vivo自研大模型用的数据筛选方法,公开了。
香港科技大学和vivo AI Lab联名提出PreSelect,目前已被ICML 2025接收。
这是一种轻量级且高效的数据选择方法:只需要训练和部署一个基于fastText的评分器,就可以减少10倍的计算需求。
该方法提出数据的预测强度(Predictive Strength) 的概念和计算公式,利用在不同模型上Loss有序性表征数据对特定能力的贡献,通过获取特定能力的有效样本训练fastText分类器对全量训练数据进行筛选。
 △论文标题:Predictive Data Selection: The Data That Predicts Is the Data That Teaches
△论文标题:Predictive Data Selection: The Data That Predicts Is the Data That TeachesPreSelect:更客观、更轻量
现有的数据筛选方法主要分为两类:基于规则的筛选和基于模型的筛选。
基于规则的筛选依赖人工构建的先验规则,如C4 pipeline、Gopher rules,以及RefinedWeb和FineWeb的数据筛选流程。此类方法虽然实现简单,但容易受到人工经验的限制,存在泛化能力弱或规则主观性强的问题。
基于模型的筛选则通过训练模型对数据分类或打分以筛选样本,如CC Net采用困惑度(Perplexity)打分,FineWeb-Edu利用Bert分类器评估教育价值,DsDm和MATES计算样本的influence score,DCLM利用 fastText打分器评估样本与SFT数据的相似性。这类方法常面临计算成本高或者引入主观偏见等问题。
