近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
无独有偶,同期西安交通大学与微软亚洲研究院提出了「VFM-VAE」。二者均基于冻结的预训练视觉模型构建语义潜空间,而 VFM-VAE 在结构上可视为 RAE 与 VAE 的结合:结合 VAE 的概率建模机制,将高维预训练模型特征压缩为低维潜空间表示,系统性地研究了在压缩条件下预训练视觉表征对 LDM 系统表征结构与生成性能的影响。
VFM-VAE 通过直接集成冻结的基础视觉模型作为 Tokenizer,能够显著加速模型收敛并提升生成质量,展示了 LDM Tokenizer 从像素压缩迈向语义表征的演化方向。
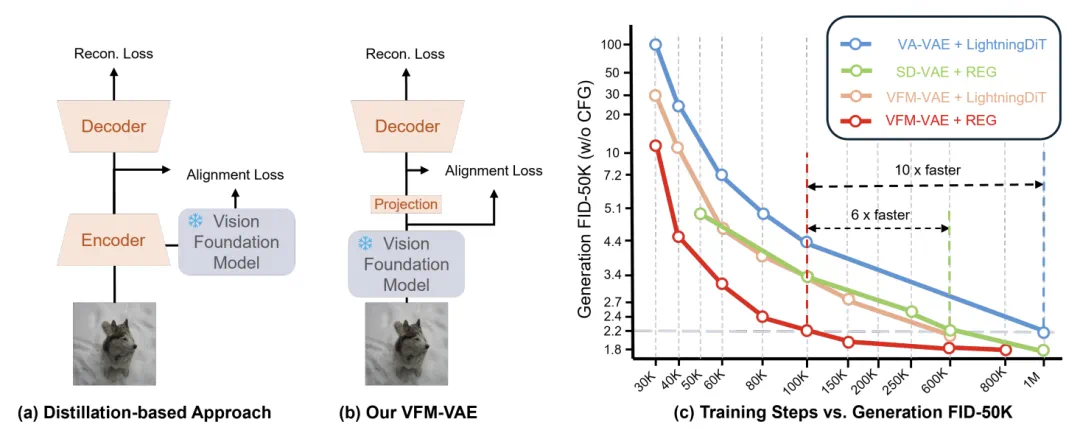
图 1:左:VFM-VAE 设计示意图。右:ImageNet 256×256 上生成性能比较。

论文链接:https://www.arxiv.org/abs/2510.18457
Github 链接:https://github.com/tianciB/VFM-VAE
预训练视觉特征替代潜空间的探索
近年来,扩散模型和多模态生成系统在图像理解与合成领域持续取得突破,但其性能上限日益受限于视觉分词器的表达能力。
传统的蒸馏式方法重新训练 VAE 并对齐基础视觉模型的特征分布,虽取得了一定成果(如 VA-VAE),但由于是在有限的数据集上的蒸馏,其在旋转、缩放或轻噪声等语义保持扰动下容易失稳,导致潜空间表示偏移、系统稳健性下降。
为系统分析这一现象,研究团队提出了 SE-CKNNA 指标,用于量化潜空间与基础视觉模型特征之间的一致性,并评估这种一致性对后续生成性能的影响。
实验表明,蒸馏式分词器在扰动下的语义对齐易退化,而保持潜空间与基础视觉模型特征的高度一致,对生成模型的稳健性和收敛效率至关重要。
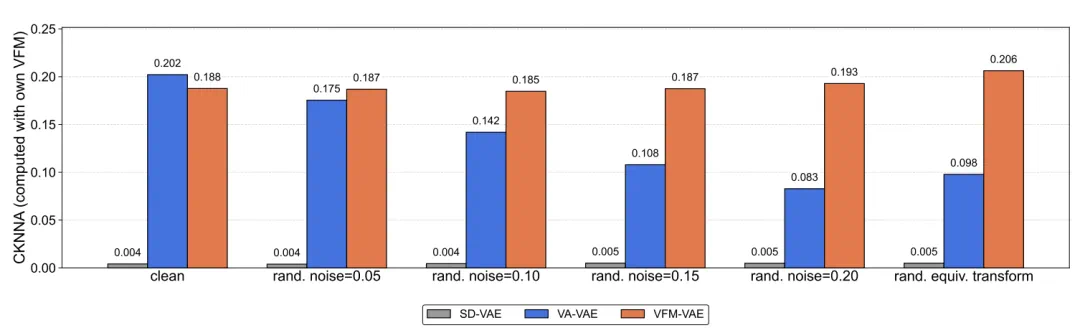
图 2:不同 Tokenizer 在语义保持扰动下与各自视觉基础模型对齐的情况。

表 1:不同 Tokenizer 与视觉基础模型的对齐质量,以及对应的重建、生成能力对比。CKNNA* 是与 DINOv2-Giant 统一计算;其余 CKNNA 是与各自的视觉基础模型计算,SD-VAE 默认与 DINOv2-Large 计算。
如何从冻结的基础视觉模型特征中压缩语义,并进行像素重建?
