就在刚刚,苹果在Hugging Face上重磅开闸:
这一次不是零碎更新,而是FastVLM与MobileCLIP2两条多模态主线集中亮相。
一个主打「快」,把首字延迟压到竞品的1/85;
另一个突出「轻」,在保持与SigLIP相当精度的同时,体积减半。
打开摄像头实时字幕、离线识别翻译、相册语义搜索,这些场景都能体验。
更重要的是,模型和Demo都已经开放,科研、应用到落地一步到位。
实时字幕,不再卡顿的多模态
FastVLM为何这么快?因为它换上了苹果自研的FastViTHD编码器。
传统多模态模型要么牺牲分辨率,要么被成千上万的视觉token拖慢推理。
而FastViTHD通过动态缩放和混合设计,让模型既能看清高分辨率图像,又能保持极低的延迟。
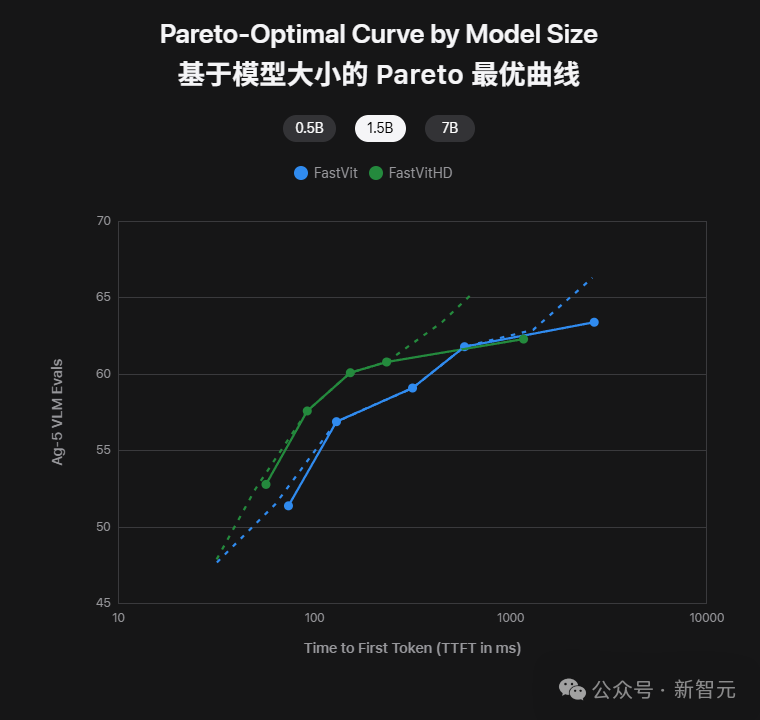
FastVit 与 FastVitHD 的性能对比:绿色曲线整体更靠左上,代表在同等规模下既更快又更准
从这条对比曲线能看得很清楚:同样是0.5B、1.5B、7B参数量,绿色的FastVitHD总比蓝色的FastVit更靠左上。
换句话说,就是延迟更低、精度更高。
这也就是FastVLM能在不降分辨率的情况下依旧秒回的秘密。
FastVLM用更少的视觉token处理高分辨率输入,直接把「算力负担」减轻。
那么,速度差距有多夸张?