而PreSelect方法具有以下优势:
- 客观性将传统的主观性的数据质量评估转化为对模型能力的贡献大小,通过“预测强度”指标,量化评估数据在不同能力上的价值;
- 泛化性筛选的正样本不仅覆盖高质量内容来源,同时具备良好的多样性,避免过度集中于某一领域、来源或风格;
- 轻量级通过fastText分类器近似打分,大幅降低计算成本,使得该方法可以高效应用于大规模数据筛选任务中;
- 高细粒度
- 支持样本级别的筛选
- 支持特定细分能力维度的数据筛选
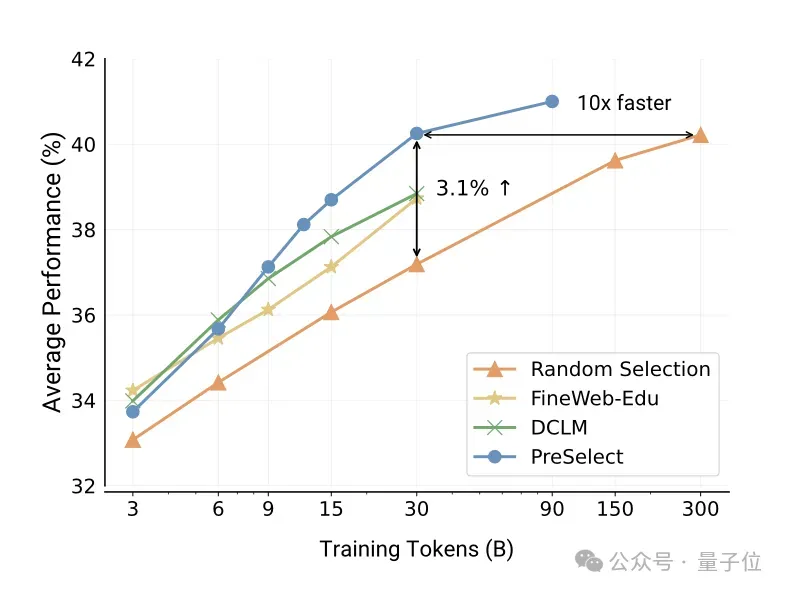
△PreSelect方法与现有SOTA方法的对比,数据效率提升10倍
PreSelect:压缩即智能
“压缩即智能”(compression represents intelligence)这一观点揭示了一个核心现象:大模型对数据的压缩能力(例如BPC, bits per character)与其在该数据上的归一化Loss存在等价关系,且与模型在下游任务中的表现高度相关。
换言之,模型越能高效压缩数据,模型能力或智能水平越高。
核心思想
PreSelect团队提出以数据预测强度(Predictive Strength)作为衡量模型loss与下游任务(benchmark)表现一致性的指标,其计算公式如下:
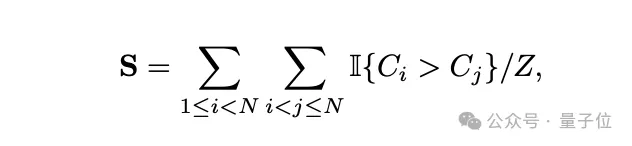
- N代表模型数量,这些模型在benchmark的得分 {S1 < S2 < … < SN}
- C代表模型在数据集d上的归一化loss,即BPC
- Z为归一化因子
- I{}为指示函数
- S取值范围 [0,1]
