
尹博:NUS 计算机工程硕士生、LV Lab 实习生,研究方向是生成式 AI,及参数高效率微调(PEFT)。
胡晓彬:NUS LV Lab Senior Research Fellow, 研究方向是生成式 AI,MLLM Agent 等。
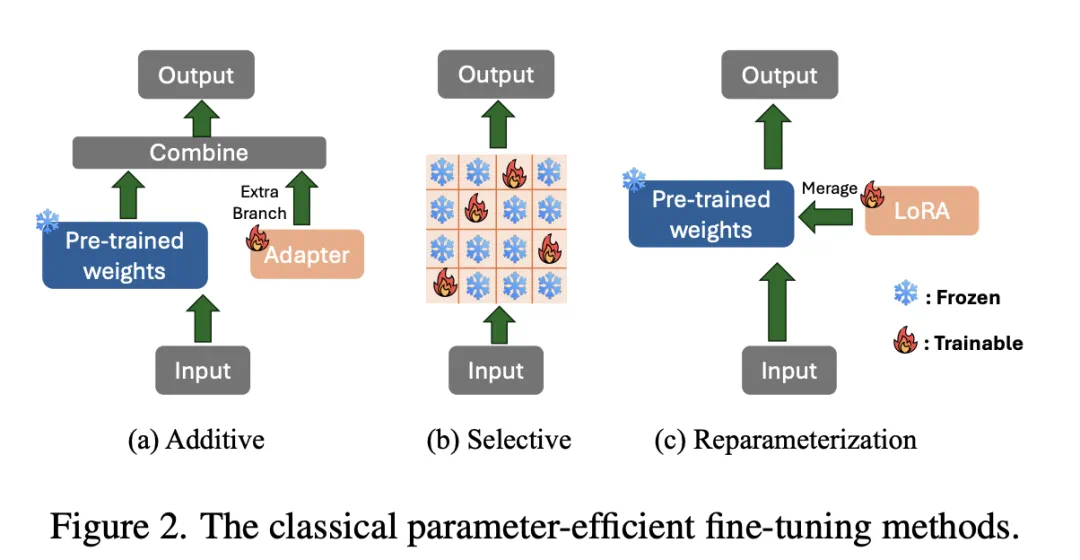
在大模型时代,参数高效微调(PEFT) 已成为将 Stable Diffusion、Flux 等大规模扩散模型迁移至下游任务的标准范式。从 LoRA 到 DoRA,社区不断探索如何用更少的参数实现更好的适配。
然而,现有的微调方法(如 LoRA、AdaLoRA)大多采用「静态」策略:无论模型处于去噪过程的哪个阶段,适配器(Adapter)的参数都是固定不变的。这种「一刀切」的方式忽略了扩散生成过程内在的时序物理规律,导致模型在处理复杂结构与精细纹理时往往顾此失彼。
针对上述问题,新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。
FeRA 摒弃了传统的静态微调思路,通过实时感知潜空间(Latent Space)的频域能量分布,动态调度不同的专家模块。实验结果显示,FeRA 在 SD 1.5、SDXL、Flux.1 等多个主流底座上,于风格迁移和主体定制任务中均实现了远超 baseline 的生成质量。

论文地址: https://arxiv.org/abs/2511.17979
项目主页: https://github.com/YinBo0927/FeRA
