive Retrieval)
动态检索决策:SELF-RAG在推理过程中动态决定是否需要检索文本段落。这是通过预测“Retrieve”Token来实现的。如果模型预测“Retrieve = Yes”,则触发检索过程。否则,模型将继续生成文本,而不进行检索。为了更灵活地控制检索频率,作者引入了一个阈值机制。如果生成“Retrieve = Yes”Token的概率超过指定的阈值,则触发检索。这种机制允许在不同任务中灵活调整检索频率,以适应不同的任务需求。
基于评价Token的树解码(Tree-decoding with Critique Tokens)
- 并行处理和候选生成:当需要检索时,SELF-RAG会并行处理多个检索到的段落,并为每个段落生成不同的候选续写。具体来说,对于每个输入x 和之前的生成
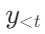 ,模型会预测是否需要检索。如果需要检索,模型会检索K个相关段落D,并为每个段落生成一个候选续写。这些候选续写会通过段落级别的束搜索(beam search=B)进行评估和选择,并在生成结束时返回最佳序列。
,模型会预测是否需要检索。如果需要检索,模型会检索K个相关段落D,并为每个段落生成一个候选续写。这些候选续写会通过段落级别的束搜索(beam search=B)进行评估和选择,并在生成结束时返回最佳序列。 - 评价Token的评分机制:每个候选续写
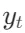 的评分由两部分组成:生成概率和评价分数。生成概率
的评分由两部分组成:生成概率和评价分数。生成概率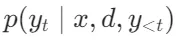 表示在给定输入x、段落d 和之前的生成
表示在给定输入x、段落d 和之前的生成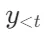 的情况下,生成
的情况下,生成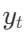 的概率。评价分数S(Critique) 是评价Token的加权线性组合。具体来说,对于每种评价Token类型G(如 ISREL、ISSUP、ISUSE),计算其在时间戳t的评分
的概率。评价分数S(Critique) 是评价Token的加权线性组合。具体来说,对于每种评价Token类型G(如 ISREL、ISSUP、ISUSE),计算其在时间戳t的评分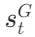 ,然后使用加权和来计算段落的总评分:
,然后使用加权和来计算段落的总评分: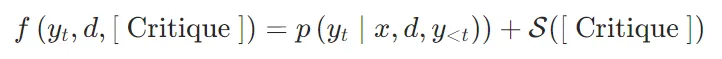 其中,
其中,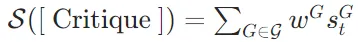 ,
,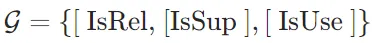 ,
,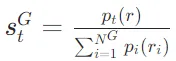 表示评价Token类型G 的最理想反思Token
