编辑 | 云昭
出品 | 51CTO技术栈(微信号:blog51cto)
Pytorch 赢了。
大家可能没注意到,现在每一款与你互动的Chatbot,背后运行的都是 PyTorch。可以说,它已经成为了主流LLM研发链路中事实上的标准。
首先,不管是大洋彼岸的OpenAI、Anthropic,还是国内的通义千问、智谱、月之暗面,他们推出的大模型或开源实现,都提供或偏好Pytorch框架。
OpenAI早在2020年就官方声明中就明确表示将研究标准化在 PyTorch 平台上,来提高研究迭代效率。
 图片
图片
而从 OpenAI 出走的 Anthropic,也公开披露了对于 Pytorch 框架的偏好,甚至其研究团队使用 PyTorch 来定义、训练和推理他们的 Transformer 模型(包括 Claude 1~3 系列)。更夸张地是,Claude 甚至从未发布过TF版本,也没有兼容的推理接口。其生态完全围绕 PyTorch 和 CUDA 展开。
 图片
图片
甚至拥有TensorFlow、JAX 的谷歌,也毫不避讳地在自己官方文档中将推出 Gemma 运行在 Pytorch 上的教程。
 图片
图片
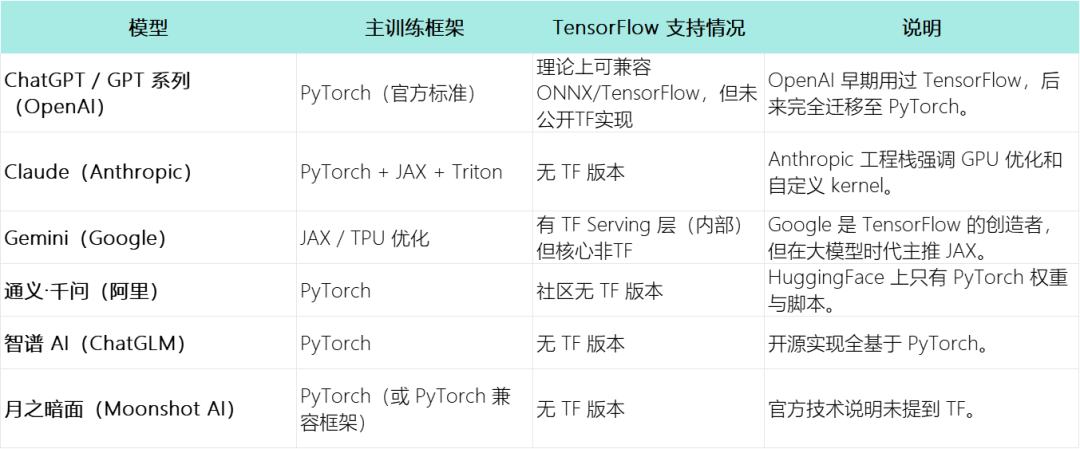
国内的大模型顶流们,亦是如此。阿里的Qwen、智谱的ChatGLM、月暗的 Kimi,社区上没有发现TF版本,甚至官方技术说明都为提到TF。
 图片
图片
可以说现在除了谷歌系模型(也用最新的JAX,而不是TF),几乎所顶流大模型公司都在采用Pytorch作为首选。而 TensorFlow 目前更多“活”在移动端、课本和教程视频上。
那么,为什么 Pytorch 赢了?
