
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。该研究已被机器学习顶级会议 NeurIPS 2025 接收,为长视频理解任务提供了全新的解决思路。

项目主页:https://video-rag.github.io/
论文链接:https://arxiv.org/abs/2411.13093
开源代码:https://github.com/Leon1207/Video-RAG-master
挑战:现有方法为何难以胜任?
当前主流方案主要分为两类:
扩展上下文法(如 LongVA):依赖大规模长视频 - 文本配对数据进行微调,训练成本高且数据稀缺;
智能体驱动法(如 VideoAgent):通过任务分解与外部代理决策增强推理,但频繁调用 GPT-4o 等商业 API 导致开销巨大。
更重要的是,两种方法在长时间跨度下的视觉 - 语义对齐上表现有限,往往牺牲效率换取精度,难以兼顾实用性与可扩展性。
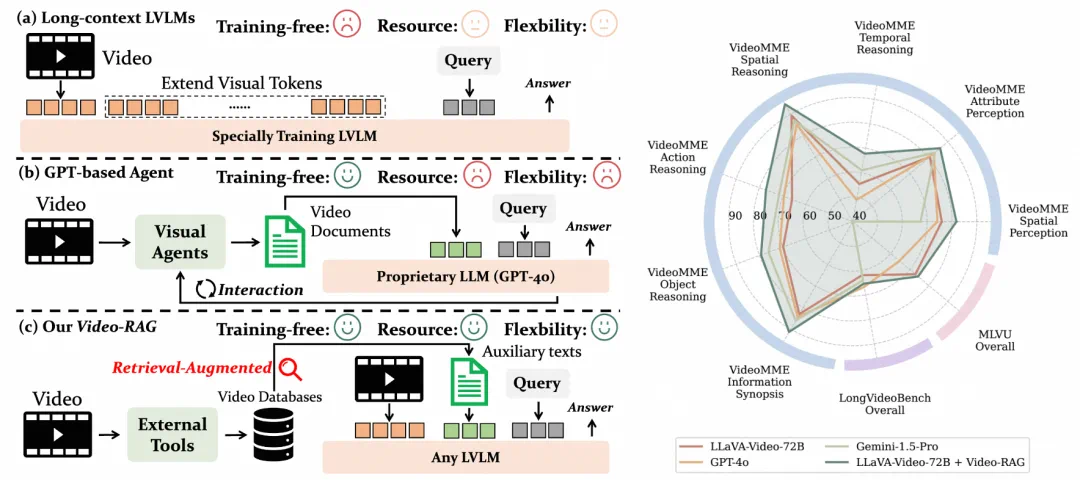
创新:用 “检索” 打通视觉与语言的桥梁
Video-RAG 提出一种低资源消耗、高语义对齐的新路径 —— 多模态辅助文本检索增强生成(Retrieval-Augmented Generation, RAG),不依赖模型微调,也不需昂贵的商业大模型支持。其核心思想是:从视频中提取与视觉内容强对齐的文本线索,按需检索并注入现有 LVLM 输入流中,实现精准引导与语义增强。
具体流程如下:
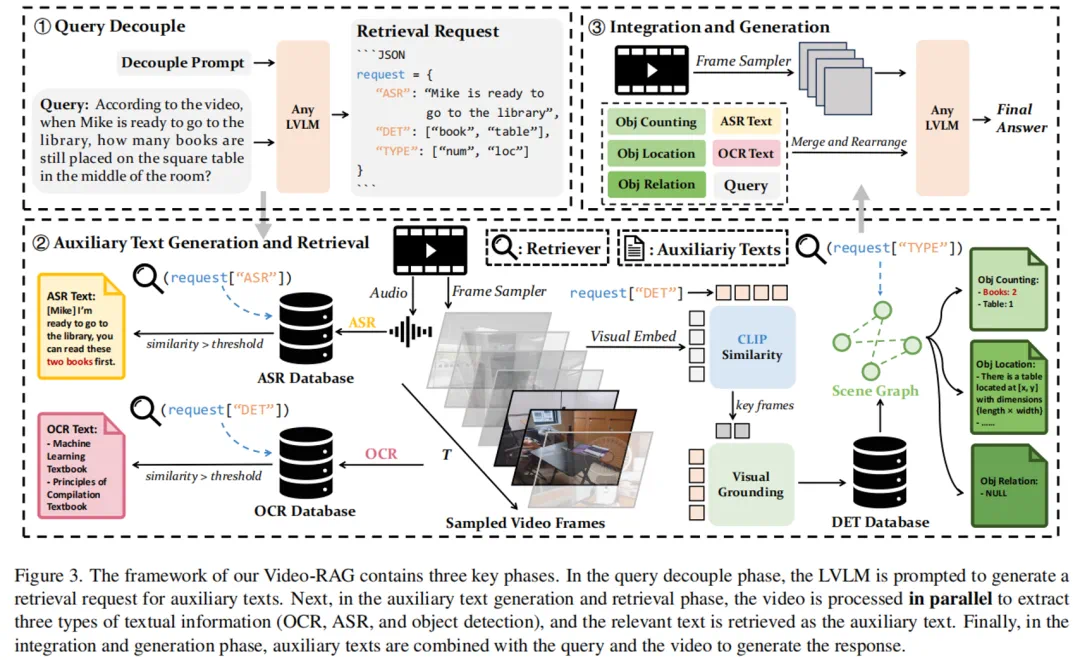
1. 查询解耦(Query Decoupling)
将用户问题自动拆解为多个检索请求(JSON 格式),指导系统从不同模态数据库中查找相关信息,LVLM 此阶段仅处理文本,不接触视频帧,大幅降低初期计算负担。
2. 多模态辅助文本构建与检索
