陆毅,复旦大学自然语言处理实验室硕士生,在 ACL、EMNLP、COLM、NeurIPS 等顶会发表论文十余篇,LongCat Team 核心成员,研究方向为大模型的复杂推理和长序列建模,指导老师为桂韬老师。
郭林森,硕士毕业于东南大学,在 NAACL、EMNLP、Recsys 等会议发表论文多篇,目前就职于美团,LongCat Team 核心成员,研究方向为大模型评测与数据价值挖掘。
王嘉宁,获得华东师范大学博士学位,曾前往 UCSD 访问学习,在 ACL、EMNLP、AAAI、ICLR 等顶会发表论文数十篇,目前就职于美团,LongCat Team 核心成员,研究方向为大模型训练与复杂推理。
研究背景:从「单步推理」到「长链决策」
OpenAI o1、DeepSeek-R1 等大型推理模型(LRMs)的出现,标志着 AI 推理能力进入了「测试时扩展」的新纪元。通过长链推理 Long Chain-of-Thought(CoT),这些模型在数学推理、代码生成、智能体任务等领域取得了令人瞩目的突破。
然而,当前的训练与评测范式存在一个根本性的局限:几乎所有主流 Benchmark(如 MATH500、AIME)都聚焦于孤立的单步问题,问题之间相互独立,模型只需「回答一个问题,然后结束」。但真实世界的推理场景往往截然不同:
- 一个软件工程师需要连续调试多个相互依赖的代码模块
- 一个数学研究者需要基于前序定理推导后续结论
- 一个智能助手需要在多轮对话中逐步完成复杂任务规划
这些场景要求模型具备跨问题的长链推理能力 —— 不仅要解决单个问题,还要在多个相互关联的子问题间维持推理连贯性、合理分配思考资源、进行跨步骤的反思与纠错。
这引出了一个核心问题:大型推理模型的长链推理能力边界究竟在哪里?
现有评测无法回答这个问题,传统训练数据也无法培养这种能力(如图所示,模型在长程推理场景下性能下降严重)。
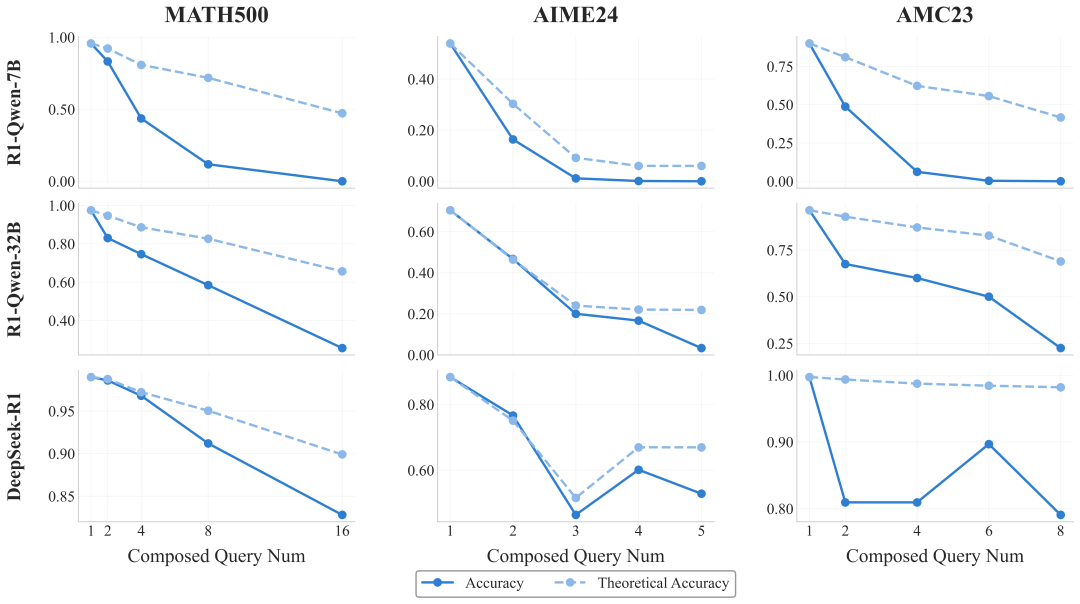
R1 系列模型在长程推理场景下理论准确率和实际准确率的差异
为填补这一空白,复旦大学与美团 LongCat Team 联合推出 R-HORIZON—— 首个系统性评估与增强 LRMs 长链推理能力的方法与基准。

- 论文标题: R-HORIZON: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?
