就在刚刚, Mistral AI发布了他们最新多模态模型Mistral Medium 3。
Mistral兴奋地宣称Mistral Medium 3的性能接近甚至达到了Claude Sonnet 3.7的水平,但成本却比DeepSeek V3还低。
性价比拉满!

在Mistral官方的博客中,列出了Mistral Medium 3的核心亮点:
1. Mistral Medium 3平衡了:
- 顶尖性能
- 成本降低至原来的八分之一
- 更易于部署,从而加速企业应用
2. 模型在代码编写和多模态理解等专业应用场景中表现出色。
3. 模型提供一系列企业功能,包括:
- 支持混合云部署、本地部署以及在VPC内部署
- 定制化后训练
- 集成到企业工具和系统中
Mistral Medium 3 API,现已在Mistral La Plateforme和Amazon Sagemaker上线,并将很快登陆IBM WatsonX、NVIDIA NIM、Azure AI Foundry和Google Cloud Vertex。
完美平衡
Mistral Medium 3在提供前沿性能的同时,成本却降低了一个数量级。
例如,在各项基准测试中,Mistral Medium 3的性能达到甚至超过了Claude Sonnet 3.7的90%,但成本却显著降低(每百万Token的输入成本为0.4美元,输出成本为2美元)。
Mistral Medium 3的性能也超越了领先的开源模型,如Llama 4 Maverick和Cohere Command A等企业模型。
无论是API还是自主部署,Mistral Medium 3的成本都要比DeepSeek V3还低。