表示评价Token类型G 的最理想反思Token 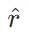 (例如,[IsRel]=Relevant)的生成概率,
(例如,[IsRel]=Relevant)的生成概率,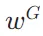 是在推理时调整的超参数,以在测试时实现自定义行为。
是在推理时调整的超参数,以在测试时实现自定义行为。
推理过程的灵活性和定制性
- 任务需求的适应性:SELF-RAG通过生成反思Token,能够在推理阶段自我评估其输出的质量,并根据任务需求调整其行为。在需要高事实准确性的任务中,模型会更频繁地进行检索,以确保输出与可用证据紧密对齐。在更开放的任务中,如创作个人经历作文,模型会减少检索频率,优先考虑整体的创造力或效用得分。
- 推理时的定制化:通过调整评价Token的权重,可以在推理时对模型的行为进行定制,而无需额外的训练。例如,可以通过增加 ISSUP的权重来确保输出主要由证据支持,同时相对降低其他方面的权重。
2、实验结果
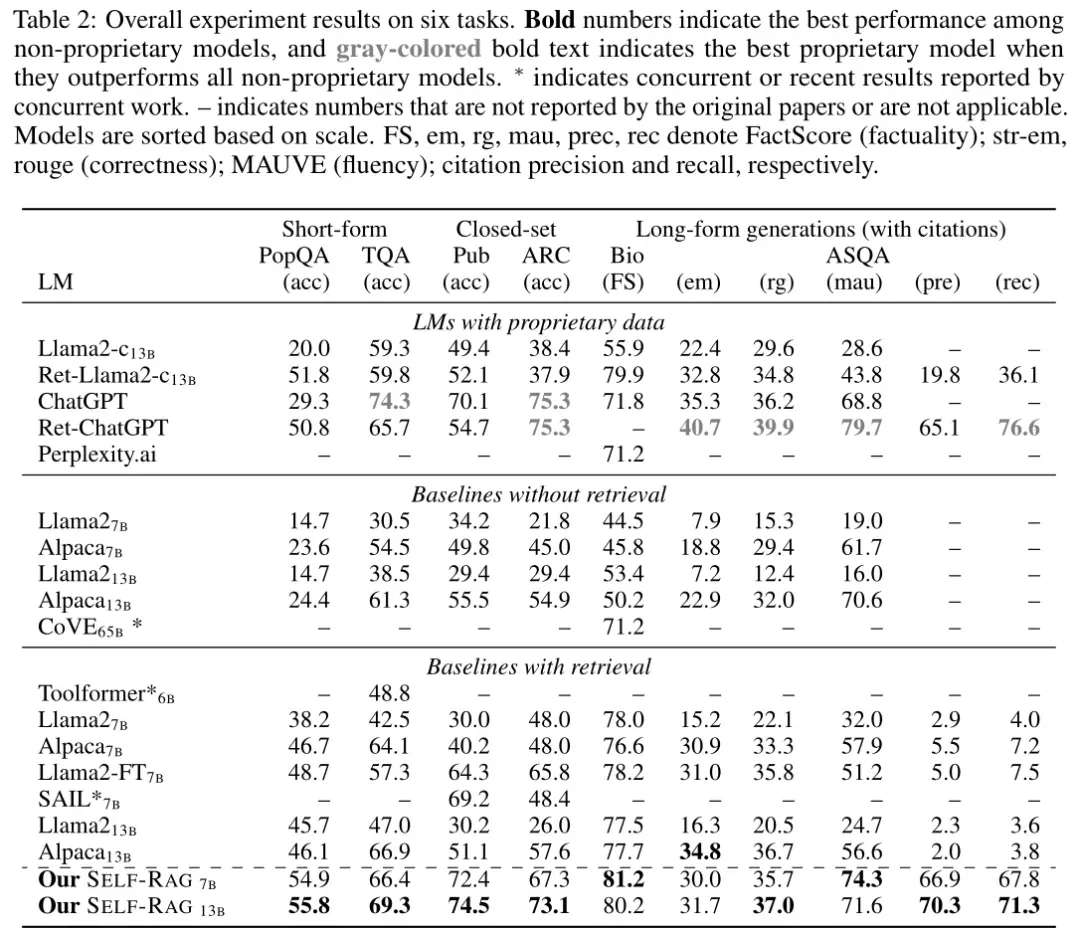
无检索的基线模型比较
Baseline:公开可用的预训练模型(如Llama2-7B、Alpaca7B和Alpaca13B),以及使用私有数据训练和强化的模型(如ChatGPT和Llama2-chat)。还包括CoVE65B,这是一种同时引入迭代提示工程来提高生成事实性的方法。
SELF-RAG在所有任务中均显著优于没有检索的基线模型,包括监督微调的大型语言模型(LLMs)。在公共健康(PubHealth)、开放域问答(PopQA)、传记生成和长文本问答(ASQA)任务中,SELF-RAG甚至超过了ChatGPT。与使用复杂提示工程的CoVE方法相比,SELF-RAG在生物传记生成任务中表现更好。
带检索的基线模型比较
Baseline:
- 标准RAG基线:基于Llama2或Alpaca的语言模型,在生成输出时会将检索到的文档附加到查询之前。
- 微调后的Llama2(Llama2-FT):在所有训练数据上进行了微调,不包含反思Token或检索到的段落。
- 私有数据检索增强的模型:如Ret-ChatGPT和Ret-Llama2-chat,以及perplexity.ai,它们部署了类似的增强技术。
- 并行方法:如SAIL和Toolformer,这些方法分别在指令调整期间插入检索到的文档或预先训练带有API调用的语言模型。
SELF-RAG在许多任务中也优于现有的检索增强模型(RAG),在所有任务中均获得了非专有语言模型基础模型中的最佳性能。尽管指令调优的LLMs(如Llama2-chat和Alpaca)在检索后有显著提升,但在需要复杂推理或生成的任务中,这些基线模型的表现并不如SELF-RAG。在引用准确性方面,大多数带检索的基线模型表现不佳,而SELF-RAG在ASQA任务中显示出显著更高的引用精度和召回率。
消融研究(Ablation Studies)
研究人员构建了几个SELF-RAG的变体以识别哪些因素发挥了重要作用:
- No Retriever:该变体仅使用标准指令跟随方法训练语言模型,不利用检索到的段落。
