今天凌晨,谷歌Deepmind在官网发布了,用于设计高级算法的编程AI Agent——AlphaEvolve。
AlphaEvolve与谷歌的大模型Gemini实现深度集成,用于自动评估通用算法的发现与优化,可以帮助开发人员快速设计出最好、高效的矩阵算法。
简单来说,大模型擅长生成各种想法和算法,但是没人知道这些到底行不行,而AlphaEvolve相当于“质检员”,能够按照特定标准来衡量这些想法是否可行。

AlphaEvolve超强能力
谷歌在展示AlphaEvolve的能力时,就特意找了一道300多年的数学难题——亲吻数问题。
这道题的历史最早可以追溯到1694年,牛顿还和别人辩论、研究过。其难点在于给定维度的空间中,最多可以有多少个相同大小的球体同时接触一个中心球体,这些球体之间不发生重叠。
而AlphaEvolve发现了由593个外层球体组成的结构型,并在11维空间中建立了新的下界,超越之前数学家们创造的记录。
AlphaEvolve还能为复杂的数学问题提出新的解决方法。基于极简代码框架,AlphaEvolve设计了一种基于梯度的新型优化程序的诸多组件,并发现了多种用于矩阵乘法的新算法。
AlphaEvolve找到了一种用于4x4复值矩阵乘法的算法,该算法仅需48次标量乘法,改进了Strassen在1969年提出的算法,后者此前被认为是该场景下的最佳算法。这一发现表明,与谷歌之前专注于矩阵乘法算法的研究成果AlphaTensor相比,取得了重大进展。
此外,谷歌使用AlphaEvolve来增强大模型的训练和推理。AlphaEvolve将大规模矩阵乘法运算拆解为更易于处理的子问题,使Gemini模型架构中的核心计算效率提升了23%,整体训练时间缩短了1%,节省大量成本。
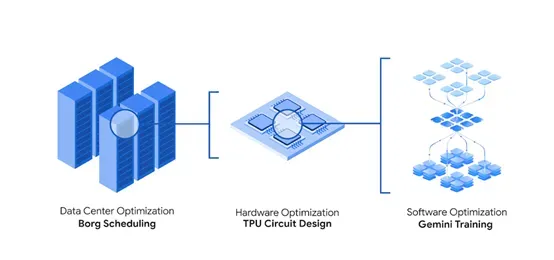
AlphaEvolve还能对GPU底层指令进行优化。这是一个极其复杂的领域,通常编译器已对其进行了深度优化,所以,人类工程师一般不会直接对其进行修改。
AlphaEvolve实现了基于Transformer的人工智能模型中FlashAttention核心计算最高达32.5%的加速。这类优化有助于专家精准定位性能瓶颈,并能轻松地将优化成果整合到代码库中,极大提高了工作效率。
AlphaEvolve架构简单介绍
任务定义与评估模块是AlphaEvolve的核心之一,主要负责明确用户的需求,包括评估标准、初始解决方案以及背景知识。通过一个自动化的评估机制来衡量生成的解决方案的质量,这一机制以函数的形式存在,将解决方案映射到一组标量评估指标上。
这些指标通常是最大化的目标,例如,在数学问题中,如果目标是找到满足特定属性的最大可能图,评估函数将调用进化代码生成图,检查属性是否成立,然后返回图的大小作为得分。
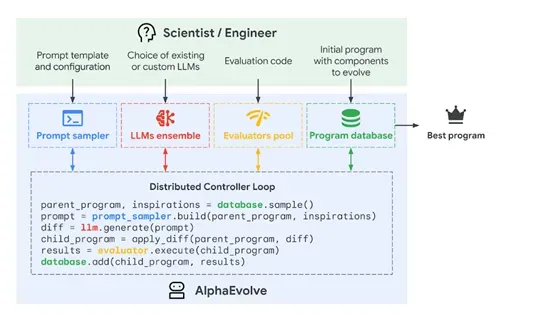
大模型集成与提示采样模块负责构建上下文提示,这些提示包括明确的上下文信息,例如,问题的详细描述、方程式、代码片段或相关文献;随机格式化,通过概率分布提供人类编写的替代方案以增加多样性;渲染的评估结果,包括程序、执行结果以及评估函数分配的分数;
以及元提示进化,由大模型本身在额外的提示生成步骤中建议的指令和上下文,这些内容与解决方案程序在单独的数据库中共同进化,为大模型提供了丰富的信息,使其能够生成更准确和有效的代码修改建议。
创造性生成与代码修改是AlphaEvolve另外一个核心模块,主要利用大模型的能力来生成代码修改建议。这些大模型能够处理丰富的上下文信息,并根据过去的尝试和想法提出新的改进方案。
当AlphaEvolve要求大模型修改现有代码时,它会请求以特定格式的差异块提供更改,这种格式允许对代码的特定部分进行针对性的更新。在某些情况下,如果代码非常短,或者需要完全重写,AlphaEvolve可以配置为直接输出整个代码块,而不是使用差异格式。
评估与反馈模块负责跟踪AlphaEvolve的进展,并选择在后续代中传播哪些想法。每个由大模型提出的新解决方案都会被自动评估,这一过程本质上是简单地在生成的解决方案上执行用户提供的评估函数。
AlphaEvolve支持一些可选机制,使评估更加灵活和高效,例如,评估级联,用户可以指定一系列难度递增的测试用例,只有在所有早期阶段都取得足够有希望的结果时,新解决方案才会进入下一个阶段;
大模型生成的反馈,用于评估那些难以在用户提供的评估函数ℎ中精确捕捉的解决方案特性;以及并行化评估,通过异步调用评估集群来分配这项工作,从而提高评估效率。
进化与数据库管理负责存储和管理在进化过程中生成的解决方案。这些解决方案存储在一个进化数据库中,其主要目标是在后续代中最佳地重新出现先前探索的想法。设计这种数据库的一个关键挑战是平衡探索和利用,以持续改进最佳程序,同时保持多样性以鼓励整个搜索空间的探索。
AlphaEvolve的进化数据库实现了一种算法,该算法受到MAP精英算法和基于岛屿的种群模型的启发。

分布式计算管道模块使AlphaEvolve能够作为一个异步计算管道运行。每个计算在等待另一个尚未完成的计算结果时都会阻塞。整个管道针对吞吐量进行了优化,而不是任何特定计算的速度,以最大化在特定总体计算预算内可以提出和评估的想法数量。

目前,有兴趣的小伙伴可以去谷歌Deepmind官网申请使用AlphaEvolve,尤其是对于科研、数学、设计领域的小伙伴帮助很大。