利用开源工具构建三大语义对齐数据库:
OCR 文本库:使用 EasyOCR 提取帧内文字,结合 Contriever 编码 + FAISS 向量索引,支持快速检索;
语音转录库(ASR):通过 Whisper 模型提取音频内容并嵌入存储;
对象语义库(DET):采用 APE 模型检测关键帧中的物体及其空间关系,经场景图预处理生成结构化描述文本。
这些文本不仅与画面同步,还具备明确语义标签,有效缓解传统采样帧缺乏上下文关联的问题。
3. 信息融合与响应生成
将检索到的相关文本片段、原始问题与少量关键视频帧共同输入现有的 LVLM(如 LLaMA-VID、Qwen-VL 等),由模型完成最终推理输出。整个过程无需微调、即插即用,显著降低部署门槛与计算开销。
可以发现,在经过检索之后,LVLM 可以将更多的注意力集中到对应的关键视觉信息上,减少模态鸿沟:

优势:轻量、高效、性能卓越
即插即用:兼容任意开源 LVLM,无需修改模型架构或重新训练。
资源友好:在 Video-MME 基准测试中,平均每问仅增加约 2000 token,远低于主流 Agent 方法的通信与计算开销。
性能领先:当与一个 72B 参数规模的开源 LVLM 结合时,Video-RAG 在多个长视频理解基准上超越 GPT-4o 和 Gemini 1.5 等商业闭源模型,展现出惊人的竞争力。
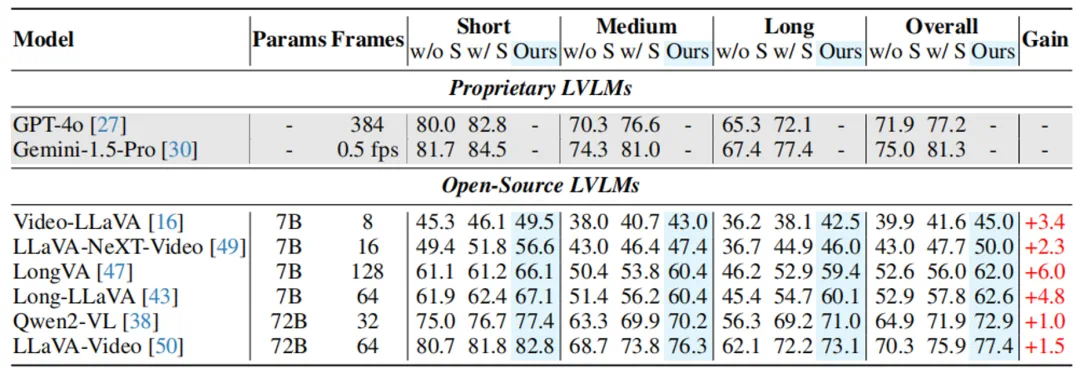
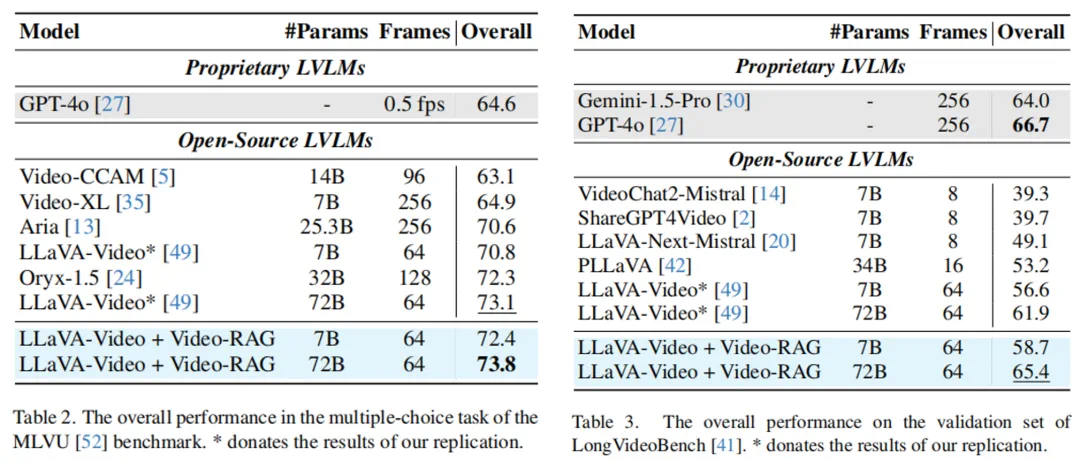
成果与意义
Video-RAG 的成功验证了一个重要方向:通过高质量、视觉对齐的辅助文本引入外部知识,可以在不改变模型的前提下,突破上下文窗口瓶颈,显著提升跨模态理解能力。它不仅解决了长视频理解中的 “幻觉” 与 “注意力分散” 问题,更构建了一套低成本、高可扩展的技术范式,适用于教育、安防、医疗影像分析等多种现实场景。