- 论文地址: https://arxiv.org/abs/2510.08189
- 项目主页: https://reasoning-horizon.github.io
- 代码地址: https://github.com/meituan-longcat/R-HORIZON
- 数据集: https://huggingface.co/collections/meituan-longcat/r-horizon-68f75703a95676fbfed97879
R-HORIZON:揭开推理模型「能力地平线」
核心创新:Query Composition 方法
R-HORIZON 提出了一种简洁而强大的问题组合(Query Composition)方法,通过建立问题间的依赖关系,将孤立任务转化为复杂的多步骤推理场景。
以数学任务为例:
1. 提取关键信息:从多个独立问题中提取核心数值、变量等信息
2. 建立依赖关系:将前一个问题的答案嵌入到后一个问题的条件中
3. 形成推理链:模型必须按顺序正确解决所有问题才能得到最终答案
这种方法具有三大优势:
- 可扩展性:可灵活控制推理链长度(n=2, 4, 8...)
- 可控性:可灵活设定问题间的依赖关系
- 低成本:基于现有数据集即可构建,无需额外标注
基于这一方法,我们构建了长链推理的评测基准 R-HORIZON Benchmark,用于系统性评估 LRMs 在多步推理场景下的真实能力;同时,我们还构建了长链推理的训练数据,通过强化学习(RLVR)训练来提升模型的长链推理能力。
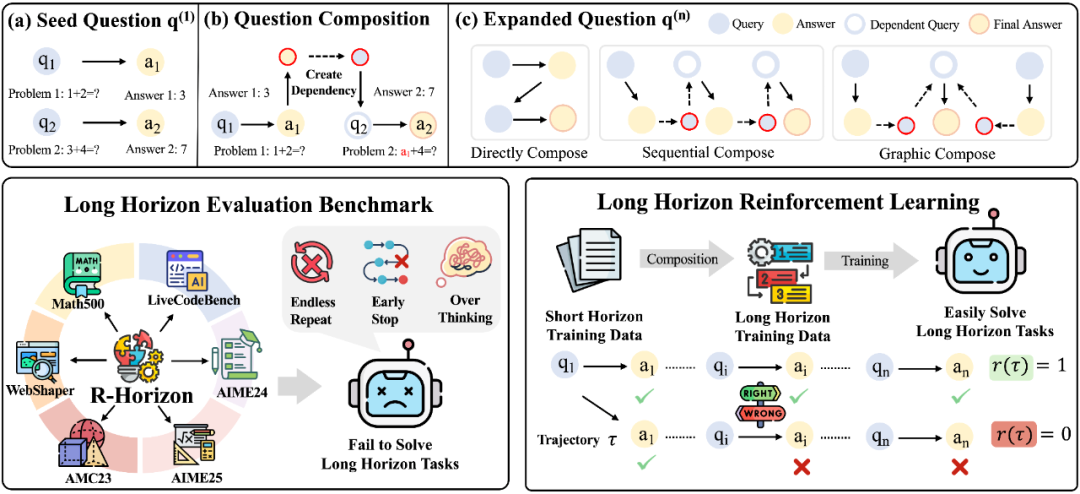