此外,Mistral Medium 3还可以部署在任何云上,包括四个GPU及以上的自托管环境。
顶级性能
Mistral表示,Mistral Medium 3的目标是成为一款性能顶尖的模型,尤其是在编码和STEM任务中表现突出,性能直逼那些规模更大、速度更慢的竞争对手。
从Mistral给出的表中可以看出Mistral Medium 3性能已经基本上超越Llama 4 Maverick和GPT-4o,接近Claude Sonnet 3.7以及DeepSeek 3.1的水平。
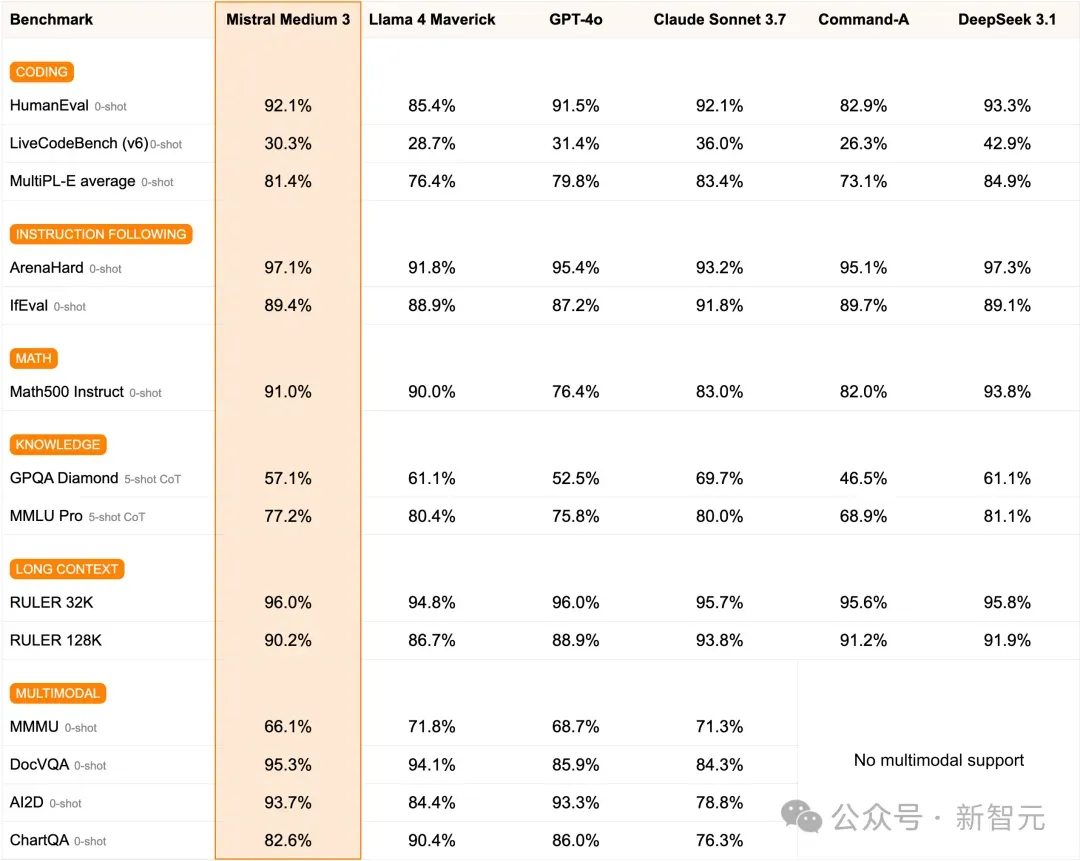
人工评估结果
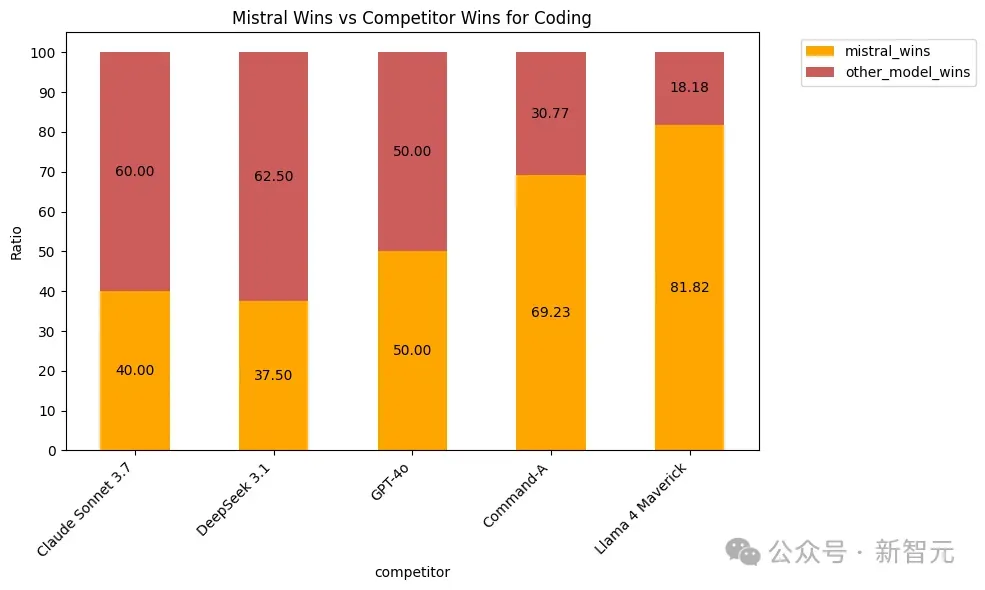
除了学术基准之外,Mistral还公布了第三方人工评估,后者更能代表真实世界的用例。
