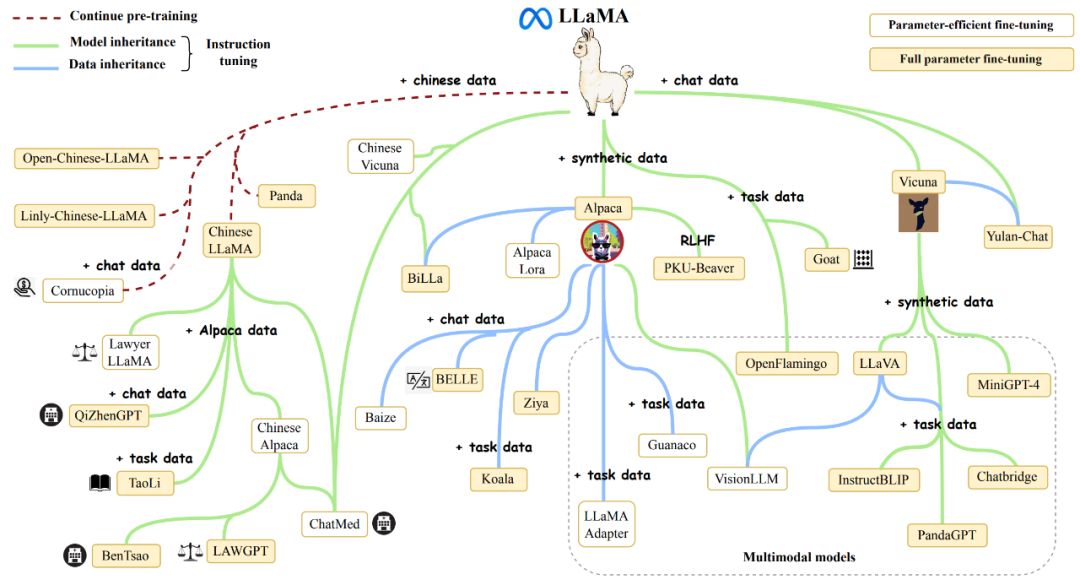
这一周来,Meta 开源的 Llama2 火遍了整个 AI 社区。
这不,连特斯拉前 AI 总监、年初重回 OpenAI 的 Andrej Karpathy 也坐不住了。他利用周末时间,做了一个关于 Llama2 的有趣项目 ——「llama2.c」。

GitHub 地址:https://github.com/karpathy/llama2.c
具体是什么呢?他表示「llama2.c」可以让你在 PyTorch 中训练一个 baby Llama2 模型,然后使用近 500 行纯 C、无任何依赖性的文件进行推理。并且,这个预训练模型能够在 M1 芯片的 MacBook Air 上以 fp32 的浮点精度、18 tok/s 的速度对故事进行采样。
Karpathy 介绍称,「llama2.c」的灵感来自 llama.cpp,后者由资深开源社区开发者 Georgi Gerganov 创建,可以在 MacBook 上使用 4-bit 量化运行第一代 LLaMA 模型。
对于「llama2.c」,它的训练代码由 nanoGPT 修改而来,用来训练 Llama2 架构的模型。核心是在如下 run.c 中编写 C 推理引擎,不过它目前并不是一个生产级库。下面是部分推理代码。
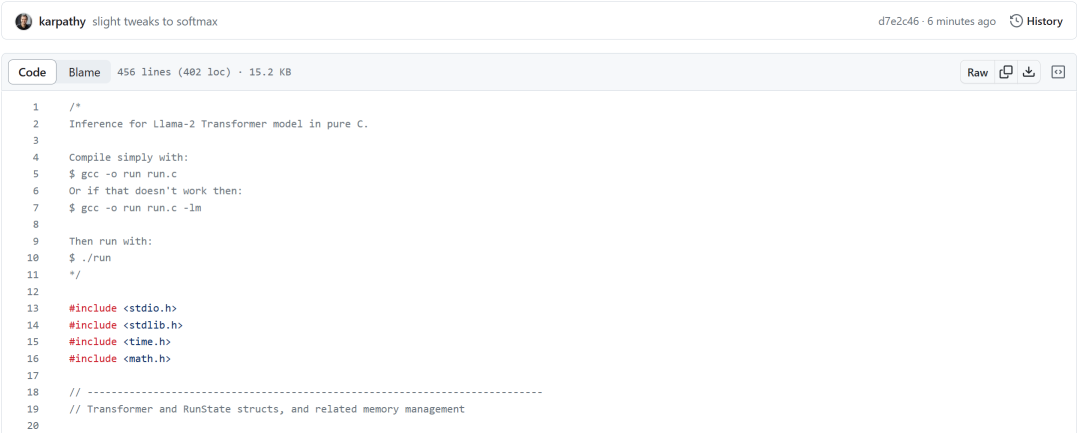
完整代码地址:https://github.com/karpathy/llama2.c/blob/master/run.c
结果令 Karpathy 非常惊讶,你可以在(M1)CPU 的纯单线程 C 语言中以 fp32 的交互速率来推理更小(O (~10MB))的模型。
当然,他表示自己没有尝试对最小规模的 Llama2 模型(70 亿参数)进行推理,他预计速度会非常慢。

目前,Karpathy 在 M1 MacBook Air 上,能够以 fp32 的浮点精度、100tok/s 的速度对 15M 参数的 288 6 层 6 头的模型进行推理。
之后,Karpathy 对项目进行了更新,使用「-O3」进行编译可以将 M1 MacBook Air 上的 tok/s 从 18 增加到了 98。这还没完,使用「-funsafe-math-optimizations」进行编译更是将 tok/s 增加到 315。他表示,只要在 gcc 命令中包含更多字符,速度就能提升 17.5 倍。
也许你要问了,这个项目有什么意义呢?在 Karpathy 看来,在一些较窄的领域(如生成故事)中,人们可以使用极其小的 Transformers 来做有趣的事情。
因此,这种可以移植的纯 C 实现或许非常有用,我们可以通过简单的方法高交互速率地运行合理大小的模型(几千万参数)。
有网友对「llama2.c」的开发过程很感兴趣,很多人都会有这样的想法,只是在等待合适的时机,他们没意识到几天内就可以完成很多工作。
Karpathy 回复称,自己对利用 float32 权重块及其上的微小推理代码来生成故事非常感兴趣。所以他花了整个周六的时间(从起床一直到睡觉)来写代码,然后让项目工作。
此外,Karpathy 还表示自己将出讲解视频。
项目详情
到目前为止,「llama2.c」项目已经在 GitHub 上获得了 1.6k 的 Stars,并在快速增长。
下面简单介绍一下该项目的运行步骤。
为了使用纯 C 语言运行一个 baby Llama2 模型,你需要以下的模型检查点。下载 TinyStories 数据集上训练的一个 15M 参数的模型(大约 58MB),并将它放入默认检查点目录中。
wget https://karpathy.ai/llama2c/model.bin -P out然后编译并运行 C 代码。
gcc -O3 -o run run.c -lm
./run out/model.bin请注意这只是原始 tokens 流。遗憾的是,我们现在必须通过一个简单的转换封装器来运行 C 代码(只有 30 行)。
pip install sentencepiece
python run_wrap.py最后你将看到文本流。在 Karpathy 的 M1 MacBook Air 上,运行速度约 100 tok/s,对于超级原生的 fp32 单线程 C 代码来说还不错。示例输出如下所示。

更多细节请查看原项目。