R-HORIZON 方法示意图 —— 从单一问题到复杂推理链的转化过程以及 R-HORIZON 的应用场景
R-HORIZON Benchmark:全面的长链推理评测基准
基于 Query Composition 方法,我们构建了 R-HORIZON Benchmark,涵盖 6 大代表性数据集:
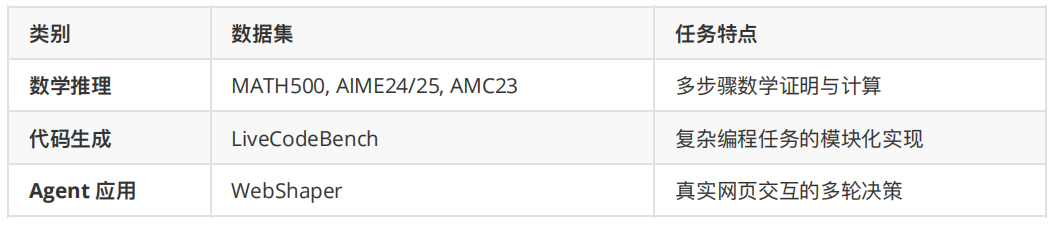
核心发现:顶级模型的「推理断崖」
我们评测了 20+ 个主流 LRMs(包括 o4-mini、Claude-Sonnet-4、DeepSeek-R1 等顶级商业模型以及开源模型),结果揭示了一个令人震惊的现象:即使是最先进的模型,在长链推理场景下也会出现性能断崖式下降。
关键发现:
- 普遍性能衰退:所有模型随着问题数量增加都出现显著性能下降。DeepSeek-R1 在 AIME25 单问题场景下准确率达 87.3%,但在 5 个组合问题场景下暴跌至 24.6%
- 模型规模影响:更大的模型对多步推理挑战展现出更强的韧性
- 任务依赖性衰退:代码生成任务相比数学任务表现出更陡峭的性能下降;许多推理模型在网页搜索场景中失去了工具调用能力
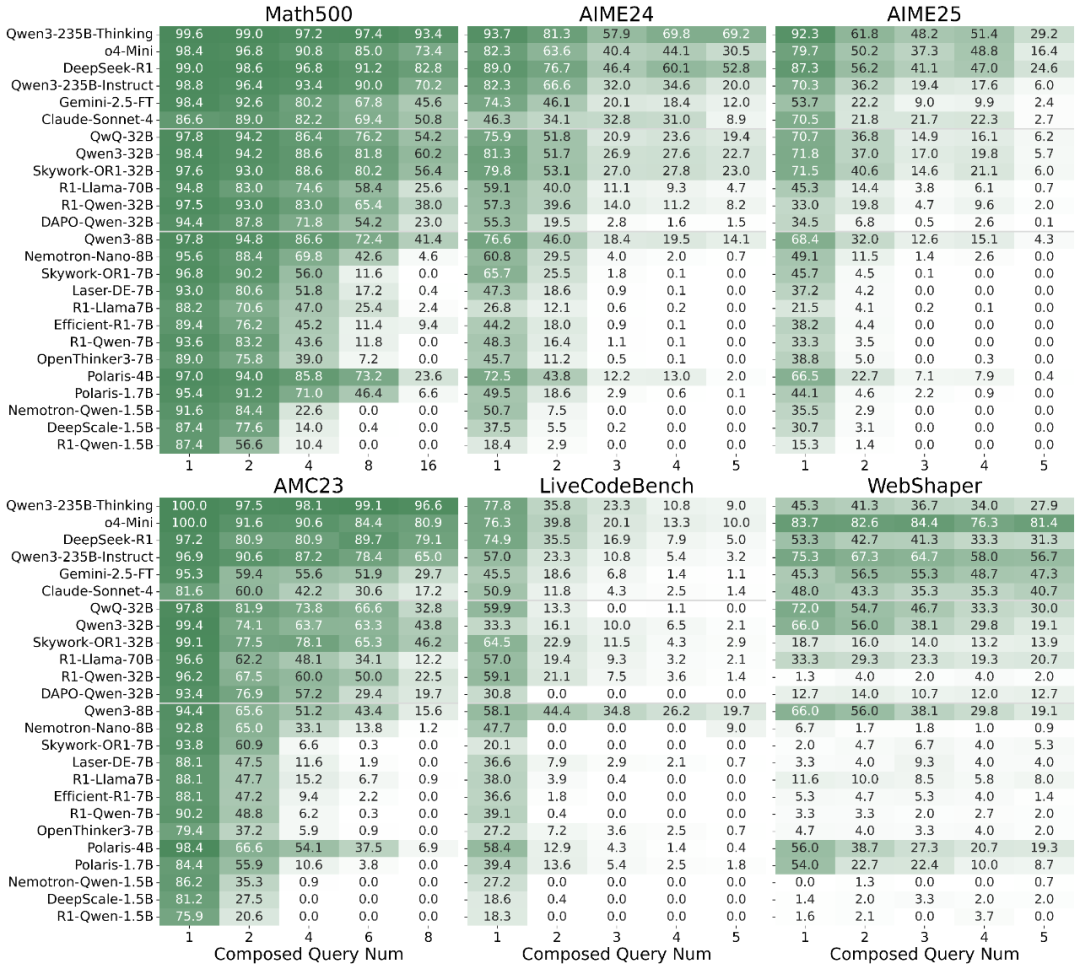
R-HORIZON Benchmark 评测结果 —— 所有模型均出现显著性能衰退
深度分析:推理模型的三大瓶颈
为了理解性能断崖背后的原因,我们进行了深入的机制分析,发现当前 LRMs 存在三个关键瓶颈:
1. 有效推理长度受限