可以看到,Mistral Medium 3在编码领域表现出色,并且在各个方面都比其他竞争对手提供了更好的性能。
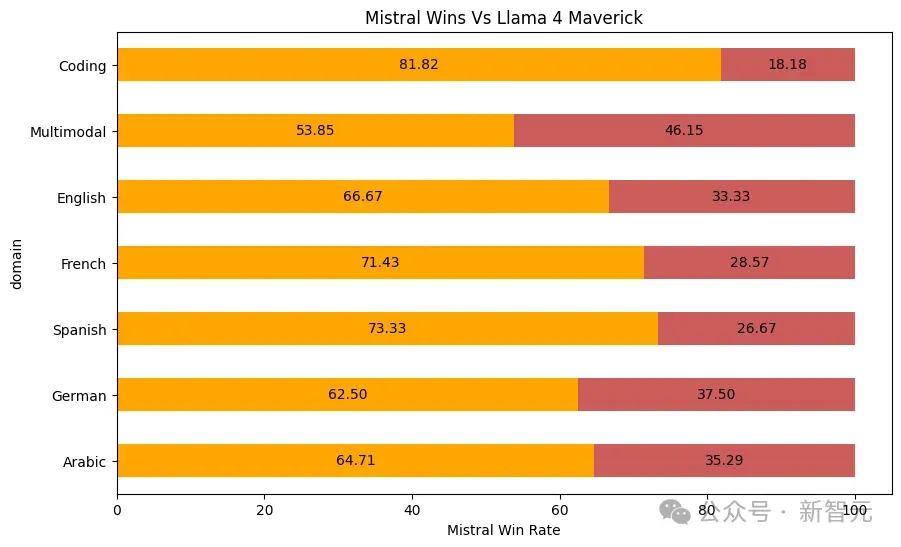
专为企业级应用打造
Mistral Medium 3在适应企业环境的能力方面优于其他SOTA模型。
在企业面临通过API进行微调,或从零开始自部署并定制模型行为的艰难选择时,Mistral Medium 3提供了一条将智能全面集成到企业系统中的途径。
Mistral还推出了由Mistral Medium 3模型驱动的Le Chat Enterprise,一款面向企业的聊天机器人服务。
它提供了一个AI智能体构建工具,并将Mistral的模型与Gmail、Google Drive和SharePoint等第三方服务整合。
这就可以解决企业面临的AI挑战,如工具碎片化、不安全的知识集成、僵化的模型以及缓慢的投资回报率等,为所有组织工作提供统一的AI平台。