当S=1 时,表示不同模型在benchmark上的得分排序与其在该数据上的loss排序完全一致,说明该数据具有很高的预测强度;相反,当S=0时,说明两种排序之间没有相关性,该数据对下游任务的作用弱,预测强度很低。
根据预测强度的高低对数据进行筛选,优先保留那些使得不同模型在benchmark上的得分排序与在数据上的loss排序更一致的数据。
这类数据对模型能力的贡献更加显著,能够更有效地提升模型效果。
与现有方法相比,该方法具有更坚实的理论基础,减少了对人工启发规则的依赖,筛选过程更客观、更具有泛化性。
系统框架
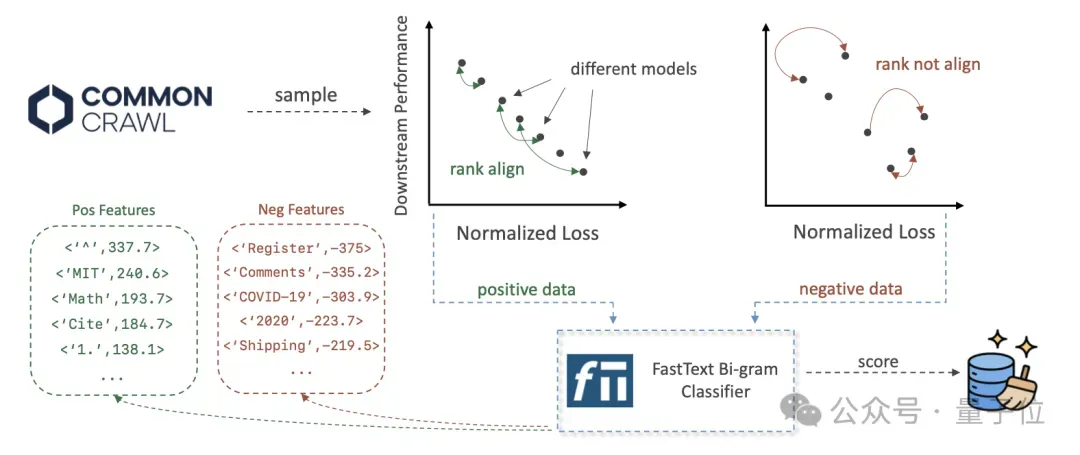
计算预测强度需要多个模型分别对数据样本计算loss,全量数据计算的成本将非常高。
为解决这一问题,使用fastText打分器作为代理模型近似预测强度,从而显著降低计算成本。
整体流程如下:
训练效果
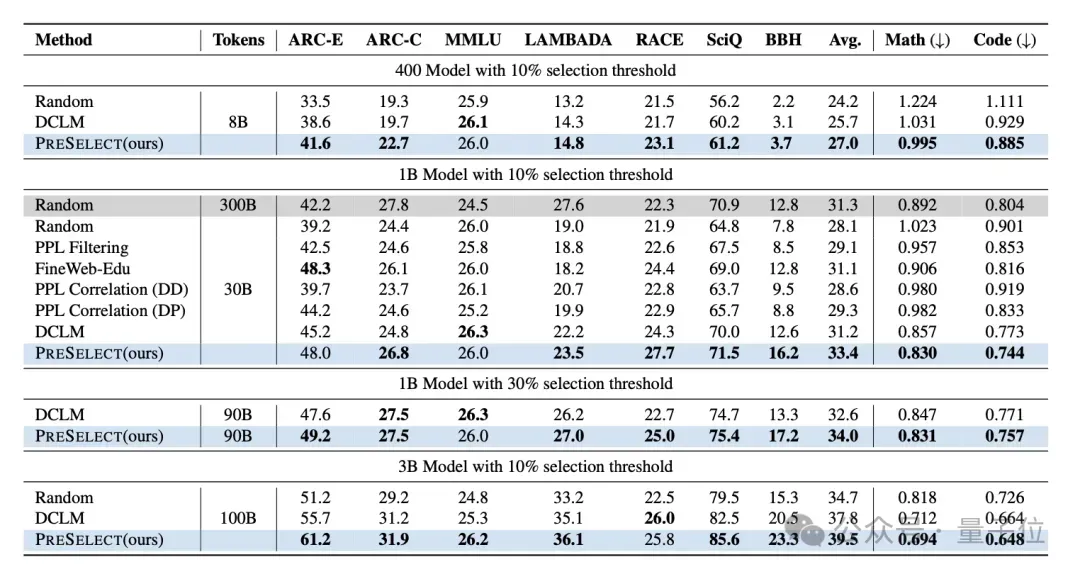
PreSelect团队从RefinedWeb数据集中随机抽取80B、300B和1T tokens作为基础数据,评估不同筛选方法的效果。筛选比例设置为10%和30%,筛选后的数据量级包括8B、30B、90B和100B。所训练模型的参数规模包括400M、1B和3B。
实验对比的筛选方法包括Random、Perplexity Filter、Perplexity Correlation(DD)、Perplexity Correlation(DP)、FineWeb-Edu、DCLM。
在下游17个任务上的实验结果表明,PreSelect方法筛选出的数据在训练的模型效果上显著优于其他方法,对比baseline平均提升了3%,验证了其有效性。