这个问题,相信每一位在用Pytorch的朋友,都有自己的答案。
但要回答好这个问题,没有比Pytorch最早的参与成员来回答更合适了。
上周,于旧金山举行的 PyTorch 2025 年大会 上, PyTorch 基金会技术顾问委员会的主席 Luca Antiga 发表了事关 Pytorch 长远发展的重要观点。Luca 不仅是最早参与撰写 PyTorch 论文的团队成员之一,还共同编写了《Deep Learning with PyTorch》一书。
这就为大家梳理下 Luca 的发言内容。
研究者友好的“Pythonic”设计
拥有生物医学工程学术背景的 Luca 指出,PyTorch 之所以能迅速流行,是因为它对研究者非常友好。许多早期用户都是学术界的研究人员,后来他们进入工业界,也将 PyTorch 带了进去。
它非常 Pythonic。在过去,虽然很多框架号称用 Python,但你实际上需要写一种‘元语言’,让代码和问题本身之间多了一层隔阂,调试也更困难。
而 PyTorch 在这方面是革命性的,它把 Python 的易用性、快速迭代能力,以及那种‘先干起来’的精神,带进了神经网络、反向传播和 GPU 计算的世界。
从神经网络到生成式 AI,PyTorch 始终在牌桌上
PyTorch 诞生之初,行业的重心还在神经网络,主要用于图像识别或情感分析。直到 ChatGPT 出现,生成式 AI 才让公众真正意识到 AI 的潜力。但 Antiga 认为,PyTorch 从未“过时”。
无论经历了多少次技术革命,你总能看到 PyTorch 的身影。
当然,还有像 JAX 这样的强劲对手,但相比之下,PyTorch 已经发展成一整个产业的基石,它支撑起整个生态。
如今,PyTorch 不再只是训练模型的工具,它也成为 模型推理阶段的核心。
看看现在最流行的推理框架——vLLM、SGLang——它们都在用 PyTorch,而且是用在生产环境里的。
今天你与任何一个聊天机器人互动时,很可能后台运行的就是 PyTorch。
强化学习让 PyTorch 再次走在前列
近来 PyTorch 人气再度攀升的另一个原因,是 强化学习 的广泛应用。强化学习通过“奖励正确行为、惩罚错误行为”的方式,来微调预训练的大语言模型(LLM),而 PyTorch 对这类任务也特别契合。
强化学习会鼓励模型在面对环境时,做出能带来更大奖励的行动。
PyTorch 的灵活性非常适合在这种动态、交互式的场景下使用。
PyTorch 基金会的最新动向
至于 PyTorch 基金会本身,值得注意的是,几个月前它刚开始接纳更多项目,首先是 vLLM 和 DeepSpeed。如今,随着分布式计算框架 Ray 的加入,基金会旗下已有四个重要项目。
但 Luca 强调,基金会并不打算变成一个“巨型伞形组织”。
我最关心的是生态系统里的用户——他们在进入由 PyTorch 基金会“背书”的生态时,会经历怎样的旅程?
我的目标是让他们能成功。
个人最关心的AI突破方向:LLM微型化
如今,大模型狂奔向前,哪些研究方向值得关注呢?
Luca非常笃定地表达了自己的看法:现在的大模型还是太笨重了,虽然能用,但成本消耗巨大。
我一直觉得,人类其实在做一件惊人的事:我们在训练一种“类比机器”,一种不需要精确指令、能通过模式和类比自我推理的机器。
但我们现在造的这台“飞行机器”,更像是靠一堆齿轮和螺旋桨的庞然大物——能飞,却笨重。真正的“飞行证明”其实是鸟类。
人类大脑才是我们真正的“对照组”——我们的大脑在思考时消耗的能量极低,却能完成复杂的推理。
未来的突破方向,是能否把LLM那种庞大结构“微型化”,让模型能从头到尾学习,而不需要如此多的显存与能量。
PS:这一点毫不夸张,现在就连个体开发者都可能在代码工具上开销达上万美元。
“这让我非常着迷。我不确定PyTorch基金会是否会沿这个方向演进,但我个人对此充满热情。”
对于这个方向,Luca 也正在身体力行地做出了很多投入。Luca 还是 Lightning AI的首席技术官,他们团队提供了一个PyTorch友好的训推平台,其中很多客户更大的诉求就是:想尽可能优化每一份资源的使用。
所以,我们非常关注训练与推理的全链路优化,从GPU核心层到数据加载、任务调度、流式处理,每一层都可能成为瓶颈。
有时你卡在数据加载,有时是计算没有并行,有时是模型本身没调优。要真正优化性能,得从端到端去分析。
我们也希望帮助开发者提高算力利用率,让他们能在研发之外,用得其所。
好了,文章到这里结束了。目前,PyTorch 已经成为全球 AI 模型的“操作系统”。无论是研究者造模型,还是企业部署模型,底层框架首选,当之无愧。
大家如何看待Pytorch的王者之路呢?