Le Chat Enterprise很快将支持MCP协议,这是Anthropic提出的连接AI与数据系统和软件的标准。
One more thing…
Mistral还在博客中透露,虽然Mistral Small和Mistral Medium都已经发布,但在未来几周内,他们有一个「大」计划,也就是Mistral Large。
他们表示刚发布的Mistral Medium性能已经远胜Llama 4 Maverick等顶尖开源模型,Mistral Large的性能更加值得期待。
网友实测:就这?
号称超越Claude Sonnet 3.7的90%,Medium 3果然有这么强吗?
媒体和网友们立刻展开了实测。
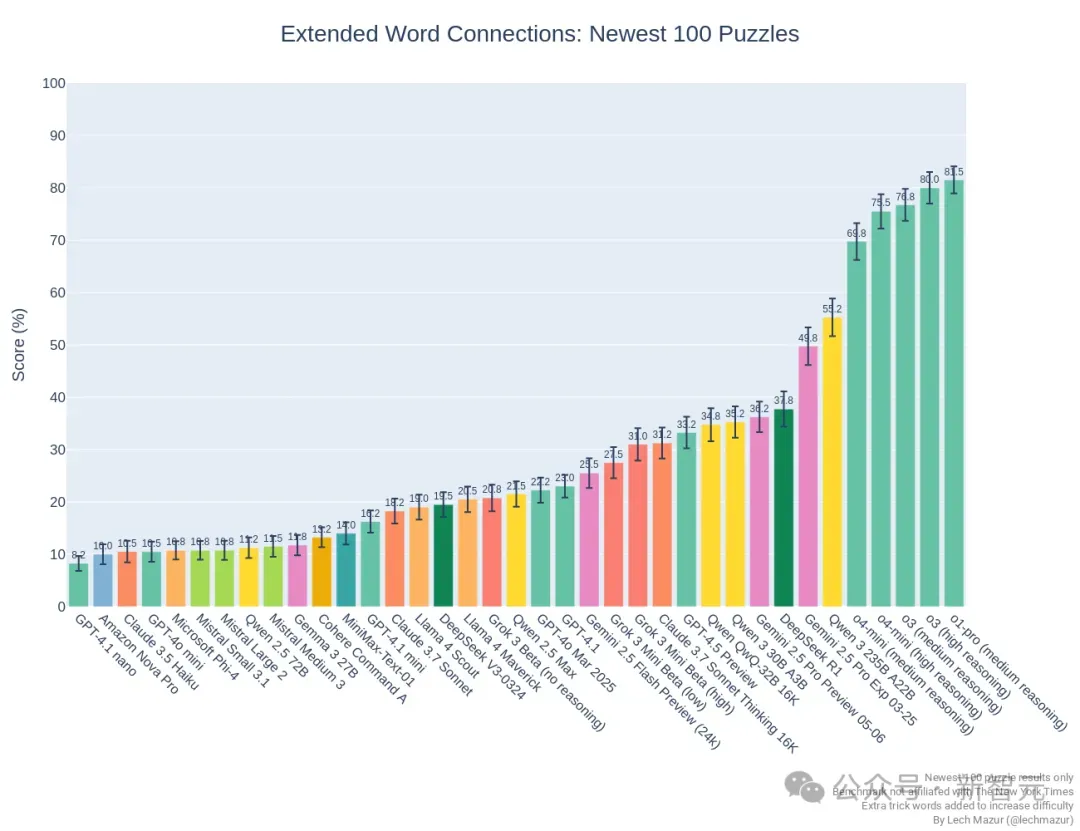