- No Critic:这个变体总是用最上面的一个检索文档来增强输入输出对,但没有反思Token,类似于SAIL的方法,不过这里使用的是自己的指令输出数据而不是Alpaca数据集。
- No Retrieval:推理时禁用检索功能。
- Hard Constraints:当且仅当检索Token为“是”时才进行检索,而不是采用自适应阈值。
- Retrieve Top 1:始终检索并使用最上面的一个文档,类似于传统的RAG方法。
- Remove ISSUP:在批判导向的束搜索过程中移除ISSUP评分。
与没有检索器或评价器的模型相比,SELF-RAG在所有任务中表现出显著的性能提升,表明这些组件对性能的贡献很大。
使用Top段落而不考虑其相关性(如标准RAG方法)会导致性能大幅下降,而仅依赖相关性分数也不足以提高性能。
检索机制:检索机制显著提升了模型在需要外部信息的任务上的表现,特别是在事实验证和引用准确性方面。
自我评价机制:反思Token(如ISREL, ISSUP, ISUSE)有助于提高输出的相关性和支持度,从而改善模型的整体效用。
自适应阈值:相较于固定规则,自适应阈值使得模型能够在适当的时候动态决定是否检索,提高了灵活性和效率。
这些结果表明,SELF-RAG通过仔细选择生成内容并基于多个细粒度标准进行评估,而不是简单地使用检索模型的所有段落或仅依赖相关性分数,从而提高了生成质量。
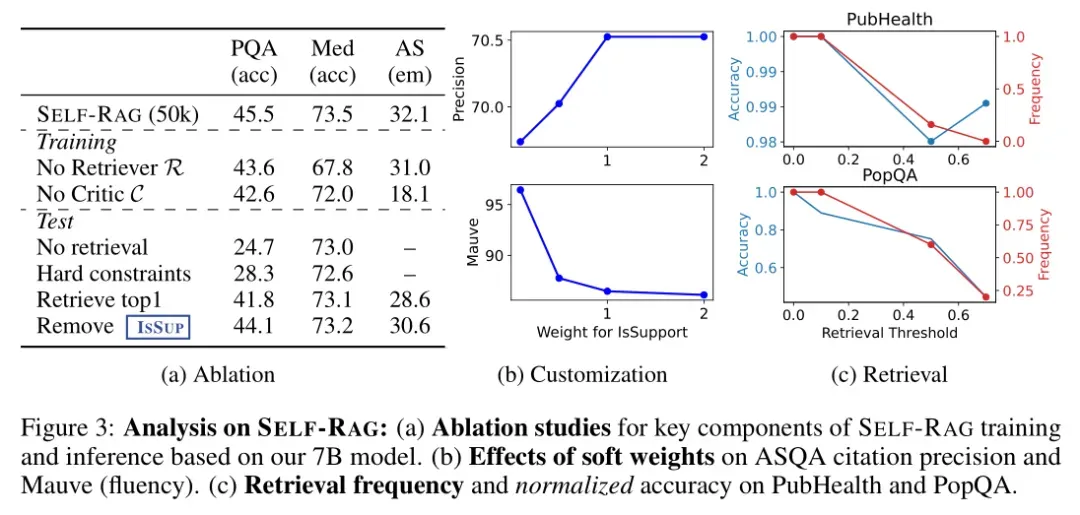
推理时定制化的效果
SELF-RAG的一个关键优势是能够在推理时控制每种评价类型对最终生成采样的影响(图3 b)。例如,在ASQA任务中,通过增加ISSUP的权重,可以提高模型的引用精度,因为这强调了模型生成是否由证据支持。然而,较大的权重会导致MAUVE分数降低,因为生成的文本更长、更流畅时,常常会有更多未被引用完全支持的主张。这种框架允许实践者在测试时通过调整这些参数来选择和定制模型的行为,而无需额外的训练。
检索频率和归一化准确率
随着检索阈值的变化,模型在不同任务上的检索频率和准确率也有所不同。较低的阈值可能会增加不必要的检索次数,而较高的阈值则可能导致错过重要的外部信息。因此,找到一个合适的阈值对于平衡这两者至关重要。作者评估了这种适应性阈值对整体准确性和检索频率的影响,并在PubHealth和PopQA数据集上进行了测试。结果表明,模型的检索频率随着阈值的变化而显著变化。在PubHealth上,检索较少导致的性能下降较小,而在PopQA上则较大。
3、总结
Self-RAG框架给LLM+检索增强任务提供了一种新的结合方式——在生成过程中加入可以多维、更细粒度的控制与评价标签,让LLM对检索的内容的利用,以及利用效果有了更直接的操作。
其有个缺陷时,在生成的时候要多次生成和判断标签,这会增加推理成本。此外,在此框架下,还是有很多优化空间,1)比如标签的优化(用更少的标签,或者代表其他含义的标签);2)在召回相关文档后,用一个小模型来判断,选择top1作为最终结果,减少循环计算。
该方法目前也没有找到落地方案,并且回答可能会很慢,还是有很大优化空间。