官方对比显示,FastVLM-0.5B的首字延迟相对LLaVA-OneVision-0.5B快85×。
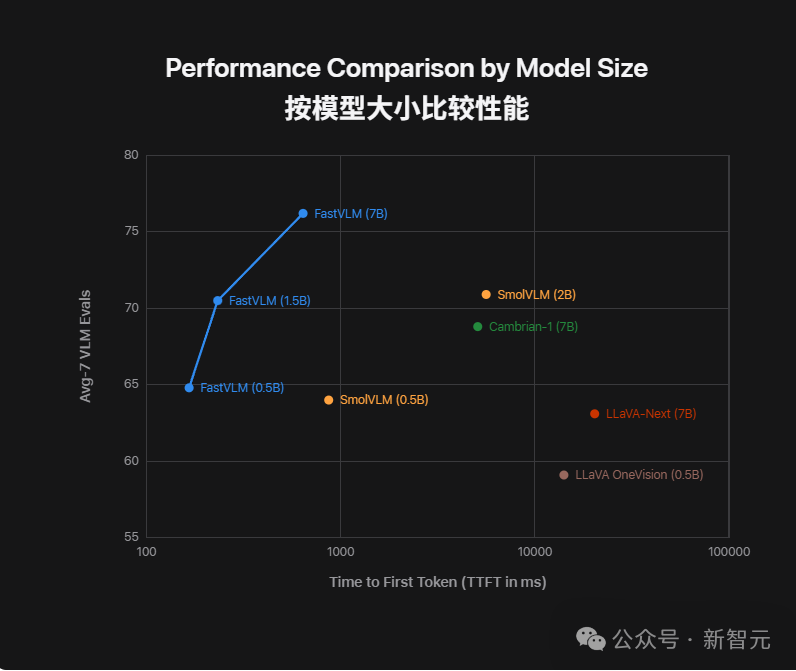
不同模型在 7 个视觉语言任务上的平均准确率(纵轴)与首字延迟 TTFT(横轴)的对比
从这张性能对比图可以直观看出:FastVLM越大,性能越强,但延迟始终压得极低。
FastVLM的0.5B、1.5B、7B模型,都稳定压在左上角。
对比LLaVA-OneVision、LLaVA-Next等传统方案,不仅更慢,准确率也没拉开差距。
也就是说,FastVLM 把快和准同时做到极致,不是「牺牲质量换速度」,而是真正实现了两头兼顾。

使用低分辨率(左)和高分辨率(右)输入图像时VLM性能的比较
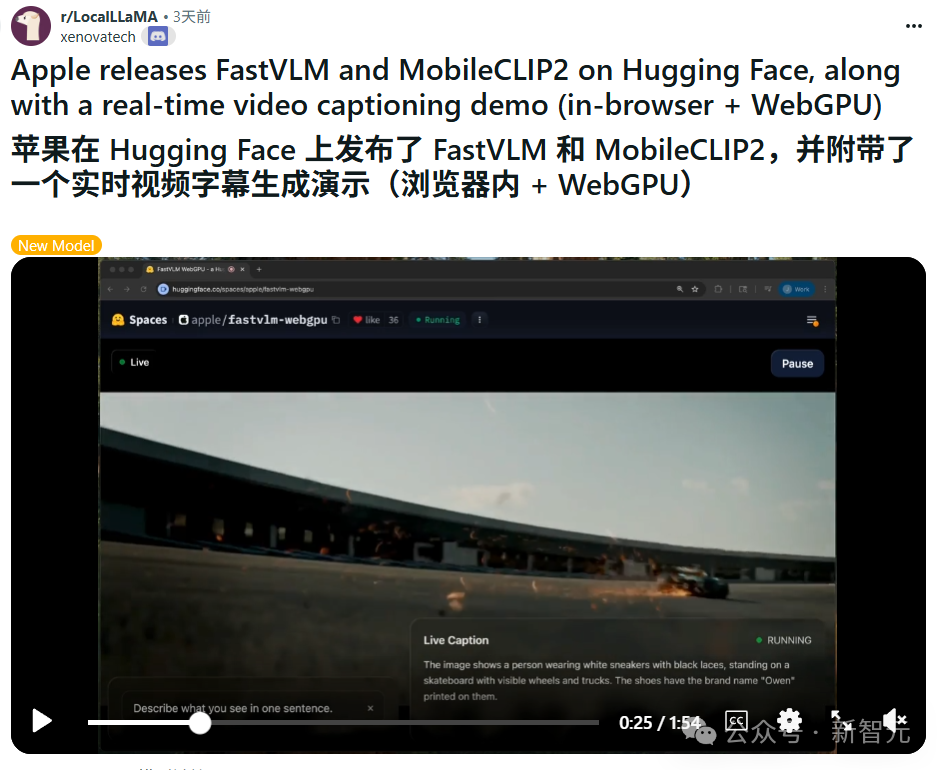
更关键的是,FastVLM已经放到了Hugging Face,配好WebGPU Demo,用 Safari打开就能直接体验。
更小更快,零样本也能打
如果说 FastVLM 代表「极致的快」,那 MobileCLIP2就是「轻装上阵」。
它是苹果在2024年推出MobileCLIP的升级版。
研究团队通过多模态蒸馏、captioner teacher和数据增强等手段,把「大脑」压缩进「小身体」,既减轻了模型体积,又保住了理解力。
过去,图像检索和描述往往依赖云端算力,如今MobileCLIP2能直接在iPhone上完成推理。
照片不必上传,结果几乎即时返回,不仅快,而且更安全。
从整体测试曲线来看,MobileCLIP2 在「精度-延迟」坐标轴上整体更靠左上。
这意味着它在保持高精度的同时,把延迟显著压低。
MobileCLIP2在ImageNet-1k上的 zero-shot表现:相比SigLIP和旧版MobileCLIP,更小的延迟下实现相近甚至更高的精度。
在测试中,S4模型在ImageNet-1k上与SigLIP-SO400M/14精度相当,但参数量仅有一半。
在iPhone 12 ProMax上,延迟更是比DFN ViT-L/14低了2.5倍。
相比之下,B模型相对上代MobileCLIP-B又提升了+2.2%,而S0/S2则以接近ViT-B/16的精度实现了更小体积与更快速度。

从体验到集成,两步就能上手
苹果这次不只是发模型,还顺手铺好了路:先试Demo,再集成开发。
最直观的方式,就是去Hugging Face打开他们提供的FastVLM WebGPU Demo。
