
本文共同第一作者为加州大学伯克利分校的博士生胡越舟与清华大学的本科生郭佳鑫,通讯作者为佐治亚理工学院的副教授赵拓。
推测解码(Speculative Decoding, SD)通过使用一个较小的草稿模型(draft model)生成候选预测,再由更大的目标模型(target model)进行验证,从而显著加速大语言模型(LLM)的推理过程。SD 的加速效果在很大程度上取决于两者之间的对齐程度。
目前,最先进的对齐方法是使用知识蒸馏(Knowledge Distillation, KD)在所有 token 上最小化 KL 散度。然而,最小化全局 KL 散度并不意味着 token 的接受率最大化。由于小模型容量受限,草稿模型往往难以完整吸收目标模型的知识,导致直接使用蒸馏方法的性能提升受限。在极限场景下,草稿模型和目标模型的巨大尺寸差异甚至可能导致训练不收敛。
为了解决这一问题,佐治亚理工、清华大学与加州大学伯克利分校的研究团队提出 AdaSPEC,一种引入选择性 token 过滤机制的创新蒸馏方法。AdaSPEC 利用参考模型(reference model)识别并过滤出难以学习的 token,使蒸馏过程更聚焦于「易学习」的部分,从而让草稿模型在有限容量下更好地对齐目标模型。
这种选择性蒸馏策略在不降低生成质量的前提下,显著提升了整体 token 接受率。我们在多个任务(算术推理、指令跟随、代码生成与文本摘要)和不同规模模型组合(31M/1.4B、350M/2.7B)上进行了系统评估。结果表明,AdaSPEC 在所有任务上均超越当前最优的 DistillSpec 方法,token 接受率最高提升达 15%。

论文标题:AdaSPEC: Selective Knowledge Distillation for Efficient Speculative Decoders
论文链接:https://arxiv.org/abs/2510.19779
Github 链接:https://github.com/yuezhouhu/adaspec
研究背景
大型语言模型(LLM)在推理和生成任务中表现卓越,但其自回归解码机制导致推理延迟高、计算开销大,成为实际部署的主要瓶颈。传统加速方法如模型压缩、量化或知识蒸馏虽能提升速度,但往往以牺牲生成质量为代价。
近年来,推测解码(Speculative Decoding, SD)提供了一条新路径:通过一个轻量级「草稿模型」并行生成多个候选 token,再由原始「主模型」批量验证,从而减少主模型的前向调用次数。理论上,SD 可在不损失生成质量的前提下显著加速推理。然而,其实际效果高度依赖草稿模型与主模型的预测一致性 —— 若草稿模型生成的候选 token 频繁被主模型拒绝,加速收益将大打折扣。
当前一种做法是使用知识蒸馏(KD)让草稿模型模仿主模型的输出分布。但草稿模型通常比主模型小一个数量级,容量有限,强行拟合所有 token(尤其是罕见或上下文敏感的「难学 token」)不仅效率低下,还可能挤占其学习「易学 token」 的能力,反而降低整体接受率。
