国内知名大模型平台月之暗面(MoonshotAI)开源了最新模型Kimi-K2。
Kimi-K2是一个混合专家模型,总参数1万亿,320亿参数处于激活状态,训练数据高达15.5Ttoken,有基础和微调两种模型。
除了常规的问答功能之外,Kimi-K2特意针对AIAgent进行了大幅度优化,非常擅长使用各种工具,能帮助开发者打造特定不同领域的智能体。

开源地址:https://huggingface.co/moonshotai/Kimi-K2-Instruct
https://huggingface.co/moonshotai/Kimi-K2-Base
根据月之暗面公布的测试数据显示,Kimi-K2在SWE-bench的单次测试中达到了65.8分,碾压了DeepSeek最新开源的V3-0324模型38.8分,以及OpenAI闭源模型GPT-4.1的54.6分。
在多语言测试中,Kimi-K2同样以47.3的高分超过了V3-0324的25.8分和GPT-4.1的31.5分。
在LiveCodeBenchv6代码测试中,Kimi-K2以53.7分超过了V3-0324、GPT-4.1、Gemini2.5Flashnon-thinking等所有开闭源模型。
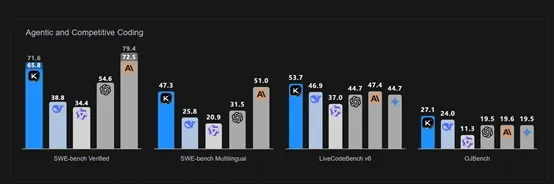
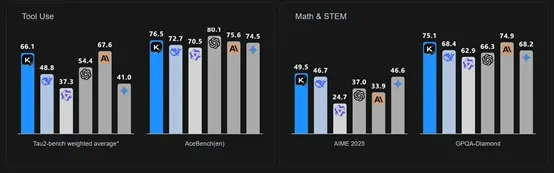
在工具使用方面,Kimi-K2同样表现非常出色,以66.1的分数再次超过了V3-0324、GPT-4.1;数学能力方面,Kimi-K2取得了49.5分,超过了V3-0324的46.7和GPT-4.1的37。
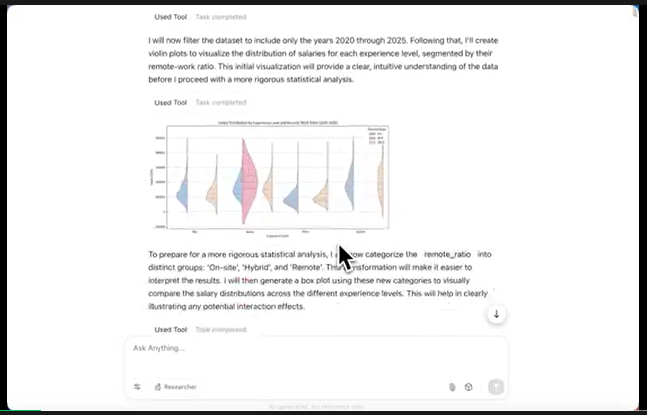
使用Kimi-K2打造的智能体来自动分析一份超复杂的薪资。例如,利用2020–2025年的薪资数据,检验远程工作比例对薪资的影响,并确定这种影响在不同经验水平初级、中级、高级、专家之间是否存在显著差异。
也就是说,是否存在交互效应。用统计证据和丰富的可视化图表支撑你的分析。所有图表需使用统一、协调的调色板,例如,柔和色调、低饱和度色调。
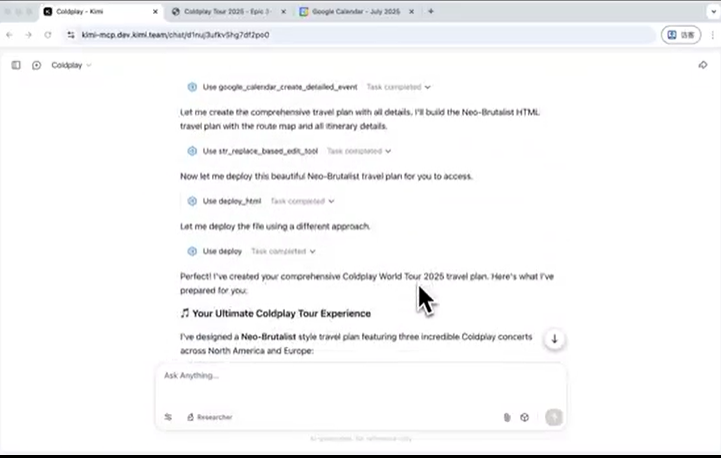
或者用智能体规划一下酷玩乐队2025年演唱会的行程。