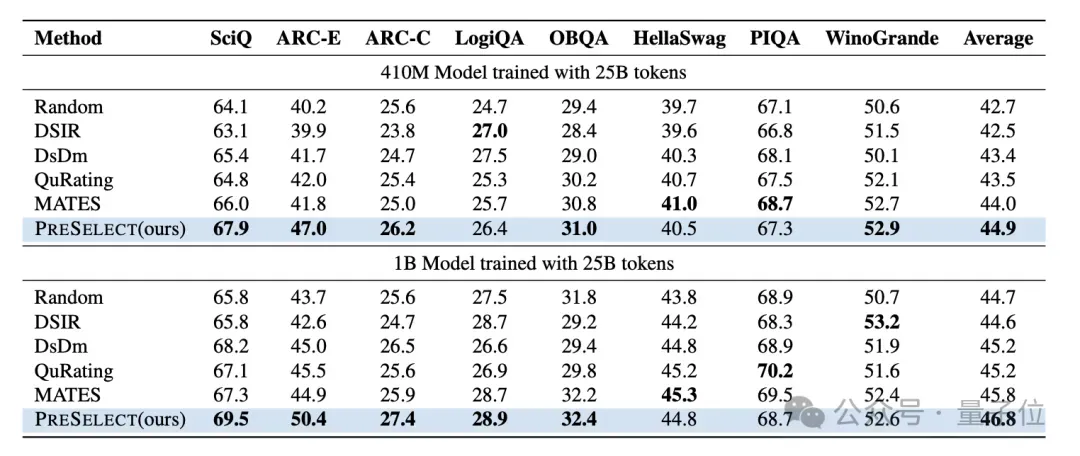
在C4数据集上,进一步对比多种主流筛选方法,包括Random、DSIR、DsDm、QuRating和MATES,所训练的模型为Pythia。
实验结果显示,PreSelect方法筛选的数据训练出的模型在多项指标上均优于其他方法。
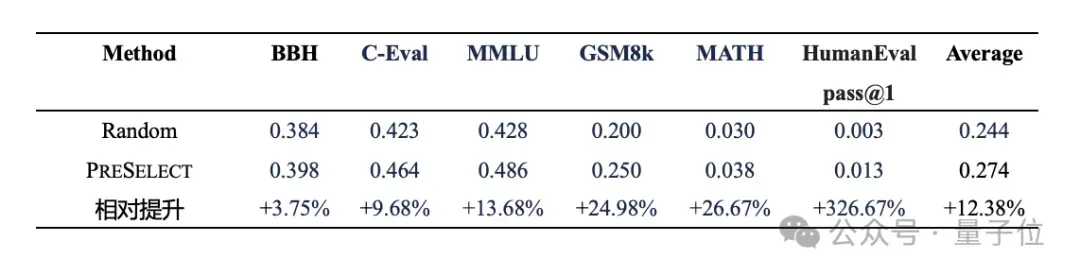
从已通过人工规则集和多种质量评分模型筛选,并经过不同粒度的文本级和语义级去重的vivo自有Web数据集中,随机抽取5T tokens作为基础数据,分别采用PreSelect与Random方法各自筛选10%(即500B tokens),训练参数规模3B的模型并评估下游任务效果。
实验结果表明,即使在自有的经过优化处理的数据集上,PreSelect方法依然有显著的性能提升,展现出其在高质量数据基础上的增益能力。

经过对不同数据筛选方法所选择的样本进行分析,结果表明PreSelect筛选的domain数据更多地采样了知识、问答和文学领域,更广泛地覆盖了高质量来源内容,能够显著提升模型在各个领域的效果。
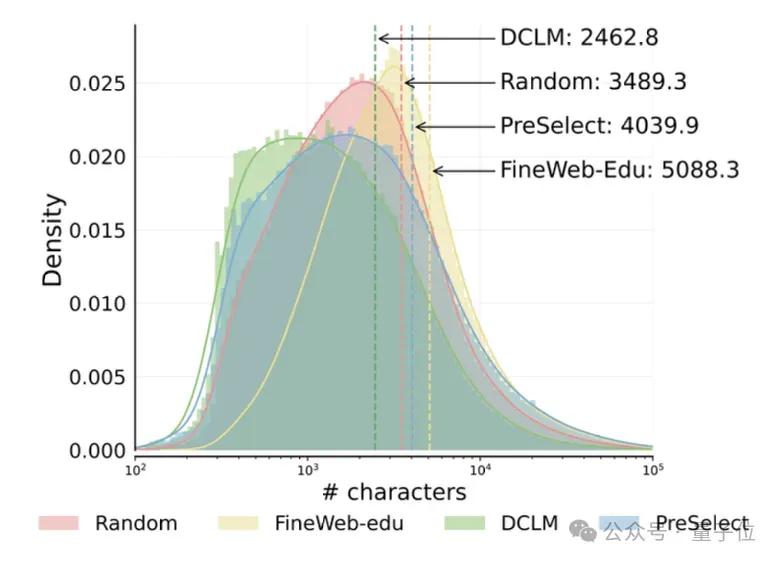
通过对不同数据筛选方法所筛选出的数据长度进行比较,可以看到DCLM 和FineWeb-Edu显示出明显的短数据向量和长数据向量趋势,而PreSelect筛选的数据在长度分布上更接近原始长度分布。表明其在筛选出高质量样本的同时,有效减少了样本长度偏差(length bias),具备更好的代表性与覆盖性。
论文链接:https://arxiv.org/abs/2503.00808