随着相互依赖问题数量的增加,LRMs 难以维持其性能。实际准确率与理论准确率之间的差距显著扩大,表明模型无法在更长的推理范围内保持原有性能。
深入分析发现:
- 模型错误稳定在特定的上下文范围内
- 7B 模型的主要错误范围在 (4-6K tokens)
- 32B 模型将范围扩展到 (8-10K tokens)
- 这表明更大的模型拥有更长的有效推理边界
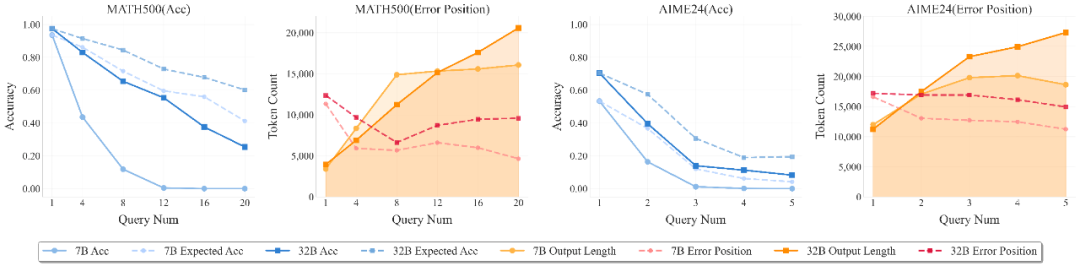
R1-Qwen-7B 和 R1-Qwen-32B 在准确率和错误位置上的分析
2. 反思机制高度局部化
我们分析了模型的「反思」行为,发现:
- 模型的反思频率随着问题数量增加而上升并趋于收敛
- 超过半数的复杂任务完全缺乏长程反思(跨越当前问题的反思)
- 这表明当前 LRMs 的反思机制高度局部化,不足以支撑长链场景
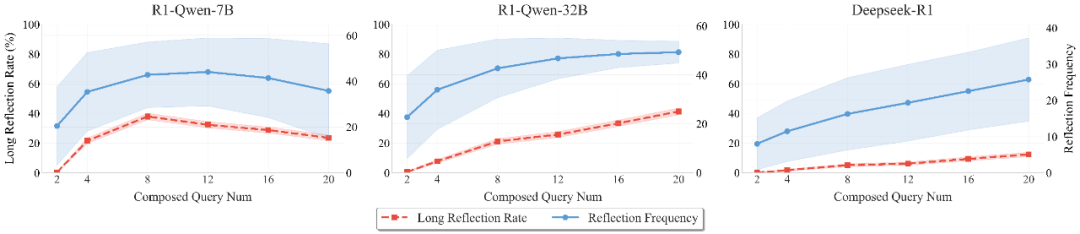
MATH500 数据集上的反思行为分析
3. 思考预算分配失衡
最令人意外的发现是:包括 DeepSeek-R1 在内的主流 LRMs 都无法有效地在推理范围内分配思考预算。
- 模型倾向于过度分配 tokens 给早期推理阶段
- 未能合理地将资源分配给后续的关键问题
- 这种失衡严重影响了整体推理链的完成质量
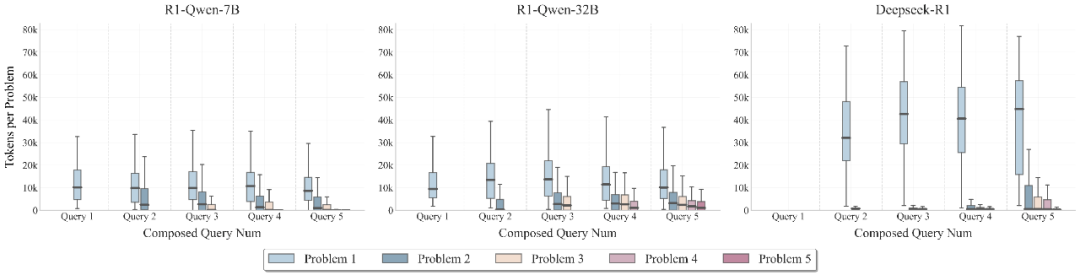
不同组合问题数量下各模型的思考预算分配
R-HORIZON 训练:重塑推理模型的能力边界
发现问题只是第一步,我们进一步探索:能否通过使用组合数据进行强化学习训练来突破这些瓶颈?