「直连」虽然避免了蒸馏带来的信息损失,但基础视觉模型的高层特征虽具强语义表达,却缺乏精确的空间结构信息,直接用于重建往往导致细节模糊。为此,研究团队设计了一个兼顾语义压缩与像素还原的两阶段解码框架。
首先,编码侧通过冻结的基础视觉模型提取多层语义特征,并利用轻量的投影模块将不同层级的特征映射到潜空间 z。
接着,解码器部分采用「多尺度潜特征融合」结构:将 z 分为语义分支和空间分支,前者在各层提供全局风格与语义控制,后者在低分辨率阶段注入以确定布局与主体形状。
在具体实现上,VFM-VAE 使用调制式卷积块(modulated convolution block)与层级式 ToRGB 输出,使模型能够在 8×8 → 256×256 的金字塔结构中逐级恢复细节。训练目标联合 L1、LPIPS、KL 与对抗性损失,并引入基于视觉基础模型特征的表征正则,在有效防止模糊重建的同时,确保潜空间特征可被下游生成模型稳定利用。
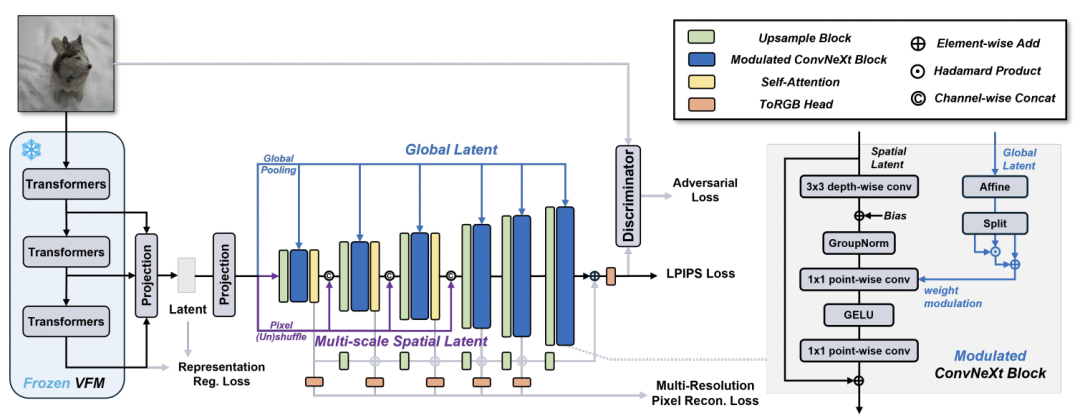
图 3:VFM-VAE 的总体框架。
潜空间与预训练视觉表征的一致性如何影响生成性能?
研究团队进一步分析了潜空间表征在扩散模型内部的层间一致性,发现 VFM-VAE 在层间平均和峰值 CKNNA 得分均高于蒸馏式分词器,表明其潜空间能更稳定地对齐基础视觉模型特征。然而,浅层语义对齐相对较弱。
为此,团队在生成模型的浅层引入与基础视觉模型特征的显式对齐机制,使 LDM 的潜空间在生成过程中始终保持与基础视觉模型特征的高度一致,从而进一步提升了语义传递的稳定性与生成质量。
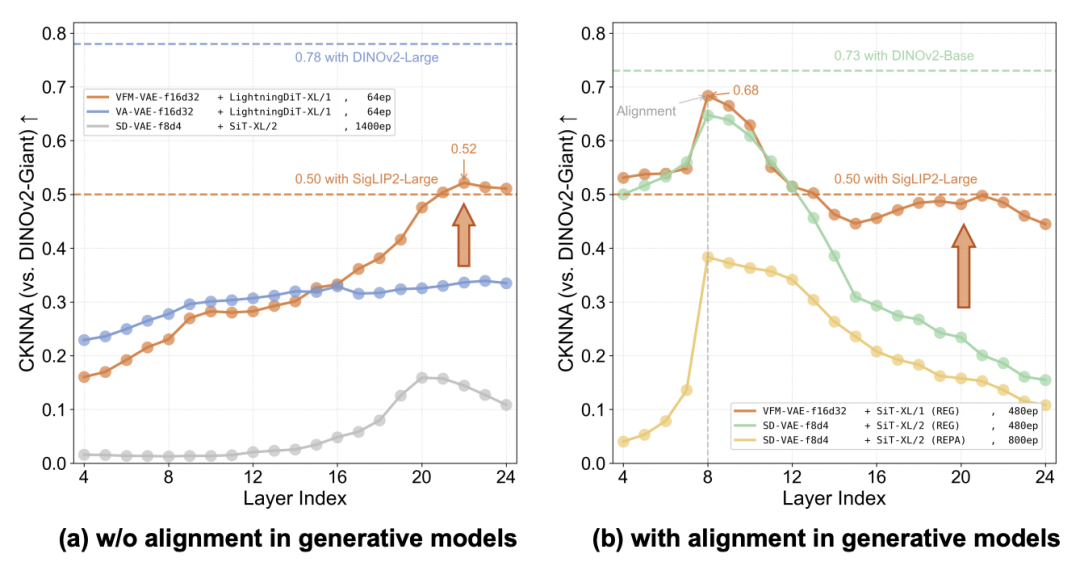
图 4:左侧展示了不同分词器结合生成模型时,在未引入显式对齐机制下各层特征与基础视觉模型特征的对齐情况;右侧对比了结合显式对齐的 VFM-VAE 与仅采用显式对齐的生成模型在层间特征与基础视觉模型特征对齐上的差异。