研究背景:静态微调与动态生成的错配
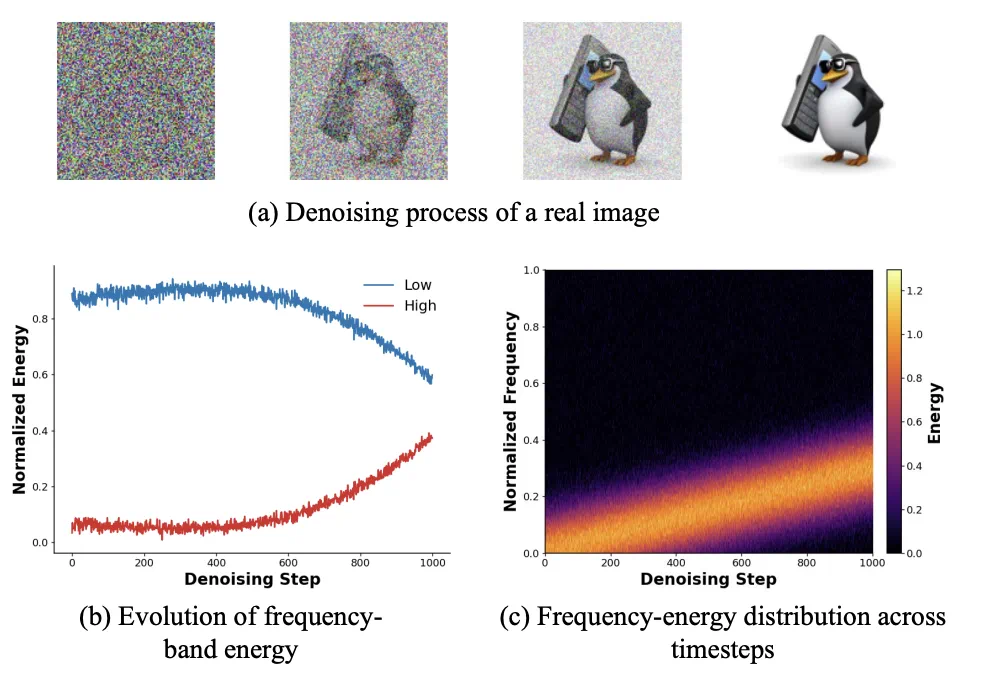
扩散生成的「频域时序性」
扩散模型的去噪过程(Denoising Process)本质上是一个从无序到有序的物理演变。研究团队通过对中间层特征的频谱分析发现,这一过程并非各向同性,而是具有鲜明的阶段性特征:
生成初期(高噪声): 模型主要致力于恢复图像的低频能量(如整体构图、轮廓)。
生成后期(低噪声): 重心逐渐转移至高频能量(如纹理、边缘细节)。
现有方法的局限
然而,LoRA 等主流 PEFT 方法在所有时间步(Timestep)上应用相同的低秩矩阵。这意味着,负责「画轮廓」的参数和负责「描细节」的参数是完全耦合的。这种目标错配(Misalignment)导致了计算资源的浪费:模型不得不在有限的参数空间内权衡结构与细节,往往导致生成的图像要么结构崩坏,要么纹理模糊。
因此,设计一种能够感知当前生成阶段,并「按需分配」算力的动态微调机制,成为突破性能瓶颈的关键。
方法介绍:FeRA 框架
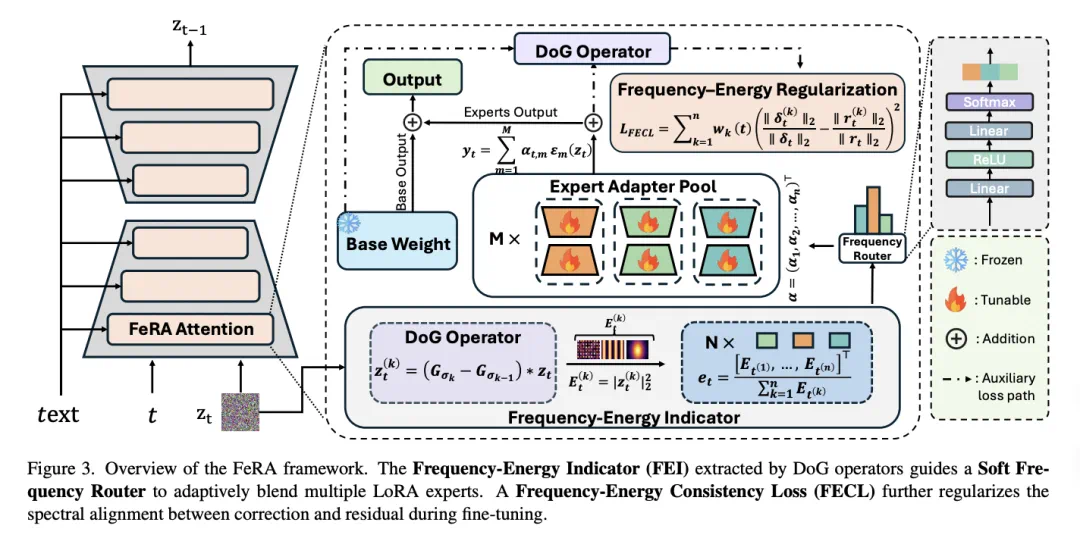
为了解决上述痛点,研究团队提出了 FeRA (Frequency-Energy Constrained Routing)。该框架包含三个核心组件,形成了一个感知 - 决策 - 优化的闭环:
频域能量指示器 (Frequency-Energy Indicator, FEI)
