编辑 | 伊风
出品 | 51CTO技术栈(微信号:blog51cto)
起猛了,连老电脑都能跑智谱家新一代的 SOTA 模型了!
一篇来自技术人 Simon Willison(Python 知名 Web 框架 Django 的共同创始人)的实测文章,在 Hacker News 上引发热议:
“我 2.5 年高龄的旧笔记本,现在不仅能在本地跑千亿参数模型,甚至还能用它写出一款完整的 JavaScript 太空入侵者游戏。”
 图片
图片
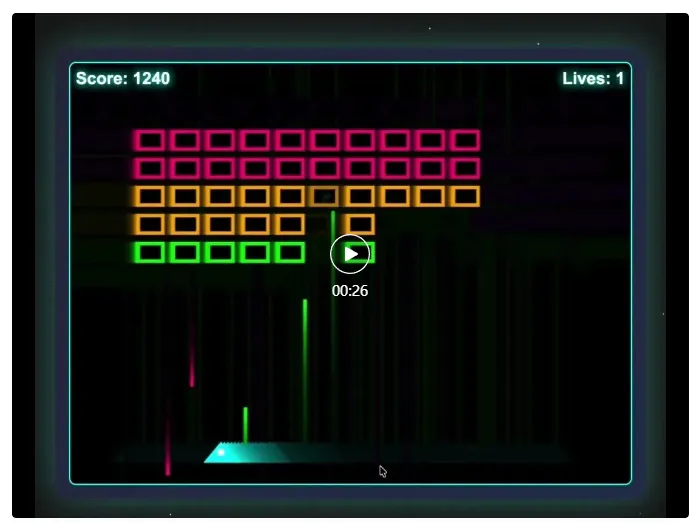
这个模型,正是昨天新鲜出炉的 GLM-4.5 系列。
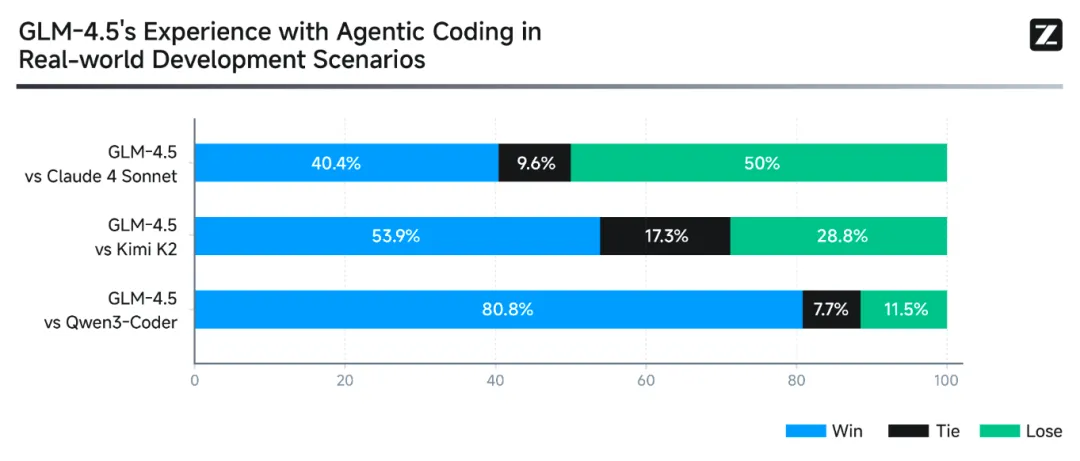
虽然不像 Qwen Coder 那样专门为编程打造,但根据官方基准测试, GLM-4.5在代码生成上的表现已经逼近 Claude Sonnet 4,属于真正意义上“会写代码的大模型”。
 图片
图片
Simon 所用的,是其中参数最少的版本 GLM-4.5 Air:
参数量依然高达 1060 亿,原始模型体积高达 205.78GB。
为了让它能在普通高配笔记本上也能运行,开发者 Ivan Fioravanti 特地制作了一个 3bit、仅 44GB 的量化版本,专为 MLX 框架优化,刚好能在 64GB 内存的 MacBook Pro 上跑起来。
模型地址:https://huggingface.co/mlx-community/GLM-4.5-Air-3bit
这意味着更多普通开发者,也能在本地运行一个千亿参数级的模型了。
Simon 的感叹也很直接:
本地跑大模型的拐点,真的来了!
他回忆道:
“两年前我刚试用 LLaMA,从没想过同一台笔记本,有朝一日能流畅运行像 GLM 4.5 Air、Mistral 3.2 Small、Gemma 3、Qwen 3 这些拥有强大能力的模型。”
一台不算新的笔记本 + 一个免费开源模型,就能跑出完整游戏代码。
那么,Simon 是如何在有限算力下实现这一切的?继续往下看。
1.一次生成完整游戏,无需修改!3bit 模型的实战表现令人惊艳
即使被压缩到 3bit、仅 44GB,GLM-4.5 Air 依然保留了完整的 1060 亿参数——这也是它能跑出完整 JavaScript 游戏的底气所在。
作者给出的提示词相当简洁:
写一个实现《太空侵略者》游戏的 HTML 和 JavaScript 页面
模型思考片刻后,生成了一段完整的代码,结构清晰、逻辑自洽
开头的系统提示也很“专业”:
<think>用户想让我用 HTML、CSS 和 JavaScript 创建一个《太空侵略者》游戏。我需要实现以下功能:
玩家飞船:能左右移动并发射子弹
敌方入侵者:成编队移动并反击
分数追踪 生命值/健康系统
游戏结束条件 [...]