在基于《纽约时报》Connections栏目词汇分类题的评测中,Medium 3处于倒数的位置,几乎找不到它。
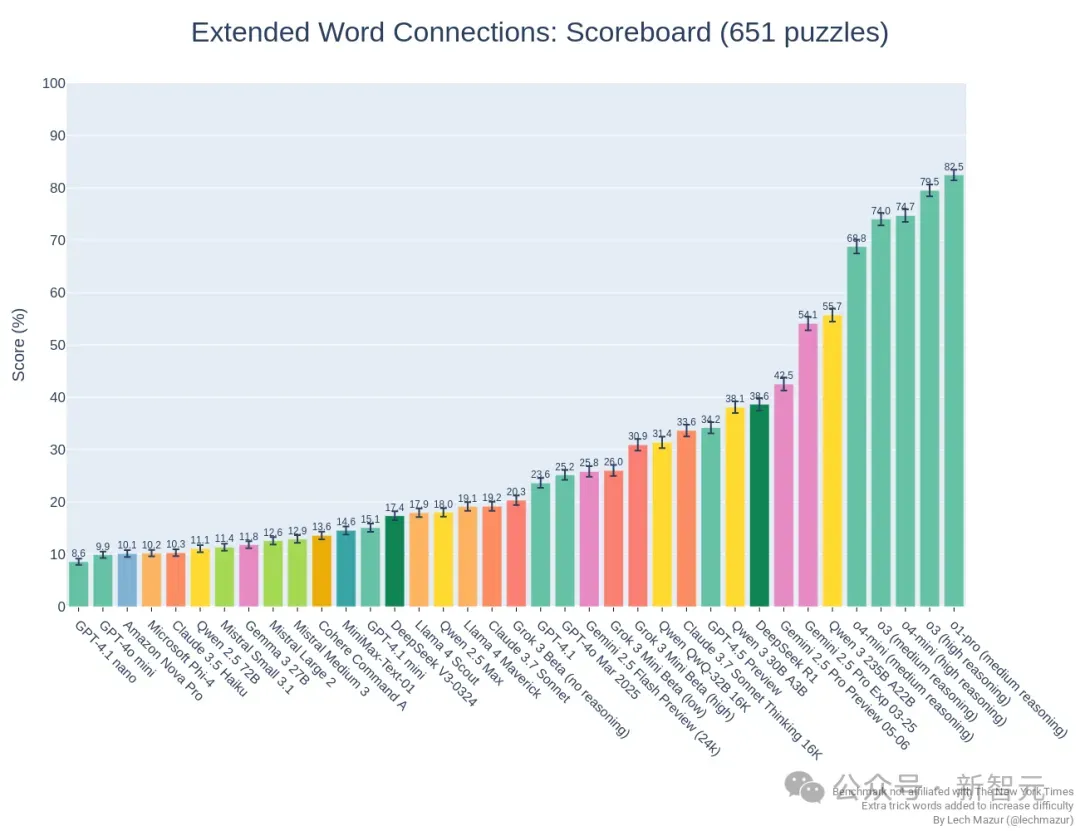
在全新的100题测评中,它在前排模型中也排不上号。
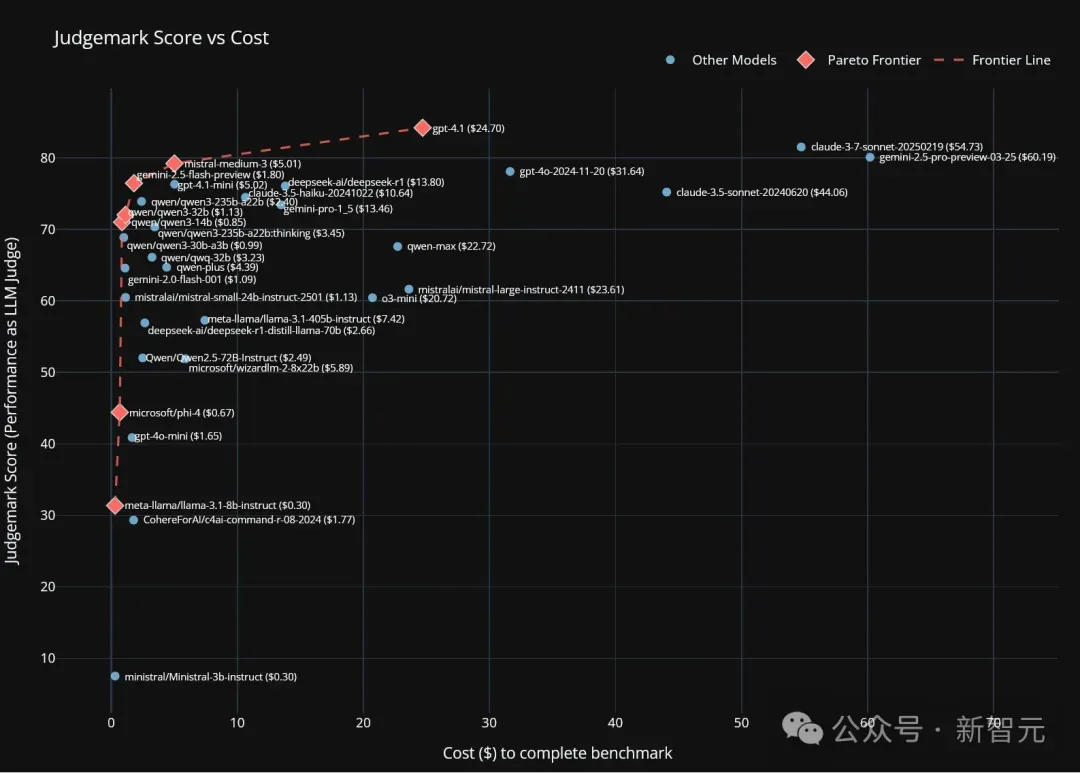
有人测试Medium 3后表示,它的写作能力还是老样子,没啥进步。不过在LLM评测中,它倒是处在帕累托前沿。

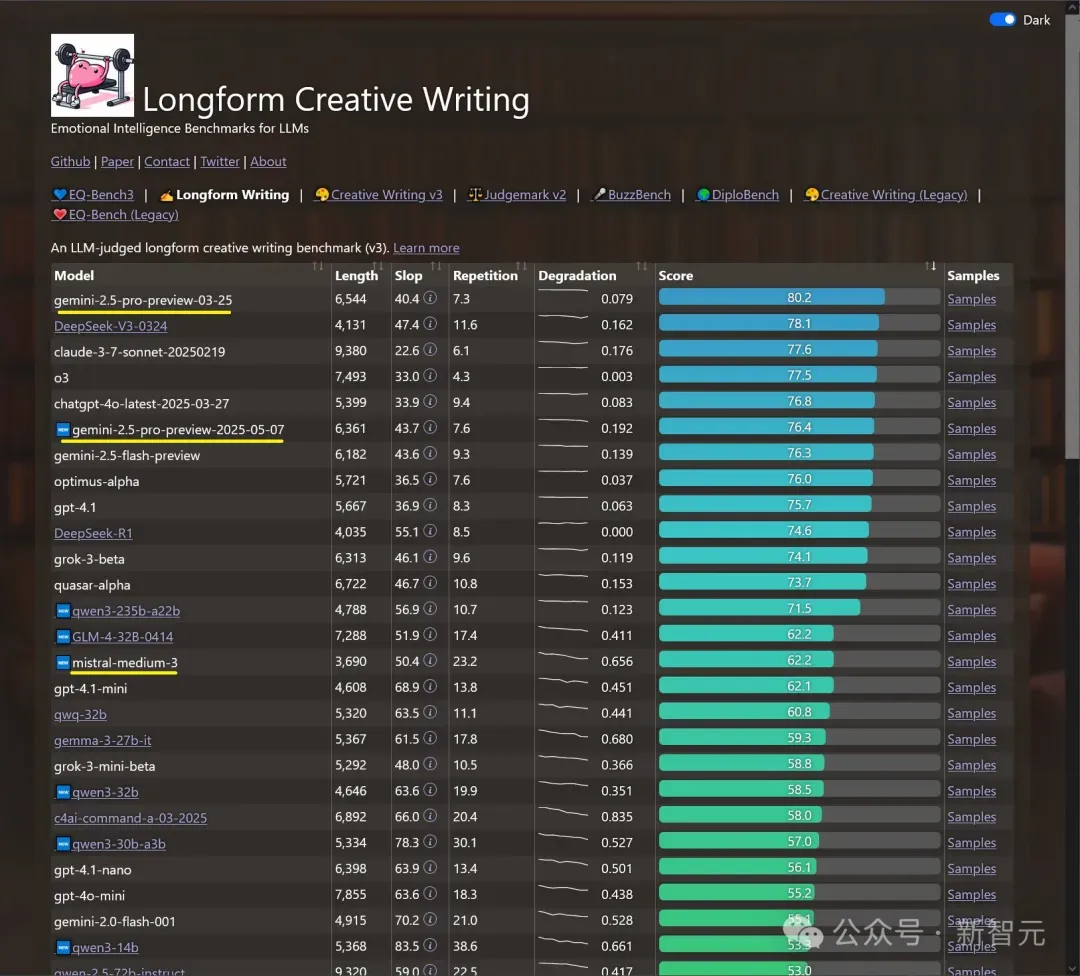
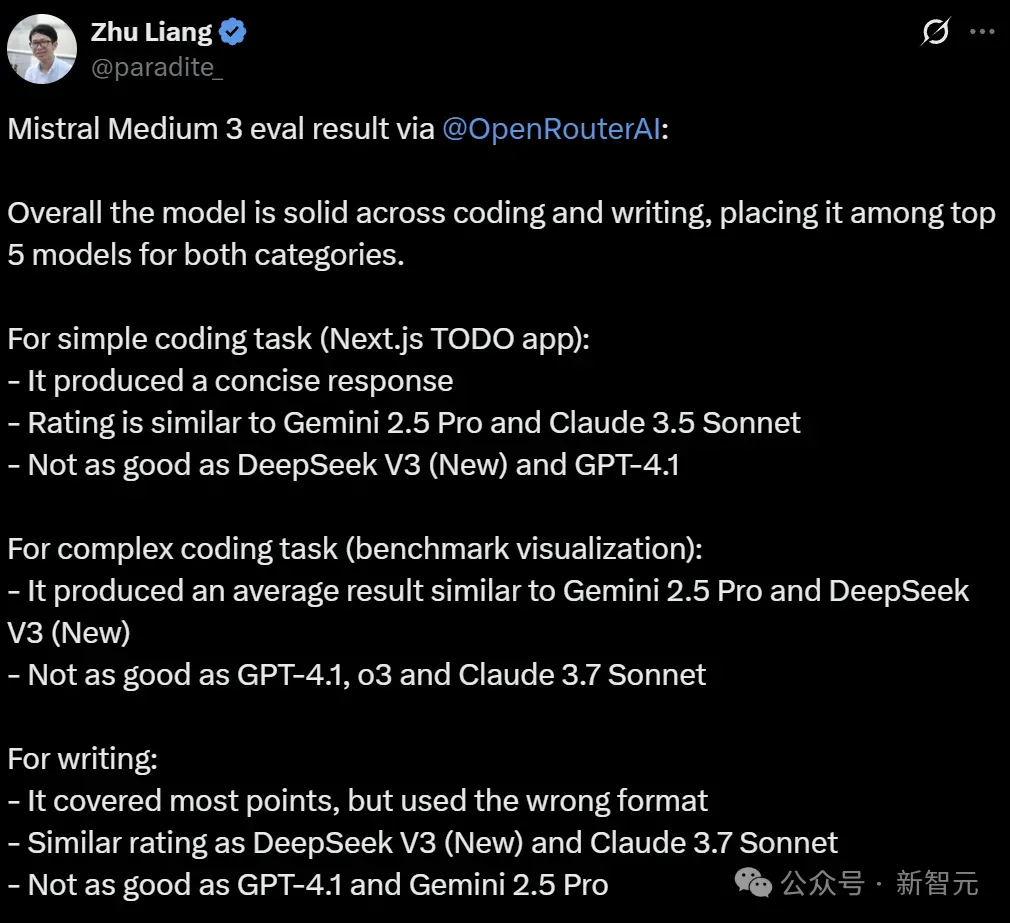
而Zhu Liang测试后发现,模型在代码编写和文本生成方面表现都很扎实,在这两项评测中都跻身前五。
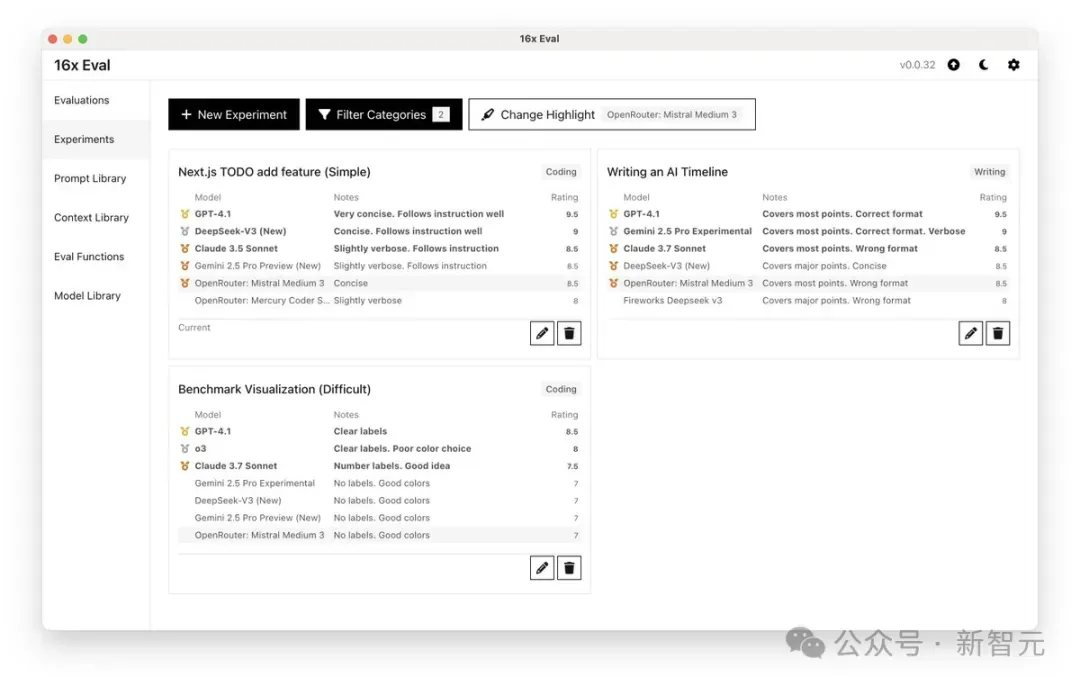
在简单编码任务(Next.js TODO应用)中:
- 它生成了简洁明了的回复
- 评分和Gemini 2.5 Pro、Claude 3.5 Sonnet差不多
- 逊于DeepSeek V3 (新) 和GPT-4.1
在复杂编码任务(基准测试可视化)中:
- 产生的平均结果与Gemini 2.5 Pro和DeepSeek V3(新)相似
- 不如GPT-4.1、o3和Claude 3.7 Sonnet
在写作上:
- 它的内容覆盖了大部分要点,但格式不正确
- 评分与DeepSeek V3 (新) 和Claude 3.7 Sonnet相近
- 不如GPT-4.1和Gemini 2.5 Pro
知名大佬「karminski-牙医」实测后发现,它的性能并不像官方吹得那么强。
建议我们不必下载,浪费流量和硬盘空间了。