针对这一问题,研究团队提出 AdaSPEC—— 一种面向推测解码的选择性知识蒸馏方法。AdaSPEC 的核心思想是:让草稿模型专注于学习那些它真正能掌握且对接受率贡献大的「易学 token」,主动忽略难以拟合的 token。通过两阶段训练(先识别难 token,再在蒸馏中过滤),AdaSPEC 更高效地利用草稿模型的有限容量,显著提升其与主模型的一致性。
实验表明,AdaSPEC 在多种模型和任务上 consistently 提高 token 接受率(最高提升 15%),在保持生成质量的同时,有效释放了推测解码的加速潜力。
方法概述
AdaSPEC 的核心思想是:在蒸馏阶段(如下图 1)识别并过滤难以学习的 token,让知识迁移更聚焦、更有效。
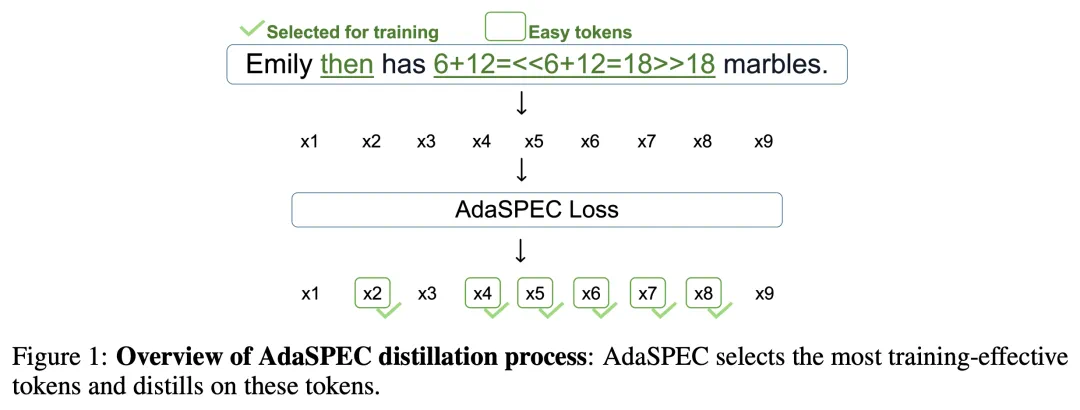
1、Selective KD 核心机制
通过引入参考模型(reference model),自动筛除训练样本中「难以对齐」的 token,仅在「易学习」子集上进行蒸馏,从根本上缓解 draft–target 不匹配问题。
2、双阶段训练框架
AdaSPEC 首先在参考模型上执行初步蒸馏,得到参考模型。随后使用参考模型过滤微调数据集,并在过滤后的子集上优化草稿模型。该方法显著减少无效学习与梯度噪声,既保持生成质量,又有效提升 token 接受率。
3、通用适配性与轻量实现
AdaSPEC 具备极高的模块化兼容性与结构清晰的设计,可无缝结合 EAGLE、vLLM 等高级推测解码框架。核心实现不到百行,思路直观、代码简洁,能直接适配任意 Transformer 架构的草稿–目标模型组合,便于研究者与开发者快速上手。
实验评估
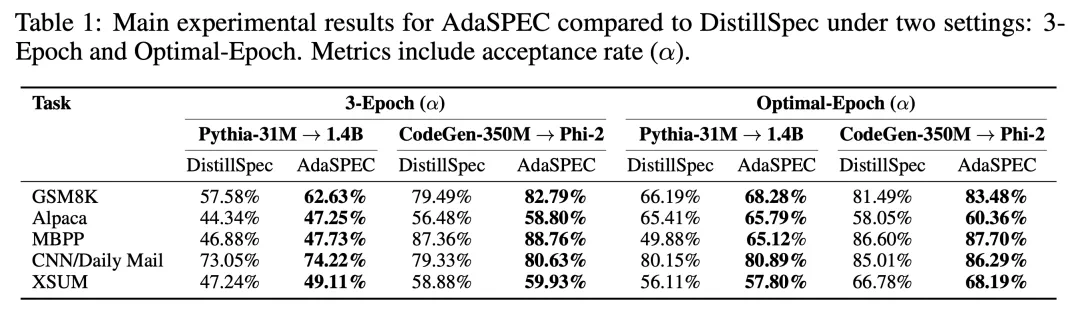
研究团队在多个模型家族(Pythia、CodeGen、Phi-2 等)和多种任务(GSM8K、Alpaca、MBPP、CNN/DailyMail、XSUM)上进行了系统验证,在不同模型规模与任务类型下均展现出一致且稳健的提升效果,体现了方法的鲁棒性与广泛适用性。主要实验结果表明:
Token 接受率全线超越基线方法 DistillSpec:在 GSM8K 上提升 5–6%,在 MBPP 上最高提升 15%。
实际加速显著:经微调后使用 vLLM 框架测速,end2end 推理速度提升可达 10–20%。
进一步兼容提升:结合 EAGLE 框架微调,生成速度再提高 7.5%。
总结与展望
AdaSPEC 为推测解码提供了一种精准、高效、通用且具有广泛适用性的加速新范式。它通过「选择性蒸馏 + 自适应过滤」实现了 draft–target 的动态对齐,为未来 LLM 高效推理的研究与工业部署开辟了新方向。
当前工作仍有两个拓展方向值得探索:
进一步研究 token 难度的动态估计机制,实现更细粒度的选择性蒸馏;
将 AdaSPEC 应用于多模态与推理型大模型中,以验证其跨模态适配能力。