RLVR with R-HORIZON:用长链数据训练推理模型
我们使用 R-HORIZON 构建的长链推理数据并使用 GRPO 算法进行训练,训练策略:
- 基于主流 RLVR 算法 GRPO 进行训练
- 使用 R-HORIZON 组合数据(n=2, n=4)
- 设计不同的奖励函数进行对比实验
突破性成果:双重性能提升
实验结果令人振奋:R-HORIZON 训练不仅显著提升长链任务表现,连单问题性能也大幅增强。

加粗数字表示该列最佳成绩
不同训练配置下的性能对比。"Origin" 表示单问题场景,"n=X" 表示 X 个组合问题场景,"Multi" 表示多问题场景的平均性能
关键发现:
1. 双重性能提升:使用 n=2 组合问题训练,不仅大幅提升多步推理性能(AIME24 n=2 +17.4 分),单问题性能也显著增强(AIME24 单题 +7.5 分)
2. 可扩展复杂度:增加组合复杂度(n=4)增强了模型处理需要更多推理步骤问题的能力,在 MATH500 (n=8) 上达到 50.6%
训练带来的质变
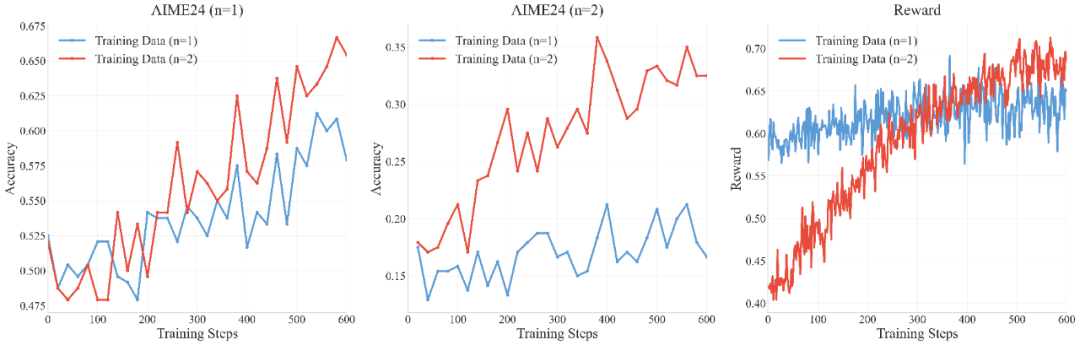
R-HORIZON 训练不仅提升了性能数字,更带来了推理机制的深层改变:
更高效的推理长度:
训练显著改善了模型在组合任务上的性能,展现出更好的泛化到更长推理链的能力,同时缓解了「overthinking」现象(生成更短、更高效的回答)。
更合理的预算分配:
模型学会了在多步问题中进行更合理的 token 预算分配,不再「重头轻尾」。
更长程的反思能力:
R-HORIZON 促进了模型进行更长程反思的频率增加,直接改善了长链推理性能。
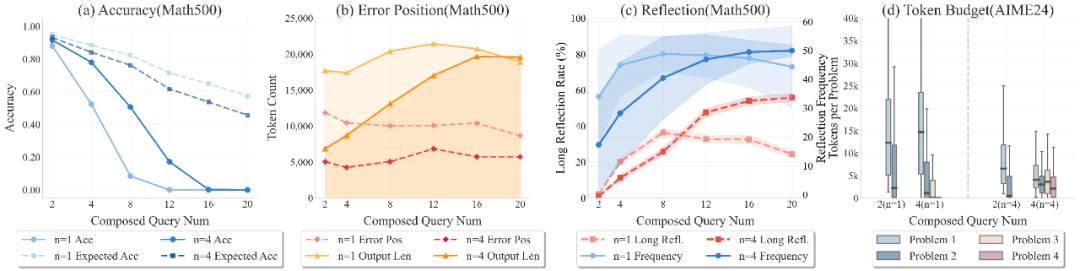
图:使用标准数据集和组合数据集进行强化学习的效果分析
结论与展望:开启长链推理新纪元
R-HORIZON 的推出,标志着大型推理模型研究进入了一个新的阶段 —— 从「能解决什么问题」到「能走多远」的范式转变。
技术贡献
- 首个长链推理评测基准:系统性揭示了 LRMs 的能力边界,包括有效推理长度、反思范围和思考预算分配的局限性
- 可扩展训练范式:提供了低成本、高效率的能力提升路径,通过 Query Composition 方法实现可控的长链推理数据构建
- 深度机制分析:为未来的推理模型指明了改进方向,揭示了当前模型在长链推理中的三大瓶颈
开放生态
R-HORIZON 框架已全面开源,包括:
- 完整评测代码与 Benchmark 数据
- 训练数据和训练代码
- 数据构建流程
- 详细文档与使用教程
期待与全球研究者携手,共同推动下一代推理模型的发展,让人工智能在现实世界中展现出更卓越的长链推理能力。