接着就是完整的 HTML 与 JS 代码,直接可运行,不用修改一行。
调试输出如下:
- 提示词:14 tokens,生成速度 14.095 tokens/s
- 生成内容:4193 tokens,生成速度 25.564 tokens/s
- 峰值内存占用:47.687 GB
这个速度在本地部署模型中相当优秀,接近一些云端托管模型的实际表现(尤其考虑到官方所给的速度数据通常是在零延迟的理想环境下测得)。
内存使用上接近 48GB,意味着一台 64GB 内存的机器可稳稳支持——对本地推理来说,已经非常亲民。
作为对比,2024 年中发布的 LLaMA 3.1 70B 在推理阶段通常需要 350GB–500GB 的 GPU 显存,加上 64GB–128GB 的系统内存,几乎是“服务器级别的门槛”。
作者还测试了一个彩蛋级 benchmark——用这个 3bit 小模型生成一张“骑自行车的鹈鹕”的 SVG 图像。提示词是:
“生成一张鹈鹕骑自行车的 SVG 图像”
生成效果虽然有些“抽象主义”,但不难看出这是一只“云朵风格”的鹈鹕,骑着一辆结构稍微残缺了些但能看懂的自行车。
这说明,尽管精度远不及“满血版 GLM‑4.5”,但本地模型在多模态生成上依然具备可操作性。
上图为本地跑的GLM-4.5 Air生图,下图为GLM-4.5满血版生图👇
 图片
图片
2.指南:作者是如何运行GLM-4.5 Air模型的
用的是 mlx-lm 库的主分支(因为需要包含对 GLM4 MoE 的支持),通过 uv 启动:
复制在 Python 解释器里,用标准的 MLX 模型运行方式:
复制模型权重会下载到本地 ~/.cache/huggingface/hub/models--mlx-community--GLM-4.5-Air-3bit 文件夹,总计 44GB。
然后:
复制这样模型就在本地运行了。
3.网友:别被大模型叙事带偏了!低估了旧硬件 + 量化的潜力
作者Simon 总结说:
回顾一下,几乎所有 2025 年发布的新模型都在大幅增强编程能力——而这条路线,已经结出硕果——这些本地模型现在真的非常强大。
还是两年前的那台笔记本,但它不再是 LLaMA 1 的试验田,而是能稳定跑起 GLM 4.5 Air、Mistral 3.2 Small、Gemma 3、Qwen 3 等拥有强大智能的新一代模型。
这背后,正是现代量化技术的快速成熟:
GPTQ、AWQ、乃至 3bit group-wise quantization 等量化方式,如今都已非常稳定。在推理任务中精度损失极小,却能带来成倍的资源节省。
在 Hacker News 上,一位网友犀利指出了当前“Scaling 叙事”的局限:
我认为我们严重低估了现有硬件在这个领域的潜力。
我担心,“痛苦教训(bitter lesson)” 和“计算效率边界”的叙事,把很多聪明人引导到了追求规模的方向,而忽视了探索革命性新方法。现在的模型其实非常低效。
我们可以在训练后大幅压缩权重的精度,模型依然能跑,比如生成什么“骑自行车的鹈鹕图”。
 图片
图片
另一位网友补充总结了这种“默认更大更好”的惯性:
一旦你内化了“痛苦教训”——也就是“更多数据 + 更大计算 = 更好性能”这个逻辑后,你就不再思考,如何在计算受限的环境里榨出最强表现了。
 图片
图片
4.写在最后:开源模型的发展速度和质量远超预期
智谱的 GLM-4.5,再次把开源模型的能力上限推高了一大截。
如今网友们的“整活自由”,正是这波模型狂飙带来的副作用。一个网友的留言,精准地讲出了许多技术人的共同心声:
“开源模型的发展速度和质量,完全超出我预期。
还记得 ChatGPT 上线那会儿,市面上最强的开源模型不过是 GPT-J 和 GPT-NeoX,用起来很痛苦——prompt 必须写得像讲故事一样非常精细,不然模型根本不理你。
后来 LLaMA 模型‘被泄露’,一切就变了。量化模型、微调方法、LoRA、Alpaca 接踵而至。再到 Mistral、Qwen、Gemma、Deepseek、GLM、Granite……
 图片
图片
现在的开源模型,也许距离最强闭源模型还有 6 个月的差距——但别忘了,它们已经能在普通笔记本上本地运行,甚至支持微调。这一切的变化,只用了短短两年。
评论区最多的感慨就是:真没想到,2025 年我们能在笔记本上玩到这个水平的 AI。
你有尝试本地部署模型吗?
如果让你选一个任务来测试本地大模型,你会想让它做什么?欢迎在评论区聊聊~
参考链接:
1.https://news.ycombinator.com/item?id=44723316
2.https://simonwillison.net/2025/Jul/29/space-invaders/