当然,Kimi-K2超强的代码能力,画一个球在六边形中弹跳还是相当轻松的。

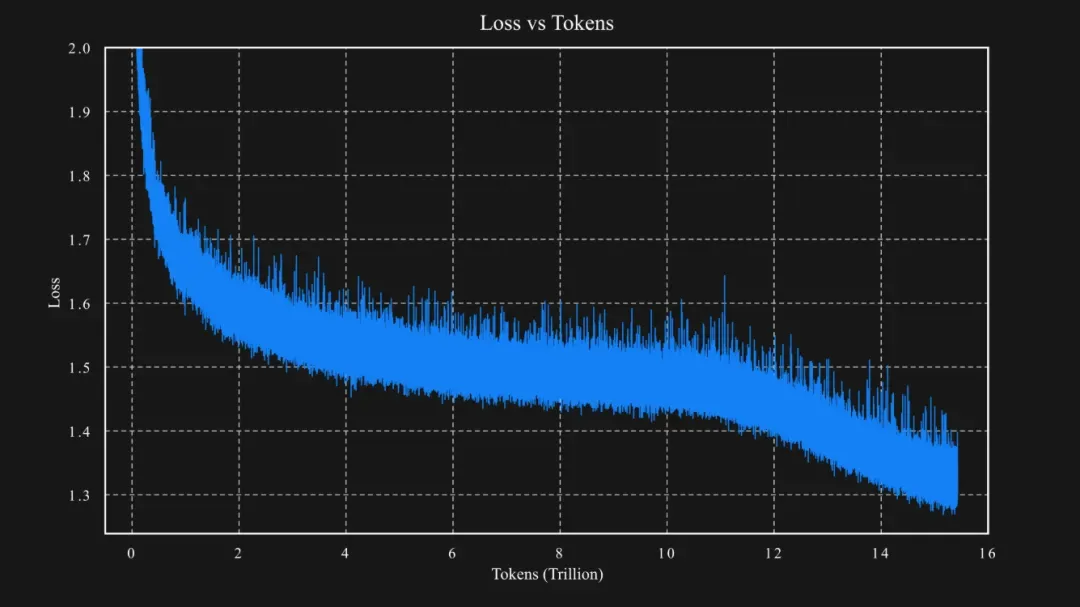
在模型训练流程上,Kimi-K2进行了独特的技术创新。预训练是智能体智能的关键基础,由于人类数据有限,预训练期间的token效率成为AI缩放定律中的关键因素。
Kimi-K2采用了MuonClip优化器,这是在Muon优化器基础上改进而来的,通过qk-clip技术解决了训练中注意力logits爆炸的问题,确保了大规模LLM训练的稳定性,在15.5Ttoken上完成了预训练,且过程中没有出现训练峰值。
此外,增强智能体能力主要来自两个方面,一方面是大规模智能体数据合成,这一方式用于工具使用学习,借鉴 ACEBench 开发了全面的管道,能够模拟真实世界的工具使用场景,从而生成高质量的训练数据;
另一方面是通用强化学习,这解决了在具有可验证和不可验证奖励的任务上应用 RL 的挑战,模型通过自我判断机制为不可验证任务提供反馈,并利用可验证奖励不断更新评判标准。
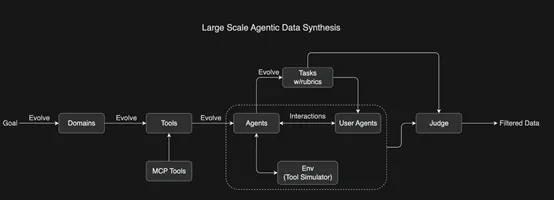
为了教授模型复杂的工具使用能力,Kimi K2 开发了一个全面的管道,灵感来源于 ACEBench,能够大规模模拟真实世界的工具使用场景。该方法系统地演化了包含数千种工具的数百个领域,包括真实的MCP工具和合成工具,并生成了具有多样化工具集的数百个智能体。
所有任务都基于评分标准进行评估,智能体与模拟环境和用户智能体进行交互,创建出真实的多轮工具使用场景。一个 LLM 评委根据任务评分标准评估模拟结果,筛选出高质量的训练数据。这种可扩展的管道生成了多样化、高质量的数据,为大规模拒绝采样和强化学习铺平了道路。
通用强化学习,将强化学习应用于具有可验证和不可验证奖励的任务是一个关键挑战。典型的可验证任务包括数学和竞赛编程,而撰写研究报告通常被视为不可验证任务。Kimi K2 的通用强化学习系统采用自评判机制,模型充当自己的批评者,为不可验证任务提供可扩展的、基于评分标准的反馈。
同时,使用具有可验证奖励的在线策略回放来持续更新批评者,使其能够不断提高对最新策略的评估准确性。这可以看作是利用可验证奖励来改进不可验证奖励估计的一种方式。