在Safari授权摄像头后,就能立刻看到实时字幕效果。
MobileCLIP2 的模型卡同样提供推理接口,上传一张照片或输入一句描述,就能马上出现结果。
体验过后,如果想把这些功能真正变成应用,开发者可以用Core ML+Swift Transformers工具链,把模型直接集成到iOS或macOS里。

苹果在WWDC和Hugging Face的文档中都给了现成示例,GPU和神经引擎都能调动,性能和能耗都有保证。
这意味着「在iPhone 上跑大模型」不再只是一个演示,而是可以被直接拿来做相册搜索、相机翻译、直播字幕等具体功能。
「体验+开发」,对开发者来说再也不是口号,而是真实可用的路径。
光看模型介绍很难有感觉,真正打动人的,还是那些使用成功的瞬间。
当你打开FastVLM的WebGPU Demo,举起手机摄像头对着纸上的字——几乎是瞬间识别。
FastVLM能快速识别图像中的文字
在Reddit社区,有人亲测后写道:
「快得不可思议,盲人用屏幕阅读器都能实时跟上。横着拿手机,边走边敲盲文输入,都不卡。」—— r/LocalLLaMA
这句话把FastVLM的速度感形容得淋漓尽致:
不仅普通用户能体验 到「字幕秒回」,在无障碍场景下,它甚至让盲文输入与屏幕阅读器同步成为可能。
还有技术社区的用户补充道:
「FastVLM 能做到高效又准确的图像文本处理,速度和精度都比同类模型更出色。」 —— r/apple
从生活中的真实体验,到技术层面的验证,网友们的评价都指向一个结论:FastVLM不只是快,而且快得可靠。
FastVLM vs MobileCLIP2
该怎么选?
看了这篇介绍,可能有人会问:那我到底该用哪个?
如果你是内容创作者、博主,追求字幕秒出的体验,那FastVLM是首选。
如果你更需要相机翻译、离线识别,那MobileCLIP2更合适。
当然,如果你的应用场景既涉及实时字幕,又需要图文检索,那么二者完全可以组合使用。
但要注意,WebGPU在不同浏览器和机型上的兼容性并不完全一致;
而且端侧模型虽然解决了隐私和延迟,但在算力和续航上始终存在权衡。
即便如此,这一次苹果在Hugging Face上的「开闸」,依然有着标志性意义。
不仅放出了模型,还把Demo、工具链、文档全部交到社区手里。
对开发者来说,这已经不是一篇论文,而是一条能被立刻走通的路线。
从快到轻,从体验到集成,FastVLM和MobileCLIP2展示了一个清晰的信号——
在iPhone上跑大模型,不再是遥远的未来,而是触手可及的现在。