这是 FeRA 的「眼睛」,不同于以往方法仅依赖离散的时间步(Timestep)作为条件,FeRA 利用 高斯差分 (Difference-of-Gaussians, DoG) 算子,在潜空间直接提取特征的频域能量分布。
它将特征分解为多个频带。
实时计算各频带的归一化能量值,形成一个连续的、物理可解释的能量向量。
软频域路由器 (Soft Frequency Router)
这是 FeRA 的「大脑」,基于 FEI 提供的能量信号,路由器通过一个轻量级网络动态计算不同 LoRA 专家 (Experts) 的权重。
低频主导时: 系统自动激活擅长结构生成的专家分支。
高频主导时: 平滑过渡到擅长纹理细节的专家分支。 这种机制实现了参数的解耦,让不同的专家专注于其擅长的频域范围。
频域能量一致性正则化 (FECL)
这是 FeRA 的「稳定器」,为了防止微调过程偏离原本的生成轨迹,团队引入了 FECL (Frequency-Energy Consistency Loss)。该损失函数强制要求:LoRA 产生的参数更新量(Update),其在频域上的能量分布必须与模型原本的残差误差(Residual Error)保持一致。这确保了微调过程「指哪打哪」,极大地提升了训练稳定性。
实验验证:从风格迁移到主体定制
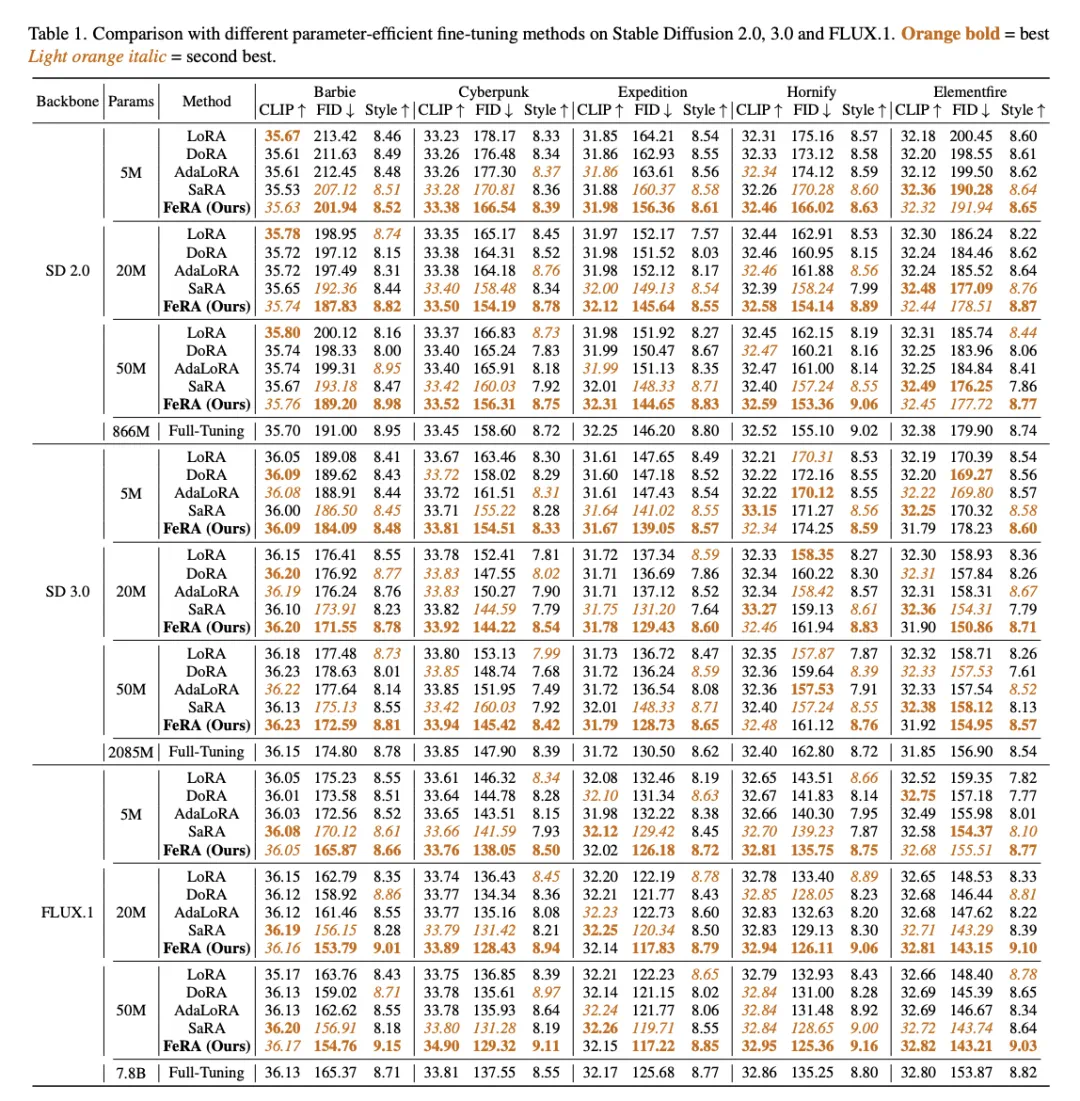
研究团队在 Stable Diffusion 1.5、2.0、3.0、SDXL 以及最新的 FLUX.1 等多个主流底座上进行了广泛测试 。实验涵盖了风格迁移(Style Adaptation)和主体定制(DreamBooth)两大任务。