更高质量与更快收敛:VFM-VAE 迈向可稳健对齐的生成系统
在实验中,VFM-VAE 展现出显著的性能优势与训练效率。在 ImageNet 256×256 上,该方法在相同训练阶段实现 gFID 3.80 (without CFG),优于蒸馏路线的 5.14。当与显式对齐机制结合后,仅用 80 epochs 即可达到 gFID 2.22 (without CFG),训练效率较蒸馏式 Tokenizer 系统提升约 10 倍。
研究团队还将 VFM-VAE 与多模态语言模型 BLIP3-o 结合,验证其在文生图任务中的语义一致性与生成潜力。经过 1 epoch 预训练,VFM-VAE + BLIP3-o 在 DPG-Bench 上得分 59.1,较 VA-VAE 提升明显;在 MJHQ-30K 上 gFID 降至 16.98(蒸馏路线为 23.00)。
这些结果表明,VFM-VAE 不仅在潜空间扩散阶段表现出稳健语义对齐,也能在跨模态生成中有效传递这种一致性,形成从「视觉理解」到「图像生成」的闭环。
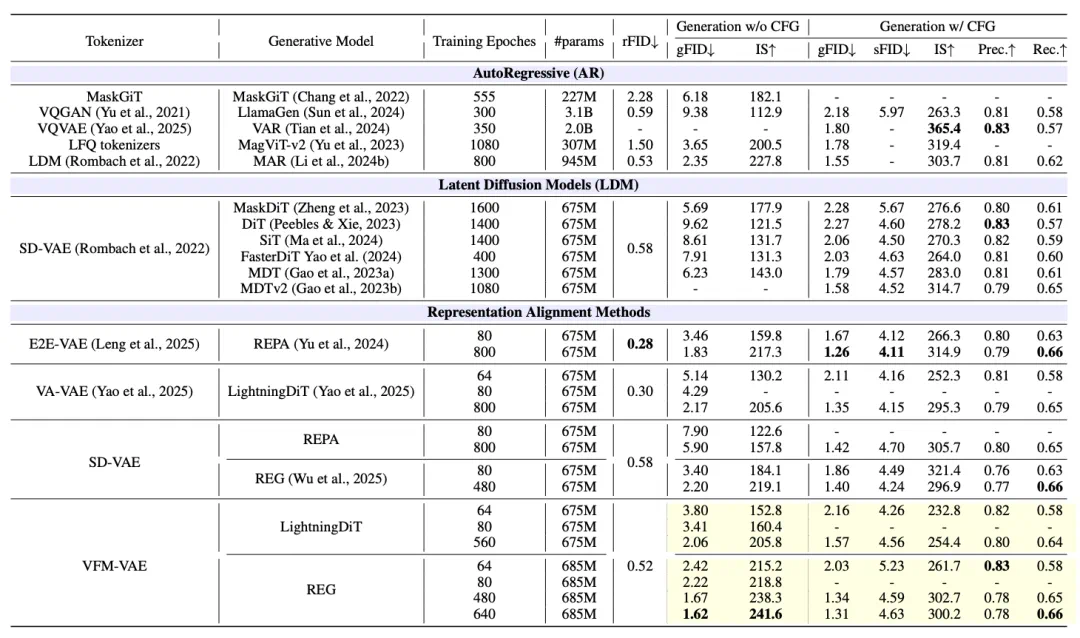
图 5:ImageNet 256x256 上各 LDM 系统的生成性能对比。

表 2:不同 Tokenizer 与 BLIP3-o 的文本生成图像结果(DPG-Bench),数值越高,代表长文本下文生图一致性越好。

表 3:不同 Tokenizer 与 BLIP3-o 的文本生成图像结果(MJHQ-30K),数值越低,代表对应类别下生成真实性越高。
从压缩到理解:VFM-VAE 重新定义潜空间的意义
长期以来,潜空间扩散模型中的 VAE 更多被视为压缩与还原的工具,而 VFM-VAE 将其转化为理解与生成的统一桥梁,使语义在潜空间中得到显式建模与传递。
未来,微软亚洲研究院的研究员们将继续探索潜空间在多模态生成与复杂视觉理解中的潜力,推动其从像素压缩迈向语义表征。