风格迁移:FID 与 CLIP 的双赢
在 Cyberpunk, Watercolor 等多种风格数据集上,FeRA 在 FID(图像质量) 、CLIP Score(语义对齐)和 Style(MLLM 评分) 上均取得了最优或次优的成绩。

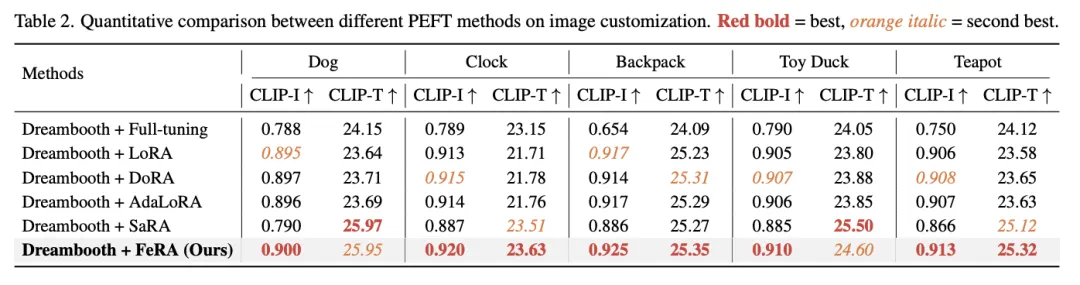
主体定制:更懂你的 Prompt
在 DreamBooth 任务(如让特定的狗游泳、让特定的茶壶放在草地上)中,FeRA 展示了惊人的文本可控性。
痛点解决: 传统方法容易过拟合主体(Identity),导致无法响应新的背景提示词(Prompt)。
FeRA 表现: 在 CLIP-T(文本对齐度)指标上,FeRA 显著优于 DoRA 和 AdaLoRA 。这意味着它不仅记住了「这只狗」,还能听懂指挥让它「去游泳」。

总结
总的来看,目前的扩散模型微调仍以静态参数叠加为主,在处理复杂的多频段信息时存在天然瓶颈。
LV Lab 颜水成团队 提出的 FeRA 框架,通过引入频域第一性原理,将微调从「参数层面的分解」推进到了「机制层面的对齐」。FeRA 证明了:顺应生成过程的物理规律,利用频域能量进行动态路由,是实现高效、高质量微调的关键路径。
这一工作不仅刷新了各项 SOTA 指标,更为未来扩散模型在视频生成、3D 生成等更复杂任务中的微调提供了极具价值的新思路。


